Strategies like Chain-of-Thought (CoT) prompting have enhanced reasoning by breaking complicated issues into sequential sub-steps. More moderen advances, comparable to o1-like considering modes, introduce capabilities, together with trial-and-error, backtracking, correction, and iteration, to enhance mannequin efficiency on troublesome issues. Nevertheless, these enhancements include substantial computational prices. The elevated token technology creates vital reminiscence overhead because of the Transformer structure’s limitations, the place consideration mechanism complexity grows quadratically with context size, whereas KV Cache storage will increase linearly. For example, when Qwen32B’s context size reaches 10,000 tokens, the KV Cache consumes reminiscence akin to your entire mannequin.
Present approaches to speed up LLM inference fall into three foremost classes: Quantizing Mannequin, Producing Fewer Tokens, and Lowering KV Cache. The quantizing mannequin entails each parameter and KV Cache quantization strategies. Throughout the Lowering KV Cache class, pruning-based choice in discrete house and merging-based compression in steady house emerge as key methods. Pruning-based methods implement particular eviction insurance policies to retain solely necessary tokens throughout inference. Merging-based methods introduce anchor tokens that compress traditionally necessary data. The distinction between these two strategies is that Pruning-based strategies are training-free however require making use of eviction insurance policies for each generated token, and Merging-based strategies require mannequin coaching.
Researchers from Zhejiang College, Ant Group, and Zhejiang College – Ant Group Joint Laboratory of Data Graph have proposed LightThinker to allow LLMs to compress intermediate ideas throughout reasoning dynamically. Impressed by human cognition, LightThinker compresses verbose reasoning steps into compact representations and discards unique reasoning chains, considerably decreasing the variety of tokens saved within the context window. The researchers additionally introduce the Dependency (Dep) metric to quantify compression effectiveness by measuring reliance on historic tokens throughout technology. Furthermore, the LightThinker reduces peak reminiscence utilization and inference time whereas sustaining aggressive accuracy, providing a promising course for enhancing LLM effectivity in complicated reasoning duties.
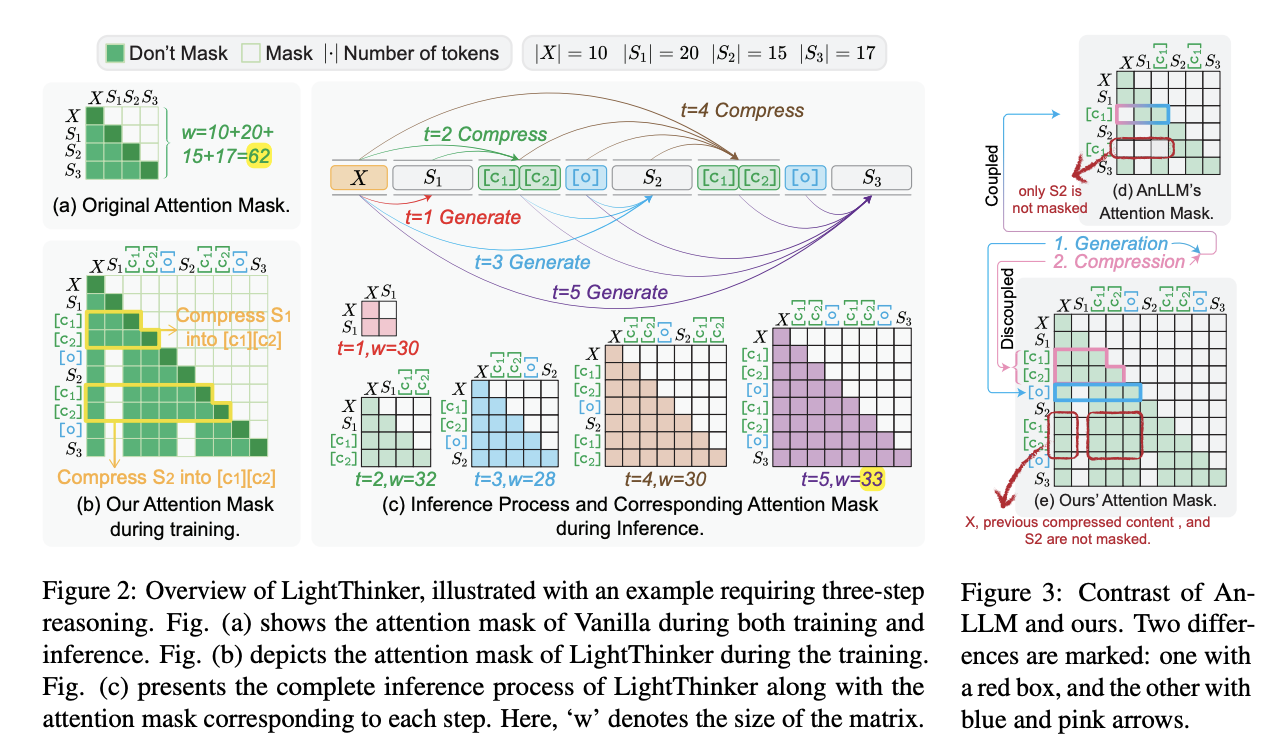
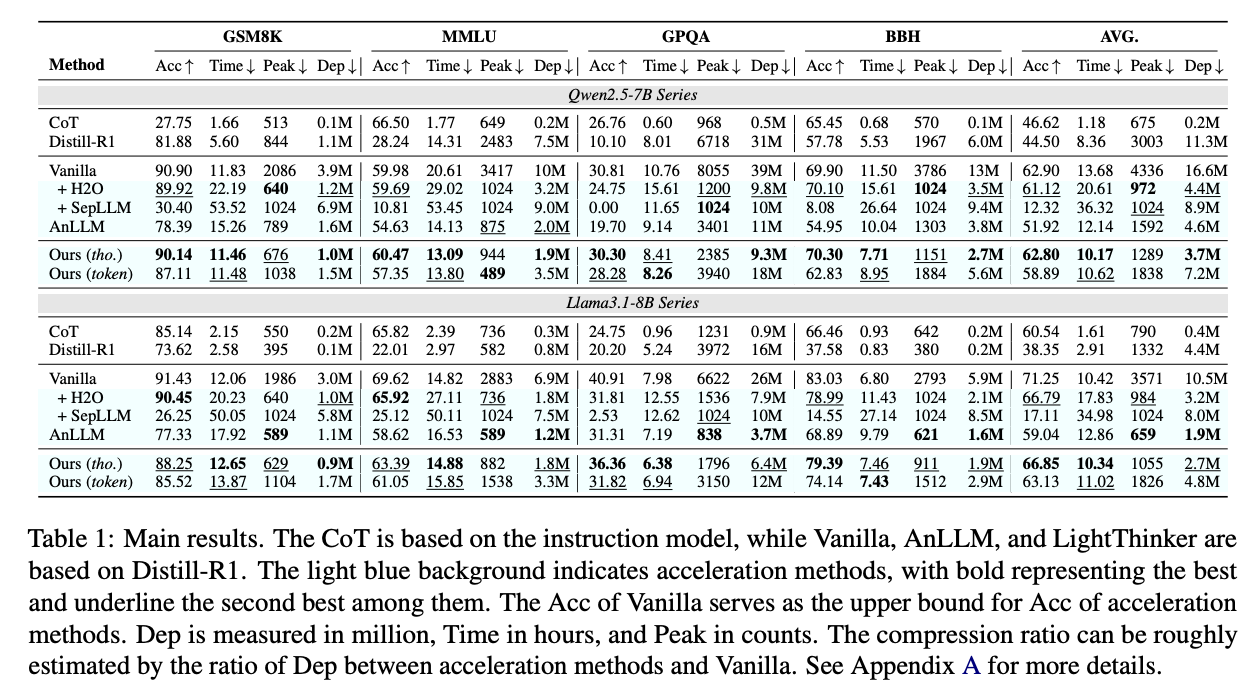
The LightThinker strategy is evaluated utilizing the Qwen2.5-7B and Llama3.1-8B fashions. The researchers performed full parameter instruction tuning utilizing the Bespoke-Stratos-17k dataset, with the ensuing mannequin designated as Vanilla. 5 comparability baselines had been applied: two training-free acceleration strategies (H2O and SepLLM), one training-based methodology (AnLLM), and CoT prompting utilized to each instruction and R1-Distill fashions. Analysis occurred throughout 4 datasets (GSM8K, MMLU, GPQA, and BBH), measuring effectiveness and effectivity (by way of inference time, peak token depend, and dependency metrics). The implementation options two compression approaches: token-level compression (changing each 6 tokens into 2) and thought-level compression (utilizing “nn” as a delimiter to section ideas).
Analysis outcomes throughout the 4 metrics for each fashions on all datasets reveal a number of vital findings. Distill-R1 persistently underperforms in comparison with CoT throughout all datasets, with the efficiency hole attributed to repetition points attributable to Grasping Decoding. H2O successfully preserves mannequin efficiency whereas decreasing reminiscence utilization, validating its grasping eviction coverage for long-text technology. Nevertheless, H2O considerably will increase inference time (51% for Qwen and 72% for Llama) as a result of its token-wise eviction coverage creating overhead for every generated token. Furthermore, LightThinker matches H2O’s efficiency with comparable compression charges whereas decreasing inference time with a 52% discount for Qwen and 41% for Llama.
On this paper, researchers launched LightThinker, a novel strategy to enhancing LLM effectivity in complicated reasoning duties by means of the dynamic compression of intermediate ideas throughout technology. By coaching fashions to study optimum timing and strategies for compressing verbose reasoning steps into compact representations, LightThinker considerably reduces reminiscence overhead and computational prices whereas sustaining aggressive accuracy. Nevertheless, a number of limitations stay: the compatibility with parameter-efficient fine-tuning strategies like LoRA or QLoRA is unexplored, the potential advantages of bigger coaching datasets are unknown, and efficiency degradation is notable on Llama sequence fashions when coaching on small datasets with next-token prediction.
Check out the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 80k+ ML SubReddit.
🚨 Really useful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Tackle Authorized Considerations in AI Datasets

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.