Automated software program engineering (ASE) has emerged as a transformative area, integrating synthetic intelligence with software program improvement processes to sort out debugging, characteristic enhancement, and upkeep challenges. ASE instruments more and more make use of giant language fashions (LLMs) to help builders, enhancing effectivity and addressing the rising complexity of software program programs. Nonetheless, most state-of-the-art instruments depend on proprietary closed-source fashions, which restrict their accessibility and adaptability, significantly for organizations with stringent privateness necessities or useful resource constraints. Regardless of current breakthroughs within the area, ASE continues to grapple with the challenges of implementing scalable, real-world options that may dynamically handle the nuanced wants of software program engineering.
One important limitation of present approaches stems from their over-reliance on static information for coaching. Whereas efficient in producing function-level options, fashions like GPT-4 and Claude 3.5 wrestle with duties that require a deep contextual understanding of project-wide dependencies or the iterative nature of real-world software program improvement. These fashions are educated totally on static codebases, failing to seize builders’ dynamic problem-solving workflows when interacting with advanced software program programs. The absence of process-level insights hampers their skill to localize faults successfully and suggest significant options. Moreover, closed-source fashions introduce information privateness issues, particularly for organizations working with delicate or proprietary codebases.
Researchers at Alibaba Group’s Tongyi Lab developed the Lingma SWE-GPT series, a set of open-source LLMs optimized for software program enchancment. The collection consists of two fashions, Lingma SWE-GPT 7B and 72B, designed to simulate real-world software program improvement processes. Not like their closed-source counterparts, these fashions are accessible, customizable, and engineered to seize the dynamic facets of software program engineering. By integrating insights from real-world code submission actions and iterative problem-solving workflows, Lingma SWE-GPT goals to shut the efficiency hole between open- and closed-source fashions whereas sustaining accessibility.
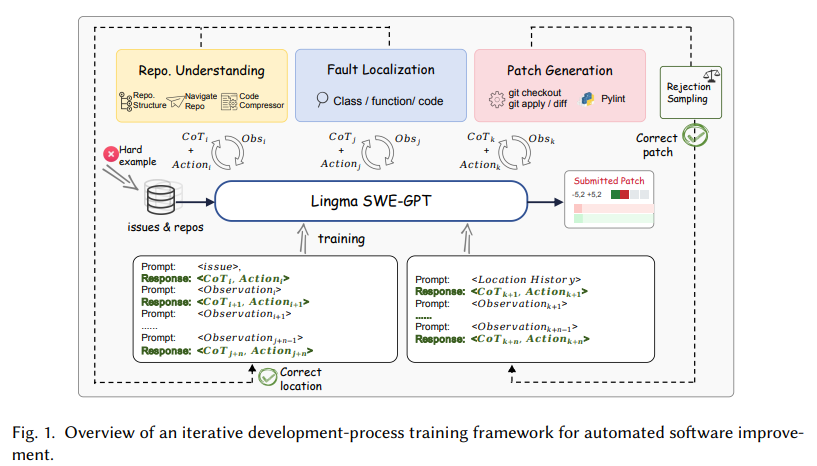
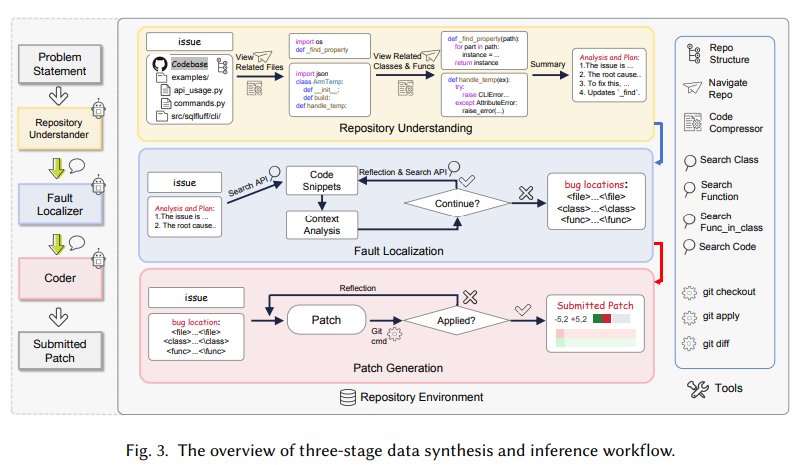
The event of Lingma SWE-GPT follows a structured three-stage methodology: repository understanding, fault localization, and patch technology. Within the first stage, the mannequin analyzes a undertaking’s repository hierarchy, extracting key structural info from directories, courses, and features to establish related recordsdata. In the course of the fault localization part, the mannequin employs iterative reasoning and specialised APIs to pinpoint problematic code snippets exactly. Lastly, the patch technology stage focuses on creating and validating fixes, utilizing git operations to make sure code integrity. The coaching course of emphasizes process-oriented information synthesis, using rejection sampling and curriculum studying to refine the mannequin iteratively and progressively deal with extra advanced duties.
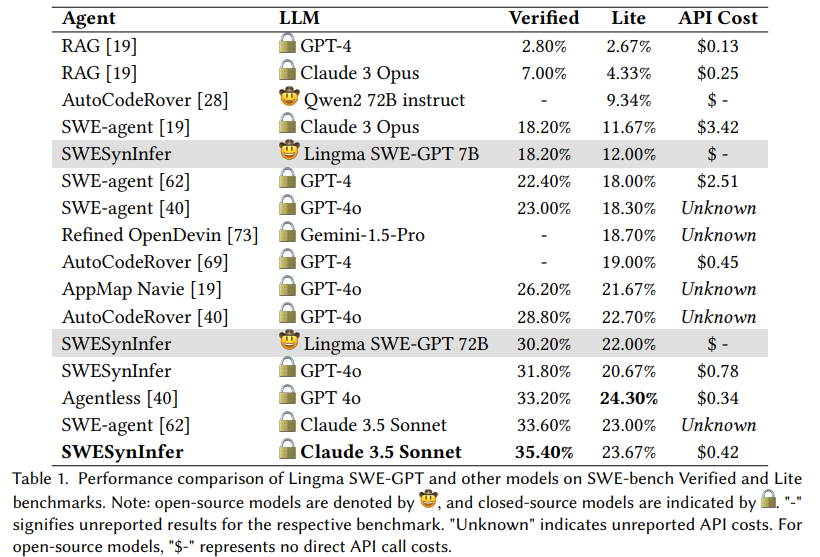
Efficiency evaluations show the effectiveness of Lingma SWE-GPT on benchmarks similar to SWE-bench Verified and SWE-bench Lite, which simulate real-world GitHub points. The Lingma SWE-GPT 72B mannequin resolved 30.20% of issues within the SWE-bench Verified dataset, a big achievement for an open-source mannequin. This efficiency approaches that of GPT-4o, which resolved 31.80% of the problems and represented a 22.76% enchancment over the open-source Llama 3.1 405B mannequin. In the meantime, the smaller Lingma SWE-GPT 7B mannequin achieved an 18.20% success price on SWE-bench Verified, outperforming Llama 3.1 70B’s 17.20%. These outcomes spotlight the potential of open-source fashions in bridging efficiency gaps whereas remaining cost-effective.
The SWE-bench evaluations additionally revealed Lingma SWE-GPT’s robustness throughout varied repositories. For example, in repositories like Django and Matplotlib, the 72B mannequin persistently outperformed its opponents, together with main open-source and closed-source fashions. Furthermore, the smaller 7B variant proved extremely environment friendly for resource-constrained situations, demonstrating the scalability of Lingma SWE-GPT’s structure. The associated fee benefit of open-source fashions additional bolsters their enchantment, as they get rid of the excessive API prices related to closed-source options. For instance, resolving the five hundred duties within the SWE-bench Verified dataset utilizing GPT-4o would value roughly $390, whereas Lingma SWE-GPT incurs no direct API prices.
The analysis additionally underscores a number of key takeaways that illustrate the broader implications of Lingma SWE-GPT’s improvement:
- Open-source accessibility: Lingma SWE-GPT fashions democratize superior ASE capabilities, making them accessible to numerous builders and organizations.
- Efficiency parity: The 72B mannequin achieves efficiency akin to state-of-the-art closed-source fashions, resolving 30.20% of points on SWE-bench Verified.
- Scalability: The 7B mannequin demonstrates sturdy efficiency in constrained environments, providing an economical resolution for organizations with restricted sources.
- Dynamic understanding: By incorporating process-oriented coaching, Lingma SWE-GPT captures software program improvement’s iterative and interactive nature, bridging gaps left by static information coaching.
- Enhanced fault localization: The mannequin’s skill to establish particular fault areas utilizing iterative reasoning and specialised APIs ensures excessive accuracy and effectivity.

In conclusion, Lingma SWE-GPT represents a big step ahead in ASE, addressing the vital limitations of static information coaching and closed-source dependency. Its revolutionary methodology and aggressive efficiency make it a compelling different for organizations looking for scalable and open-source options. By combining process-oriented insights with excessive accessibility, Lingma SWE-GPT paves the best way for broader adoption of AI-assisted instruments in software program improvement, making superior capabilities extra inclusive and cost-efficient.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.