Open-source MLLMs exhibit appreciable promise throughout numerous duties by integrating visible encoders with language fashions. Nevertheless, their reasoning talents might be improved, largely as a result of current instruction-tuning datasets typically repurposed from educational assets like VQA and AI2D. These datasets give attention to simplistic duties with phrase-based solutions and wish extra complexity for superior reasoning. CoT reasoning, confirmed efficient in text-based LLMs, affords a possible resolution however calls for the creation of datasets with detailed rationales and step-by-step reasoning. Growing such datasets at scale is difficult as a result of prices of human annotation and the restrictions of counting on proprietary instruments like GPT-4, that are costly and inaccessible for open-source tasks.
To deal with these limitations, current efforts give attention to cost-effective, scalable strategies for developing multimodal datasets solely utilizing open-source assets. Methods embody task-specific information augmentation and rigorous high quality filtering to reinforce dataset range and help nuanced reasoning duties. Whereas proprietary techniques like GPT-4 and Gemini set efficiency benchmarks, open-source initiatives like LLaVA use connector-based approaches to bridge visible encoders and language fashions. These light-weight options allow environment friendly coaching regardless of restricted assets. Nevertheless, the necessity for high-quality supervised fine-tuning information is a bottleneck. By scaling dataset high quality and adopting revolutionary coaching paradigms, open-source MLLMs goal to shut the hole with proprietary techniques, advancing aggressive multimodal capabilities.
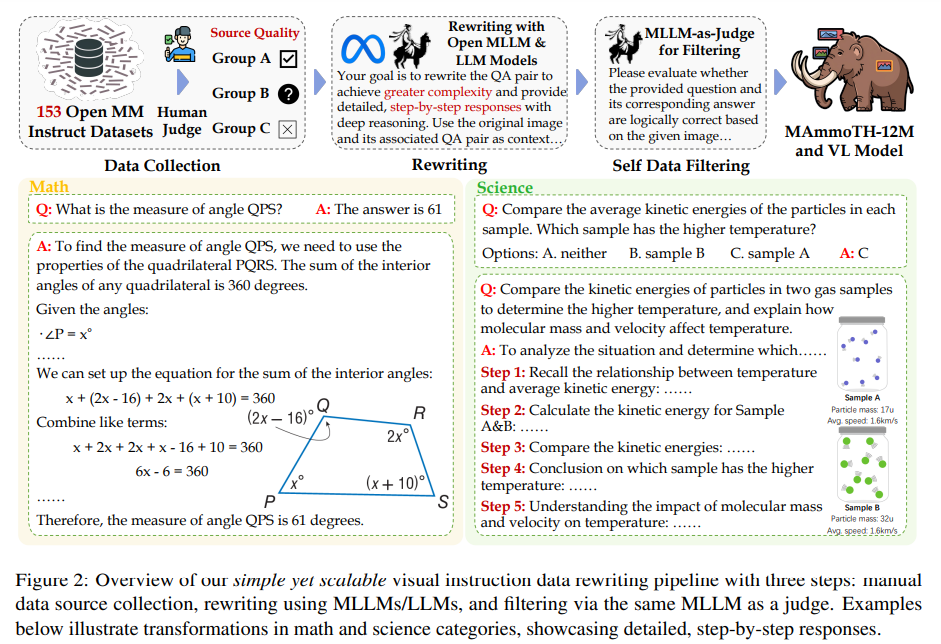
Researchers from Carnegie Mellon College, Nanyang Technological College, the College of Waterloo, and the College of Manchester developed a scalable, cost-efficient methodology to create a multimodal instruction-tuning dataset to elicit CoT reasoning. Utilizing open-weight LLMs and MLLMs, they constructed a 12-million-pair dataset specializing in reasoning-intensive duties like math problem-solving and OCR. The dataset is constructed via a three-step course of: categorizing numerous duties, augmenting them with CoT rationales, and making use of rigorous self-filtering to reinforce accuracy. Experiments with the MAmmoTH-VL-8B mannequin confirmed state-of-the-art efficiency on reasoning benchmarks like MathVerse (+8.1%), MMMU-Professional (+7%), and MuirBench (+13.3%), with enhancements on non-reasoning duties as effectively.
The researchers launched a scalable and cost-effective pipeline to generate a high-quality multimodal dataset with 12 million samples to handle the restrictions of prior visible instruction-tuning strategies. The method includes three steps: amassing and categorizing numerous open-source information, augmenting duties with rewritten instruction-response pairs utilizing open fashions, and making use of rigorous high quality filtering to take away errors and hallucinations. Information is categorized into ten main varieties, facilitating task-specific enhancements. Group B datasets had been rewritten to incorporate detailed rationales for numerous real-world situations. A “Mannequin-as-Choose” method ensured logical consistency throughout filtering, leading to a sturdy, rationale-enriched dataset appropriate for multimodal functions.
The standard of MAmmoTH-VL-Instruct was evaluated by analyzing 1,000 samples from the unique and rewritten datasets utilizing the InternVL2-Llama3-76B mannequin. Scoring on data content material and relevance (1–5 scale) revealed that rewritten information outperformed the unique, indicating enhanced depth and alignment. Token-length distribution confirmed the rewritten dataset had broader and longer textual content, bettering readability and rationalization. t-SNE evaluation confirmed the rewritten information retained core traits whereas increasing scope, growing range and complexity protection. Mannequin-based filtering, assessed in opposition to human evaluations, confirmed dependable settlement with larger consistency (Cohen’s Kappa of 0.64). Filtering additionally improved coaching outcomes, notably in visually complicated classes.
In conclusion, the examine presents an environment friendly and scalable method to enhance MLLMs by leveraging open-source fashions to create numerous, high-quality coaching datasets that seize human preferences and sophisticated real-world situations. Central to this work is the MAmmoTH-VL-Instruct dataset, comprising 12 million multimodal entries, which powers the MAmmoTH-VL8B structure. The proposed mannequin achieves state-of-the-art efficiency throughout numerous benchmarks, excelling in reasoning-intensive and sensible duties whereas decreasing reliance on proprietary techniques. By incorporating wealthy rationales and self-filtering methods, this methodology enhances MLLM reasoning capabilities, democratizing superior AI improvement and paving the best way for broader functions and additional analysis.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 [Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.