LLMs have demonstrated spectacular capabilities in answering medical questions precisely, even outperforming common human scores in some medical examinations. Nevertheless, their adoption in medical documentation duties, reminiscent of medical observe era, faces challenges because of the threat of producing incorrect or inconsistent info. Research reveal that 20% of sufferers studying medical notes recognized errors, with 40% contemplating them critical, usually associated to misdiagnoses. This raises vital issues, particularly as LLMs more and more help medical documentation duties. Whereas these fashions have proven robust efficiency in answering medical examination questions and imitating medical reasoning, they’re susceptible to producing hallucinations and probably dangerous content material, which may adversely influence medical decision-making. This highlights the crucial want for sturdy validation frameworks to make sure the accuracy and security of LLM-generated medical content material.
Latest efforts have explored benchmarks for consistency analysis normally domains, reminiscent of semantic, logical, and factual consistency, however these approaches usually fall in need of guaranteeing reliability throughout check instances. Whereas fashions like ChatGPT and GPT-4 exhibit improved reasoning and language understanding, research present they battle with logical consistency. Within the medical area, assessments of LLMs, reminiscent of ChatGPT and GPT-4, have demonstrated correct efficiency in structured medical examinations just like the USMLE. Nevertheless, limitations emerge when dealing with advanced medical queries, and LLM-generated drafts in affected person communication have proven potential dangers, together with extreme hurt if errors stay uncorrected. Regardless of developments, the shortage of publicly out there benchmarks for validating the correctness and consistency of medical texts generated by LLMs underscores the necessity for dependable, automated validation methods to deal with these challenges successfully.
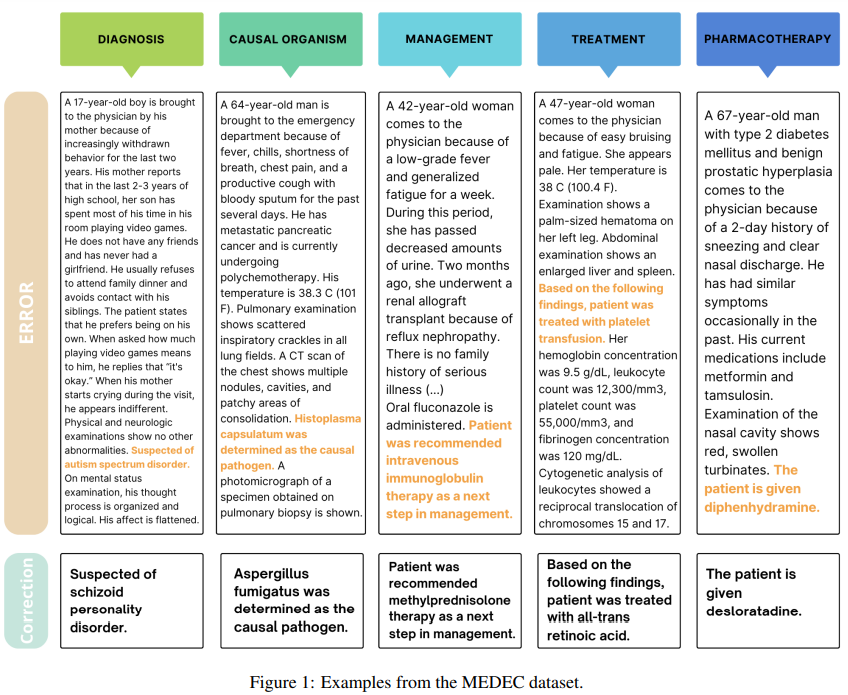
Researchers from Microsoft and the College of Washington have developed MEDEC, the primary publicly out there benchmark for detecting and correcting medical errors in medical notes. MEDEC contains 3,848 medical texts masking 5 error sorts: Prognosis, Administration, Remedy, Pharmacotherapy, and Causal Organism. Evaluations utilizing superior LLMs, reminiscent of GPT-4 and Claude 3.5 Sonnet, revealed their functionality to deal with these duties, however human medical specialists outperform them. This benchmark highlights the challenges in validating and correcting medical texts, emphasizing the necessity for fashions with sturdy medical reasoning. Insights from these experiments provide steerage for bettering future error detection methods.
The MEDEC dataset accommodates 3,848 medical texts, annotated with 5 error sorts: Prognosis, Administration, Remedy, Pharmacotherapy, and Causal Organism. Errors have been launched by leveraging medical board exams (MS) and modifying actual medical notes from College of Washington hospitals (UW). Annotators manually created errors by injecting incorrect medical entities into the textual content whereas guaranteeing consistency with different elements of the observe. MEDEC is designed to guage fashions on error detection and correction, divided into predicting errors, figuring out error sentences, and producing corrections.
The experiments utilized varied small and LLMs, together with Phi-3-7B, Claude 3.5 Sonnet, Gemini 2.0 Flash, and OpenAI’s GPT-4 collection, to guage their efficiency on medical error detection and correction duties. These fashions have been examined on subtasks reminiscent of figuring out errors, pinpointing inaccurate sentences, and producing corrections. Metrics like accuracy, recall, ROUGE-1, BLEURT, and BERTScore have been employed to evaluate their capabilities, alongside an mixture rating combining these metrics for correction high quality. Claude 3.5 Sonnet achieved the very best accuracy in detecting error flags (70.16%) and sentences (65.62%), whereas o1-preview excelled in error correction with an mixture rating of 0.698. Comparisons with knowledgeable medical annotations highlighted that whereas LLMs carried out effectively, they have been nonetheless surpassed by medical medical doctors in detection and correction duties.
The efficiency hole is probably going because of the restricted availability of error-specific medical information in LLM pretraining and the problem of analyzing pre-existing medical texts relatively than producing responses. Among the many fashions, the o1-preview demonstrated superior recall throughout all error sorts however struggled with precision, usually overestimating error occurrences in comparison with medical specialists. This precision deficit, alongside the fashions’ dependency on public datasets, resulted in a efficiency disparity throughout subsets, with fashions performing higher on public datasets (e.g., MEDEC-MS) than personal collections like MEDEC-UW.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.