Massive Language Fashions (LLMs) are extensively utilized in drugs, facilitating diagnostic decision-making, affected person sorting, medical reporting, and medical analysis workflows. Although they’re exceedingly good in managed medical testing, similar to the USA Medical Licensing Examination (USMLE), their utility for real-world makes use of continues to be not well-tested. Most current evaluations depend on artificial benchmarks that fail to replicate the complexities of medical observe. In a examine final yr, they discovered {that a} mere 5% of LLM evaluation depends on precise world affected person info, which reveals an infinite distinction between testing real-world usability and signifies a profound downside with ascertaining how reliably they perform in medical decision-making, due to this fact additionally questioning security and effectiveness to be used in actual-world medical settings.
State-of-the-art analysis strategies principally rating language fashions with artificial datasets, structured data exams, and formal medical exams. Though these examinations take a look at theoretical data, they don’t replicate actual affected person eventualities with advanced interactions. Most exams produce single metric outcomes, with out consideration to crucial particulars similar to correctness of details, medical applicability, and probability of response bias. Moreover, extensively used public datasets are homogenous, compromising the generalization throughout totally different medical specialties and populations of sufferers. One other main setback is that the majority fashions skilled towards these benchmarks exhibit overfitting to check paradigms and due to this fact lose a lot of their efficiency in dynamic healthcare environments. An absence of whole-system frameworks embracing real-world affected person interactions erodes confidence even additional in using them for sensible medical use.
Researchers developed MedHELM, a radical analysis framework designed to check LLMs towards actual medical duties, multi-metric evaluation, and expert-revised benchmarks to handle these gaps. It builds upon Stanford’s Holistic Analysis of Language Fashions (HELM) and incorporates a scientific analysis throughout 5 main areas:
- Scientific Resolution Help
- Scientific Word Technology
- Affected person Communication and Training
- Medical Analysis Help
- Administration and Workflow
A complete of twenty-two subcategories and 121 particular medical duties guarantee broad protection of crucial healthcare functions. Compared with earlier requirements, MedHELM employs precise medical information, assesses fashions each by structured and open-ended duties, and applies multi-aspect scoring paradigms. The holistic protection makes it higher able to not solely measuring the recall of information but additionally of medical applicability, reasoning precision, and normal on a regular basis sensible utility.
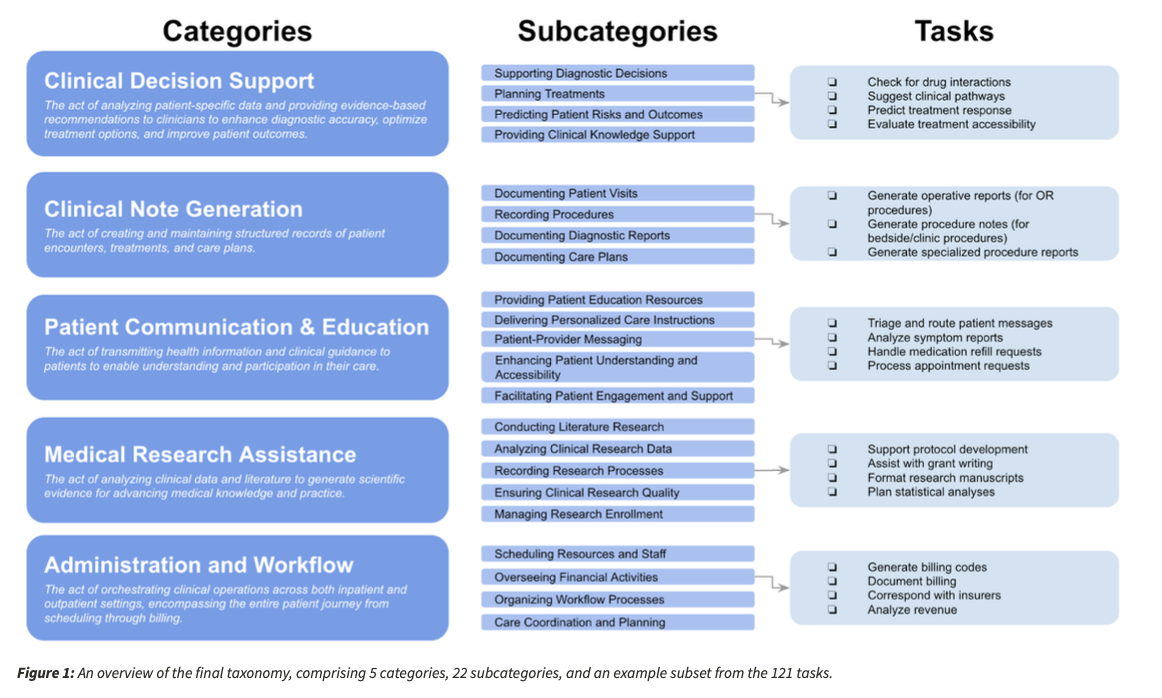
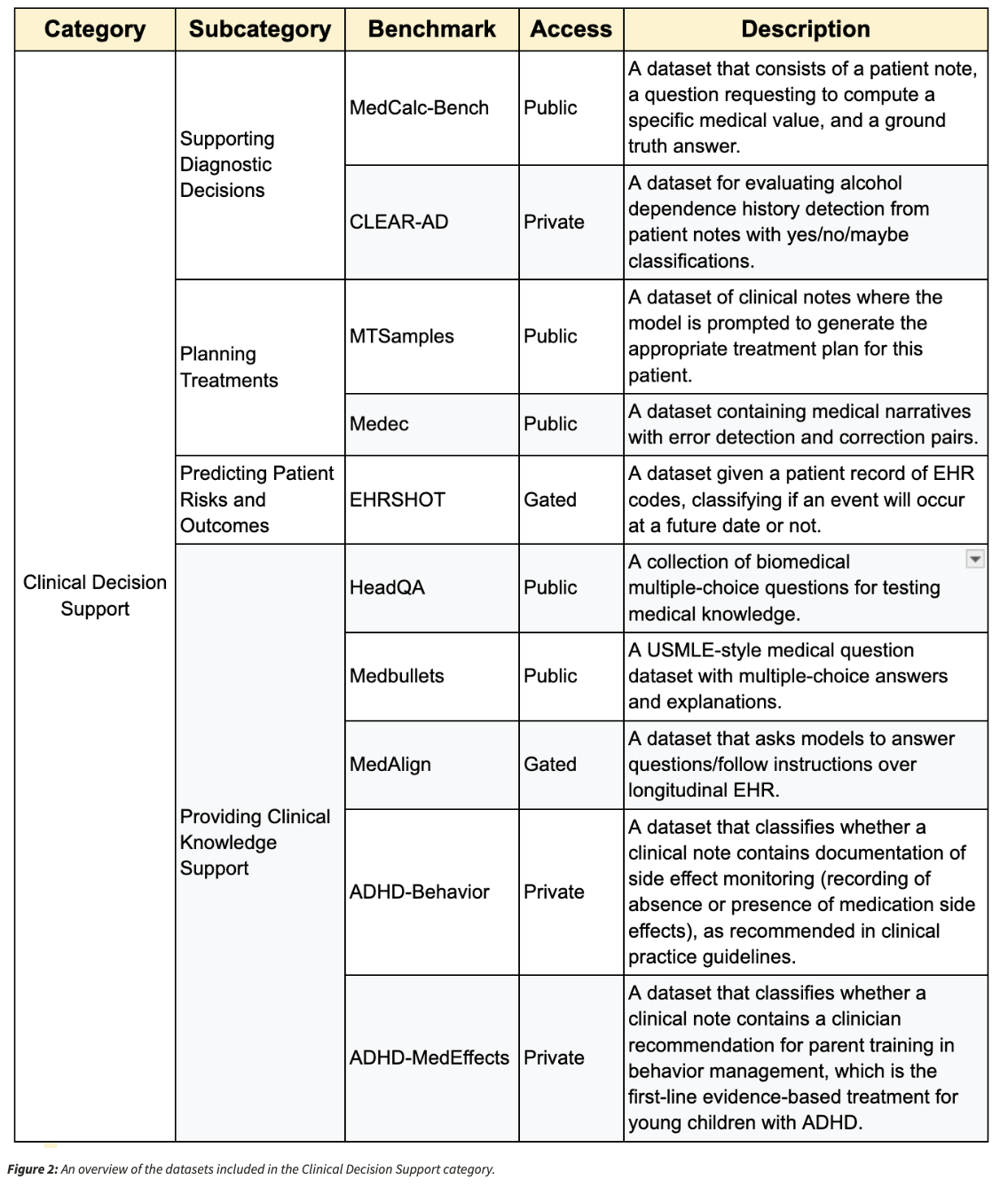
An intensive dataset infrastructure underpins the benchmarking course of, comprising a complete of 31 datasets. This assortment contains 11 newly developed medical datasets alongside 20 which were obtained from pre-existing medical information. The datasets embody numerous medical domains, thereby guaranteeing that assessments precisely symbolize real-world healthcare challenges moderately than contrived testing eventualities.
The conversion of knowledge units into standardized references is a scientific course of, which entails:
- Context Definition: The precise information section the mannequin should analyze (e.g., medical notes).
- Prompting Technique: A predefined instruction directing mannequin habits (e.g., “Decide the affected person’s HAS-BLED rating”).
- Reference Response: A clinically validated output for comparability (e.g., classification labels, numerical values, or text-based diagnoses).
- Scoring Metrics: A mix of actual match, classification accuracy, BLEU, ROUGE, and BERTScore for textual content similarity evaluations.
One instance of this strategy is in MedCalc-Bench, which exams how nicely a mannequin can execute clinically vital numerical computations. Each information enter incorporates a affected person’s medical historical past, a diagnostic query, and an answer verified by an skilled, thus enabling a rigorous take a look at of medical reasoning and precision.
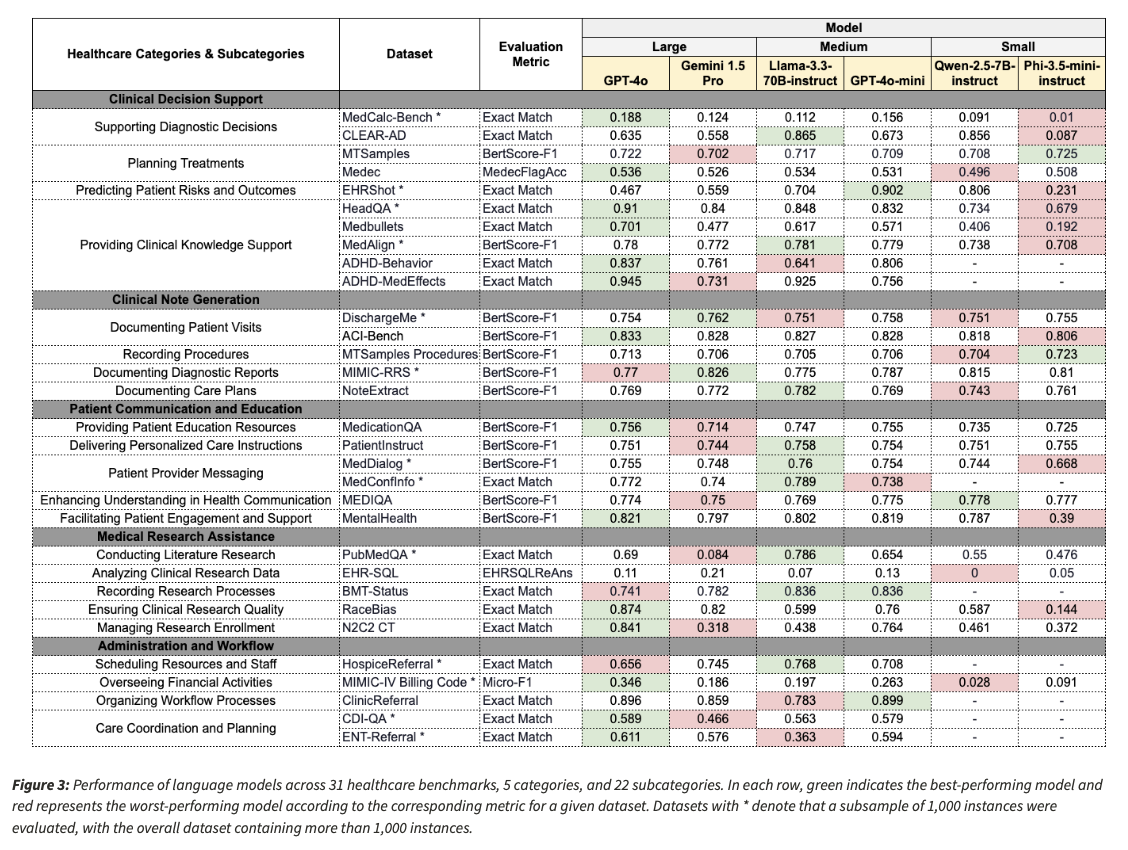
Assessments carried out on six LLMs of various sizes revealed distinct strengths and weaknesses primarily based on job complexity. Massive fashions like GPT-4o and Gemini 1.5 Professional carried out nicely in medical reasoning and computational duties and confirmed enhanced accuracy in duties like medical threat estimation and bias identification. Mid-size fashions like Llama-3.3-70B-instruct carried out competitively in predictive healthcare duties like hospital readmission threat prediction. Small fashions like Phi-3.5-mini-instruct and Qwen-2.5-7B-instruct fared poorly in domain-intensive data exams, particularly in psychological well being counseling and superior medical prognosis.
Other than accuracy, response adherence to structured questions was additionally diversified. Some fashions wouldn’t reply medically delicate questions or wouldn’t reply within the desired format, on the expense of their general efficiency. The take a look at additionally found shortcomings in present automated metrics as standard NLP scoring mechanisms tended to disregard actual medical accuracy. Within the majority of benchmarks, the efficiency disparity between fashions remained negligible when using BERTScore-F1 because the metric, which signifies that present automated analysis procedures won’t totally seize medical usability. The outcomes emphasize the need of stricter analysis procedures incorporating fact-based scoring and unambiguous clinician suggestions to make sure extra reliability in analysis.
With the appearance of a clinically guided, multi-metric evaluation framework, MedHELM provides a holistic and reliable technique of assessing language fashions within the healthcare area. Its methodology ensures that LLMs can be assessed on precise medical duties, organized reasoning exams, and diversified datasets, as an alternative of synthetic exams or truncated benchmarks. Its most important contributions are:
- A structured taxonomy of 121 real-world medical duties, enhancing the scope of AI analysis in medical settings.
- Using actual affected person information to boost mannequin assessments past theoretical data testing.
- Rigorous analysis of six state-of-the-art LLMs, figuring out strengths and areas requiring enchancment.
- A name for improved analysis methodologies, emphasizing fact-based scoring, steerability changes, and direct clinician validation.
Subsequent analysis efforts will think about the development of MedHELM by introducing extra specialised datasets, streamlining analysis processes, and implementing direct suggestions from healthcare professionals. Overcoming vital limitations in synthetic intelligence analysis, this framework establishes a strong basis for the safe, efficient, and clinically related integration of enormous language fashions into modern healthcare techniques.
Check out the Full Leaderboard, Details and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 80k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Deal with Authorized Issues in AI Datasets
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.