Giant Language Fashions (LLMs), educated on in depth datasets and geared up with billions of parameters, show exceptional skills to course of and reply to various linguistic duties. Nevertheless, as duties enhance in complexity, the interpretability and adaptableness of LLMs turn out to be important challenges. The flexibility to effectively carry out multi-step reasoning and ship clear options stays a barrier, even for state-of-the-art methods. The important thing challenge in leveraging LLMs for advanced duties is their issue breaking down implicit reasoning into express, manageable steps. Present approaches like Chain of Thought (CoT) prompting supply a partial answer by incorporating step-by-step reasoning exemplars into queries. Nevertheless, CoT depends closely on manually designed examples, that are time-consuming to create, restrict scalability, and need assistance to adapt to various or dynamic duties. This restricts their applicability in real-world problem-solving.
Present strategies have aimed to deal with these points however with various levels of success. Zero-Shot CoT prompting, for example, seeks to bypass handbook examples by guiding reasoning with prompts like “Let’s suppose step-by-step.” Equally, frameworks like Tree of Ideas and Graph of Ideas try to increase reasoning capabilities by structuring options in resolution timber or interconnected graphs. These approaches enhance reasoning processes however usually fail to generalize duties requiring implicit inferences. In addition they lack the flexibleness to tailor options to particular queries, often yielding suboptimal efficiency on intricate issues.
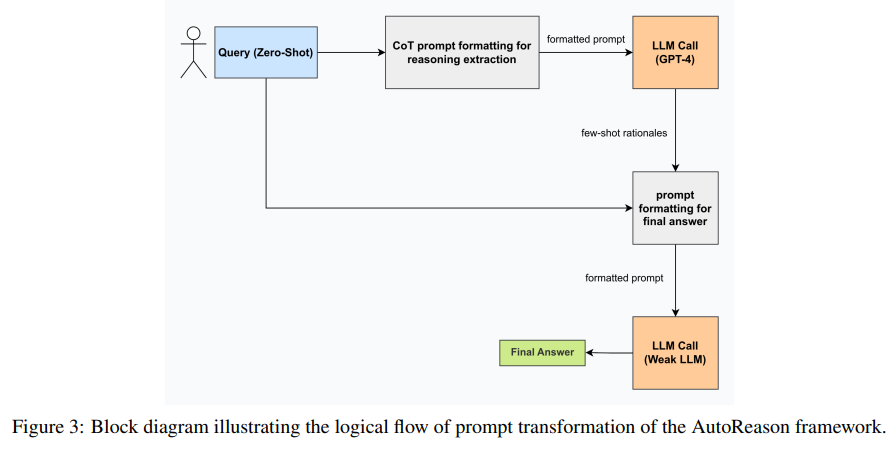
Researchers from the Izmir Institute of Expertise launched the AutoReason framework, which seeks to beat these challenges by automating the era of reasoning traces. This progressive system dynamically transforms zero-shot prompts into tailor-made few-shot reasoning steps. AutoReason employs a two-tiered methodology: A stronger mannequin, equivalent to GPT-4, generates rationales, and a relatively weaker mannequin, like GPT-3.5 Turbo, refines the output into actionable solutions. This synergy successfully bridges the hole between implicit question complexities and express step-by-step options.
The methodology underpinning AutoReason begins by reformatting person queries into prompts that elicit intermediate reasoning steps utilizing CoT methods. The generated rationales are processed by means of a separate mannequin to provide the ultimate output. For instance, the system first makes use of GPT-4 to decompose a question into express rationales, subsequently refined by GPT-3.5 Turbo. This modular course of ensures readability and interpretability and permits for improved efficiency in reasoning-intensive duties, because the completely different strengths of every mannequin are totally utilized.
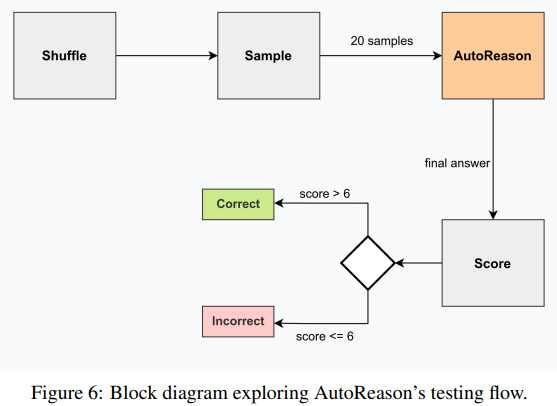
Intensive testing of AutoReason was carried out utilizing two datasets:
- StrategyQA: This dataset focuses on implicit multi-step reasoning. AutoReason achieved a 76.6% accuracy with GPT-3.5 Turbo, enhancing from the baseline accuracy of 55% and a notable enhance over the CoT efficiency of 70.3%. Equally, GPT-4 confirmed a exceptional enhance from 71.6% baseline accuracy to 91.6% when utilizing AutoReason.
- HotpotQA: This dataset emphasizes direct factual queries that produce blended outcomes. Though GPT-3.5 Turbo’s accuracy elevated from 61.6% to 76.6%, GPT-4 confirmed a slight regression from its baseline efficiency.
These findings recommend that whereas AutoReason excels in advanced reasoning, its influence on easier duties requiring direct retrieval is much less exceptional.
The broader implications of AutoReason lie in its potential to boost reasoning capabilities with out counting on manually crafted prompts. This automation lowers the entry barrier for making use of CoT methods, permitting for scalable implementation throughout numerous domains. The modular framework additionally introduces flexibility in adapting to task-specific complexities. For instance, in real-world purposes equivalent to medical diagnostics or authorized reasoning, the place interpretability and precision are important, AutoReason supplies a structured method to managing and fixing intricate issues.
The important thing contributions from this analysis on AutoReason are as follows:
- Creating a two-tier mannequin method that makes use of a stronger LLM to generate reasoning traces, successfully guiding weaker LLMs in decision-making.
- AutoReason considerably improves advanced reasoning duties, notably these involving implicit multi-step reasoning steps.
- This paper supplies insights into the interplay between superior LLMs and structured prompting strategies, together with observations on mannequin conduct and situations of efficiency regressions.
- AutoReason’s scalable and adaptable framework contributes to growing extra sturdy and interpretable AI reasoning methods.
In conclusion, the introduction of the AutoReason framework enhances reasoning capabilities inside NLP by automating rationale era and adapting to various queries. The framework demonstrates substantial enhancements in multi-step reasoning duties by automating the era of reasoning traces and tailoring them to particular queries. Whereas its efficiency in easy situations like these in HotpotQA highlights areas for additional optimization, the outcomes underscore its potential for advanced problem-solving purposes. This innovation bridges the hole between superior LLMs and sensible reasoning wants. Future analysis might discover additional integrating AutoReason with different AI strategies, equivalent to RL, to boost its adaptability and effectivity.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.