Coaching large-scale AI fashions comparable to transformers and language fashions have turn into an indispensable but extremely demanding course of in AI. With billions of parameters, these fashions provide groundbreaking capabilities however come at a steep value when it comes to computational energy, reminiscence, and power consumption. For instance, OpenAI’s GPT-3 contains 175 billion parameters and requires weeks of GPU coaching. Such huge necessities restrict these applied sciences to organizations with substantial computational assets, exacerbating issues over power effectivity and environmental influence. Addressing these challenges has turn into important to making sure the broader accessibility and sustainability of AI developments.
The inefficiencies in coaching giant fashions stem primarily from their reliance on dense matrices, which demand important reminiscence and computing energy. The restricted assist for optimized low-precision or low-rank operations in trendy GPUs additional compounds these necessities. Whereas some strategies, comparable to matrix factorization and heuristic rank discount, have been proposed to alleviate these points, their real-world applicability is constrained. As an example, GaLore permits coaching on single-batch settings however suffers from impractical runtime overhead. Equally, LTE, which adopts low-rank adapters, struggles with convergence on large-scale duties. The dearth of a way that concurrently reduces reminiscence utilization, computational value, and coaching time with out compromising efficiency has created an pressing want for modern options.
Researchers from the College at Albany SUNY, the College of California at Santa Barbara, Amazon Alexa AI, and Meta launched Computing-and Memory-Efficient coaching methodology through Rank-Adaptive tensor optimization (CoMERA), a novel framework that mixes reminiscence effectivity with computational velocity by means of rank-adaptive tensor compression. Not like conventional strategies focusing solely on compression, CoMERA adopts a multi-objective optimization strategy to stability compression ratio and mannequin accuracy. It makes use of tensorized embeddings and superior tensor-network contractions to optimize GPU utilization, lowering runtime overhead whereas sustaining strong efficiency. The framework additionally introduces CUDA Graph to attenuate kernel-launching delays throughout GPU operations, a big bottleneck in conventional tensor compression approaches.
CoMERA’s basis relies on adaptive tensor representations, which permit mannequin layers to regulate their ranks dynamically primarily based on useful resource constraints. By modifying tensor ranks, the framework achieves compression with out compromising the integrity of neural community operations. This dynamic optimization is achieved by means of a two-stage coaching course of:
- An early stage targeted on steady convergence
- A late stage that fine-tunes ranks to satisfy particular compression targets
In a six-encoder transformer mannequin, CoMERA achieved compression ratios starting from 43x in its early stage to a powerful 361x in its late-stage optimizations. Additionally, it diminished reminiscence consumption by 9x in comparison with GaLore, with 2-3x sooner coaching per epoch.
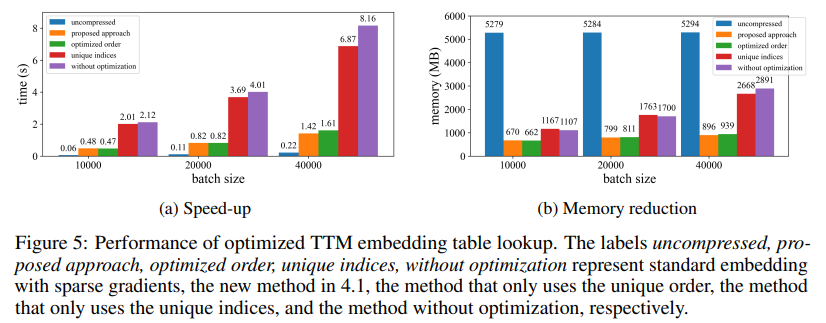
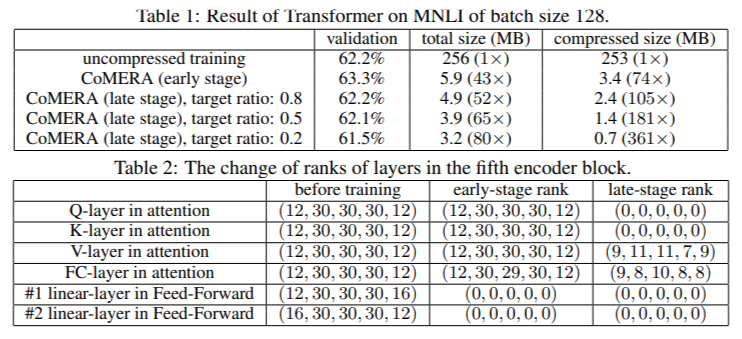
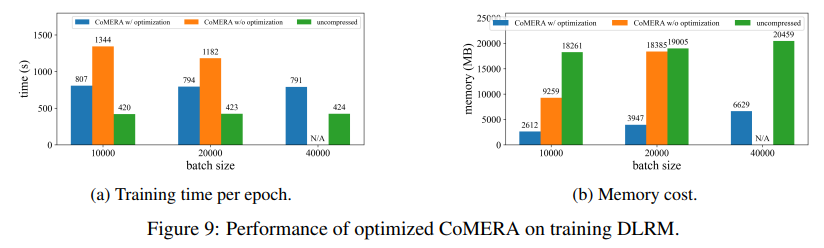
When utilized to transformer fashions educated on the MNLI dataset, CoMERA diminished mannequin sizes from 256 MB to as little as 3.2 MB whereas preserving accuracy. In large-scale suggestion techniques like DLRM, CoMERA compressed fashions by 99x and achieved a 7x discount in peak reminiscence utilization. The framework additionally excelled in pre-training CodeBERT, a domain-specific giant language mannequin, the place it gained a 4.23x general compression ratio and demonstrated a 2x speedup throughout sure coaching phases. These outcomes underscore its skill to deal with numerous duties and architectures, extending its applicability throughout domains.
The important thing takeaways from this analysis are as follows:
- CoMERA achieved compression ratios of as much as 361x for particular layers and 99x for full fashions, drastically lowering storage and reminiscence necessities.
- The framework delivered 2-3x sooner coaching occasions per epoch for transformers and suggestion techniques, saving computational assets and time.
- Utilizing tensorized representations and CUDA Graph, CoMERA diminished peak reminiscence consumption by 7x, enabling coaching on smaller GPUs.
- CoMERA’s strategy helps numerous architectures, together with transformers and huge language fashions, whereas sustaining or enhancing accuracy.
- By decreasing the power and useful resource calls for of coaching, CoMERA contributes to extra sustainable AI practices and makes cutting-edge fashions accessible to a broader viewers.
In conclusion, CoMERA addresses a number of the most vital limitations to AI scalability and accessibility by enabling sooner, memory-efficient coaching. Its adaptive optimization capabilities and compatibility with trendy {hardware} make it a compelling alternative for organizations in search of to coach giant fashions with out incurring prohibitive prices. This examine’s outcomes pave the best way for additional exploration of tensor-based optimizations in domains like distributed computing and resource-constrained edge units.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.