The sector of robotic manipulation has witnessed a outstanding transformation with the emergence of vision-language-action (VLA) fashions. These superior computational frameworks have demonstrated important potential in executing complicated manipulation duties throughout various environments. Regardless of their spectacular capabilities, VLA fashions encounter substantial challenges in generalizing throughout novel contexts, together with totally different objects, environments, and semantic situations.
The elemental limitation stems from present coaching methodologies, significantly supervised fine-tuning (SFT), which predominantly depends on behavioral imitation by means of profitable motion rollouts. This strategy restricts fashions from creating a complete understanding of activity goals and potential failure mechanisms. Consequently, the fashions usually battle to adapt to nuanced variations and unexpected situations, highlighting the essential want for extra subtle coaching methods.
Earlier analysis in robotic studying predominantly employed hierarchical planning methods, with fashions like Code as Insurance policies and EmbodiedGPT using giant language fashions and vision-language fashions to generate high-level motion plans. These approaches usually make the most of giant language fashions to create motion sequences, adopted by low-level controllers to resolve native trajectory challenges. Nevertheless, such methodologies exhibit important limitations in talent adaptability and generalization throughout on a regular basis robotic manipulation duties.
VLA fashions have pursued two main approaches to motion planning: motion house discretization and diffusion fashions. The discretization strategy, exemplified by OpenVLA, entails uniformly truncating motion areas into discrete tokens, whereas preserving autoregressive language decoding goals. Diffusion fashions, conversely, generate motion sequences by means of a number of denoising steps moderately than producing singular stepwise actions. Regardless of these structural variations, these fashions constantly depend on supervised coaching utilizing profitable motion rollouts, which essentially constrains their generalizability to novel manipulation situations.
Researchers from UNC Chapel-Hill, the College of Washington, and the College of Chicago introduce GRAPE (Generalizing Robotic Coverage by way of Choice Alignment), an modern strategy designed to deal with basic limitations in VLA mannequin coaching. GRAPE presents a sturdy trajectory-wise choice optimization (TPO) method that strategically aligns robotic insurance policies by implicitly modeling rewards from profitable and unsuccessful trial sequences. This system allows enhanced generalizability throughout various manipulation duties by shifting past conventional coaching constraints.
On the core of GRAPE’s strategy is a complicated decomposition technique that breaks complicated manipulation duties into a number of impartial phases. The tactic presents unprecedented flexibility by using a big imaginative and prescient mannequin to suggest essential keypoints for every stage and associating them with spatial-temporal constraints. These customizable constraints permit alignment with various manipulation goals, together with activity completion, robotic interplay security, and operational cost-efficiency, marking a big development in robotic coverage improvement.
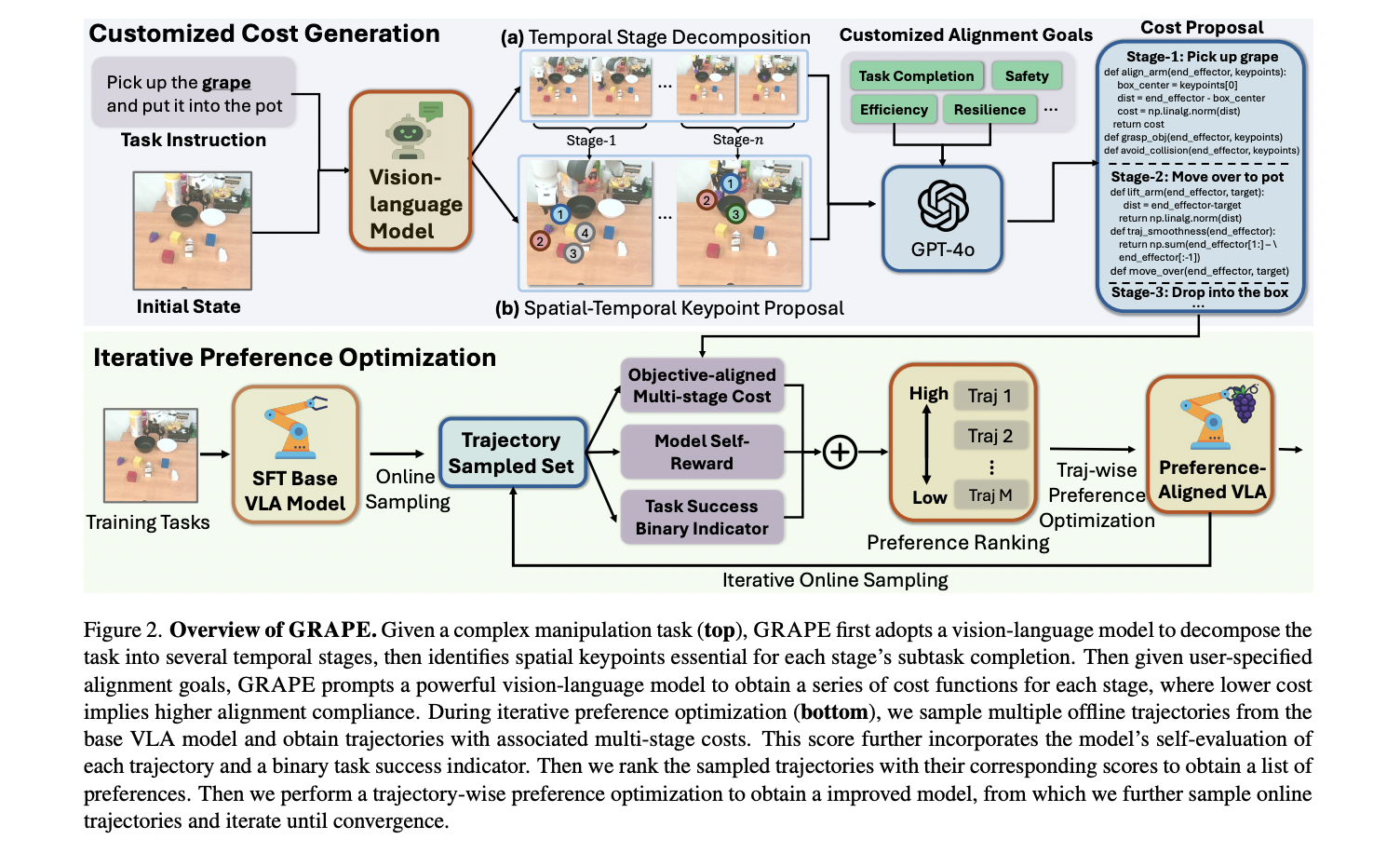
The analysis group performed complete evaluations of GRAPE throughout simulation and real-world robotic environments to validate its efficiency and generalizability. In simulation environments like Easier-Env and LIBERO, GRAPE demonstrated outstanding capabilities, outperforming current fashions Octo-SFT and OpenVLA-SFT by important margins. Particularly, in Easier-Env, GRAPE exceeded the efficiency of earlier fashions by a mean of 24.48% and 13.57%, respectively, throughout numerous generalization points together with topic, bodily, and semantic domains.
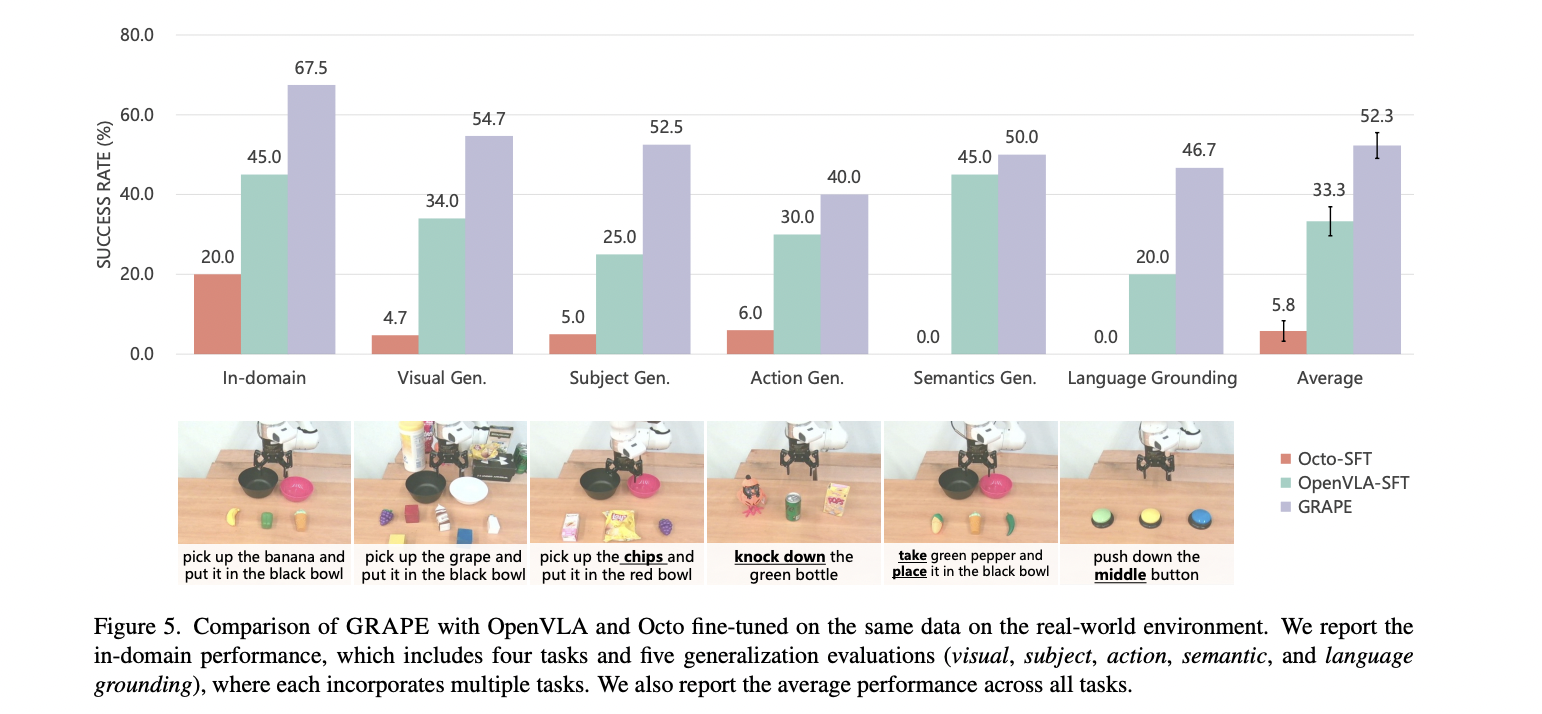
The actual-world experimental outcomes additional substantiated GRAPE’s effectiveness, with the mannequin showcasing distinctive adaptability throughout various activity situations. In in-domain duties, GRAPE achieved a 67.5% success fee, representing a considerable 22.5% enchancment over OpenVLA-SFT and dramatically surpassing Octo-SFT. Notably spectacular was GRAPE’s efficiency in difficult generalization duties, the place it maintained superior outcomes throughout visible, motion, and language grounding situations, with a formidable whole common success fee of 52.3% – a big 19% development over current approaches.
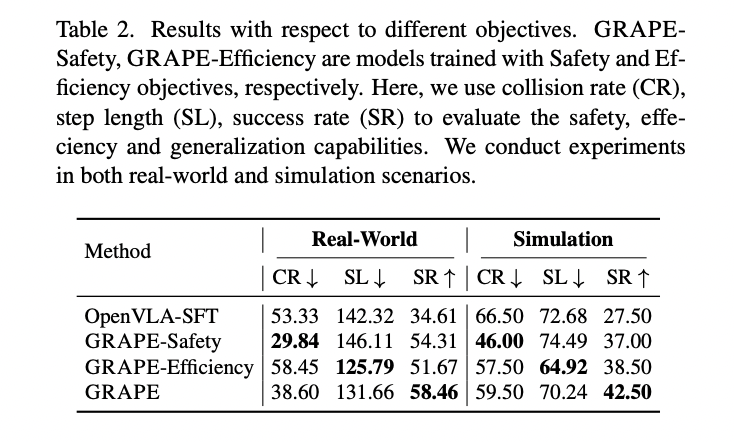
This analysis introduces GRAPE as a transformative resolution to essential challenges confronting VLA fashions, significantly their restricted generalizability and flexibility throughout manipulation duties. By implementing a novel trajectory-level coverage alignment strategy, GRAPE demonstrates outstanding functionality in studying from each profitable and unsuccessful trial sequences. The methodology presents unprecedented flexibility in aligning robotic insurance policies with various goals, together with security, effectivity, and activity completion by means of modern spatiotemporal constraint mechanisms. Experimental findings validate GRAPE’s important developments, showcasing substantial efficiency enhancements throughout in-domain and unseen activity environments.
Take a look at the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our newsletter.. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.