Giant reasoning fashions are developed to resolve tough issues by breaking them down into smaller, manageable steps and fixing every step individually. The fashions use reinforcement studying to boost their reasoning talents and develop very detailed and logical options. Nevertheless, whereas this methodology is efficient, it has its challenges. Overthinking and error in lacking or inadequate information consequence from the prolonged reasoning course of. Gaps in understanding might disrupt your complete reasoning chain, making it tougher to reach at correct conclusions.
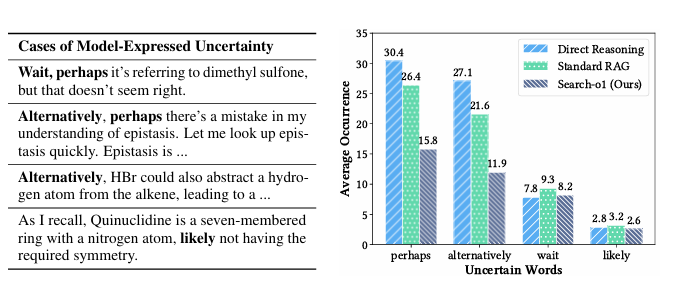
Conventional strategies in giant reasoning fashions purpose to boost efficiency by rising mannequin dimension or increasing coaching information in the course of the coaching part. Whereas test-time scaling reveals potential, present approaches rely closely on static, parameterized fashions that can’t make the most of exterior information when inside understanding is inadequate. Methods like policy-reward combos with Monte Carlo Tree Search, deliberate error integration, and information distillation enhance reasoning however fail to internalize or adapt reasoning talents totally. Retrieval-augmented technology (RAG) methods tackle some limitations by incorporating exterior information retrieval however battle to combine the sturdy reasoning capabilities seen in superior fashions. These gaps restrict the power to resolve advanced, knowledge-intensive duties successfully.

To unravel the problem of multi-step reasoning duties requiring exterior information, researchers from the Renmin College of China and Tsinghua College proposed the Search-o1 framework. The framework integrates activity directions, questions, and dynamically retrieved information paperwork right into a coherent reasoning chain to derive logical options and solutions. In contrast to conventional fashions that battle with lacking information, Search-o1 extends the retrieval-augmented technology mechanism by together with a Purpose-in-Paperwork module. This module condenses prolonged retrieved info into exact steps, making certain a logical circulate. The iterative course of continues till a whole reasoning chain and ultimate reply are fashioned.
The framework was in contrast with vanilla reasoning and fundamental retrieval-augmented strategies. Vanilla reasoning usually fails when information gaps come up, whereas fundamental augmented strategies retrieve overly detailed and redundant paperwork, disrupting reasoning coherence. The Search-o1 framework avoids these by creating searches on the fly every time required, extracting paperwork, and remodeling them into clear and associated reasoning steps. The agentic mechanism is one other feeder that ensures applicable information integration, and the Purpose-in-Paperwork proved to be coherent, therefore conserving the reasoning fairly correct and secure.
Researchers evaluated the framework on two classes of duties: difficult reasoning duties and open-domain question-answering (QA) duties. The difficult reasoning duties included GPQA, a PhD-level science multiple-choice QA dataset; mathematical benchmarks reminiscent of MATH500, AMC2023, and AIME2024; and LiveCodeBench to evaluate coding capabilities. The open-domain QA duties had been examined utilizing datasets like Pure Questions (NQ), TriviaQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle. The analysis concerned comparisons with baseline strategies, together with direct reasoning approaches, retrieval-augmented reasoning, and the Search-o1 framework proposed by the researchers. Exams had been performed below various circumstances utilizing a constant setup, which included the QwQ–32B-Preview mannequin because the spine and the Bing Internet Search API for retrieval.
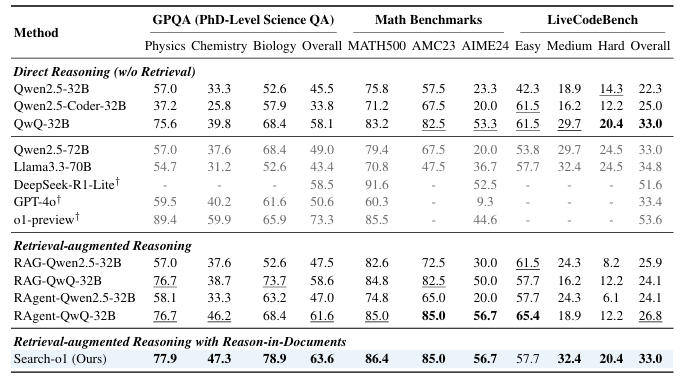
Outcomes confirmed that QwQ-32B-Preview excelled throughout reasoning duties, surpassing bigger fashions like Qwen2.5-72B and Llama3.3-70B. Search-o1 outperformed retrieval-augmented approaches like RAgent-QwQ-32B with notable coherence and information integration good points. For instance, on common, Search-o1 exceeded RAgent-QwQ-32B and QwQ-32B by 4.7% and 3.1%, respectively, and achieved a 44.7% enchancment over smaller fashions like Qwen2.5-32B. Comparisons with human specialists on the GPQA prolonged set revealed Search-o1’s superiority in integrating reasoning methods, notably in science-related duties.
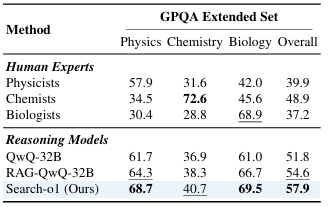
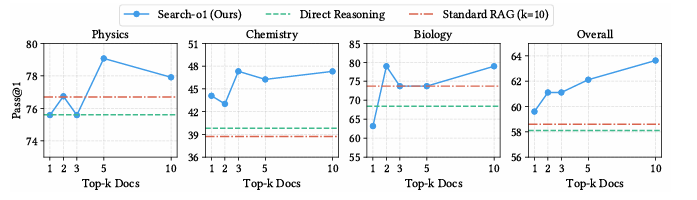
In conclusion, the proposed framework addressed the issue of information inadequacy in giant reasoning fashions by combining retrieval-augmented technology with a Purpose-in-Paperwork module to permit higher use of exterior information. This framework generally is a baseline for future analysis to boost retrieval methods, doc evaluation, and clever problem-solving throughout advanced domains.
Take a look at the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 65k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and resolve challenges.