As deep studying fashions proceed to develop, the quantization of machine studying fashions turns into important, and the necessity for efficient compression methods has turn out to be more and more related. Low-bit quantization is a technique that reduces mannequin dimension whereas trying to retain accuracy. Researchers have been figuring out the most effective bit-width for maximizing effectivity with out compromising efficiency. Numerous research have explored totally different bit-width settings, however conflicting conclusions have arisen because of the absence of a standardized analysis framework. This ongoing pursuit influences the event of large-scale synthetic intelligence fashions, figuring out their feasibility for deployment in memory-constrained environments.
A serious problem in low-bit quantization is figuring out the optimum trade-off between computational effectivity & mannequin accuracy. The talk over which bit-width is simplest stays unresolved, with some arguing that 4-bit quantization gives the most effective stability, whereas others declare that 1.58-bit fashions can obtain comparable outcomes. Nevertheless, prior analysis has lacked a unified methodology to check totally different quantization settings, resulting in inconsistent conclusions. This data hole complicates establishing dependable scaling legal guidelines in low-bit precision quantization. Furthermore, reaching steady coaching in extraordinarily low-bit settings poses a technical hurdle, as lower-bit fashions typically expertise vital representational shifts in comparison with higher-bit counterparts.
Quantization approaches fluctuate of their implementation and effectiveness. After coaching a mannequin in full precision, post-training quantization (PTQ) applies quantization, making it straightforward to deploy however vulnerable to accuracy degradation at low bit-widths. Quantization-aware coaching (QAT), then again, integrates quantization into the coaching course of, permitting fashions to adapt to low-bit representations extra successfully. Different methods, corresponding to learnable quantization and mixed-precision methods, have been explored to fine-tune the stability between accuracy and mannequin dimension. Nevertheless, these strategies lack a common framework for systematic analysis, making it troublesome to check their effectivity below totally different situations.
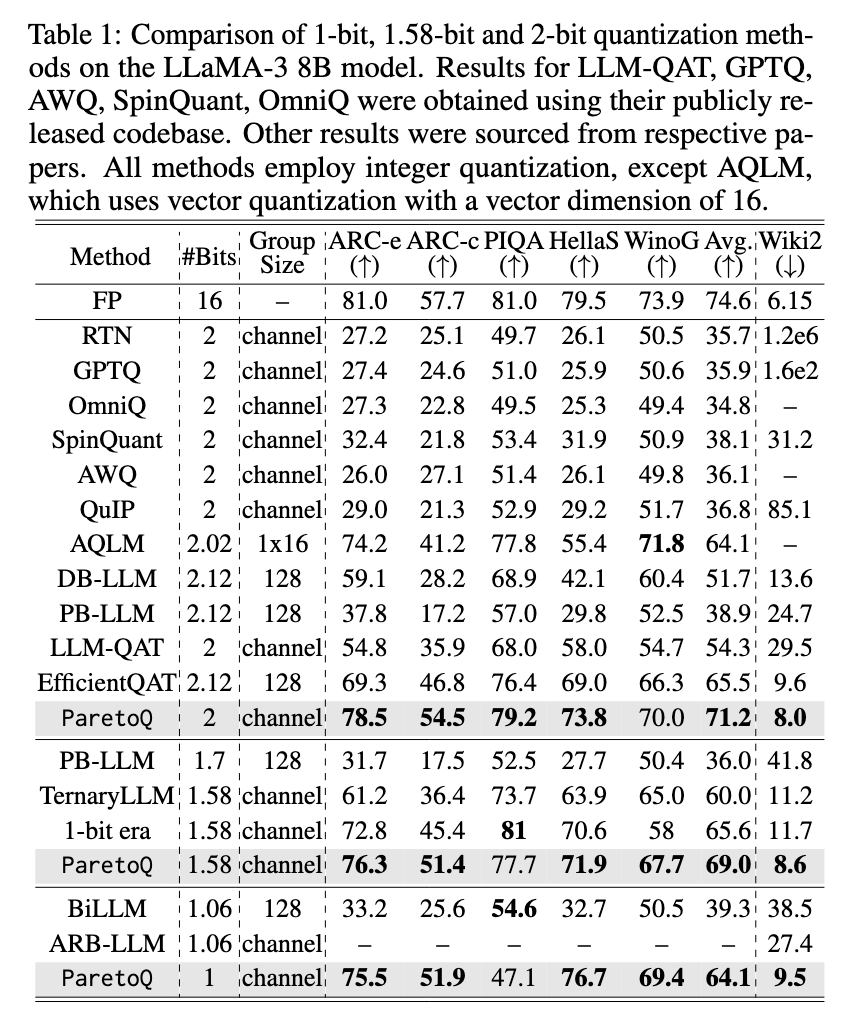
Researchers at Meta have launched ParetoQ, a structured framework designed to unify the evaluation of sub-4-bit quantization methods. This framework permits rigorous comparisons throughout totally different bit-width settings, together with 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization. By refining coaching schemes and bit-specific quantization features, ParetoQ achieves improved accuracy and effectivity over earlier methodologies. In contrast to prior works that independently optimize for particular bit ranges, ParetoQ establishes a constant analysis course of that objectively compares quantization trade-offs.
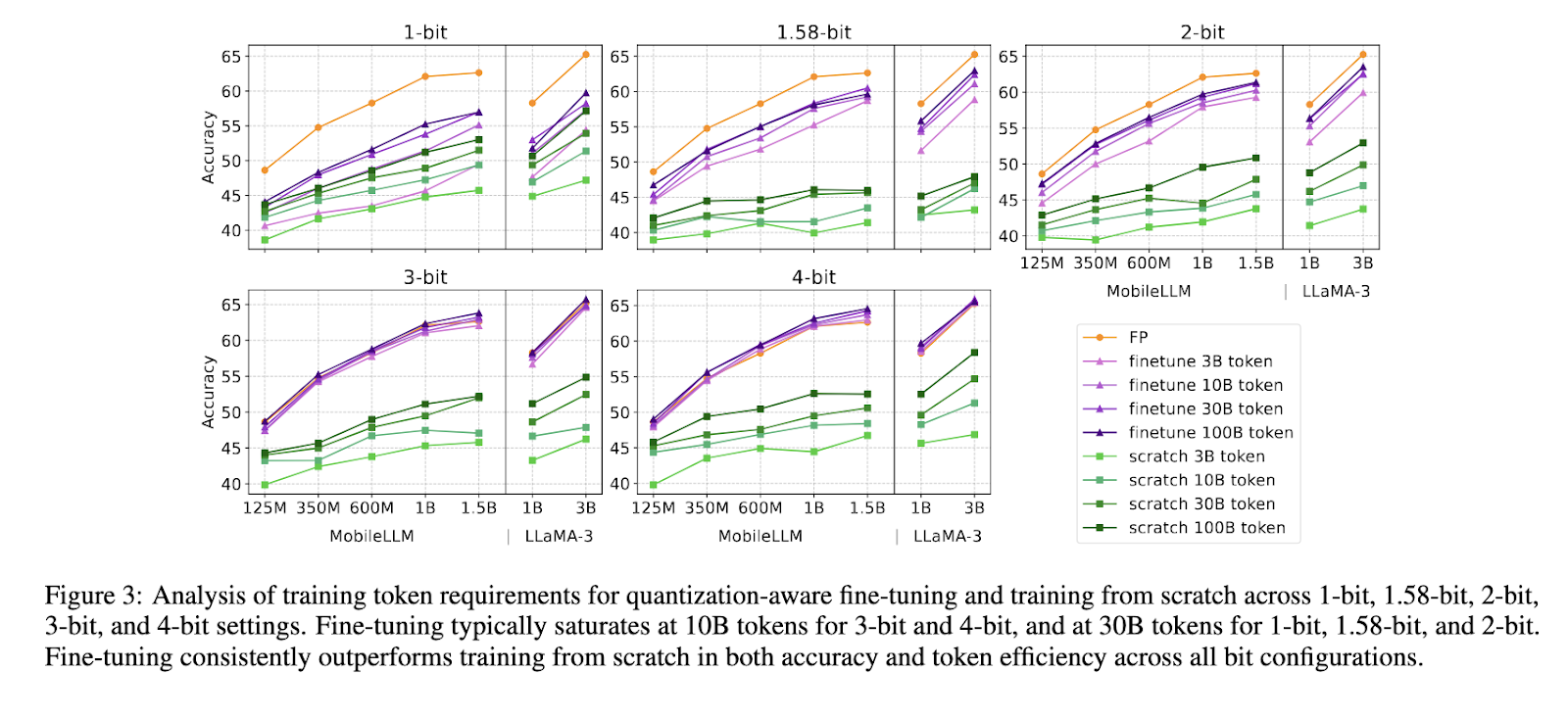
ParetoQ employs an optimized quantization-aware coaching technique to reduce accuracy loss whereas sustaining mannequin compression effectivity. The framework refines bit-specific quantization features and tailors coaching methods for every bit-width. A vital discovering from this examine is the distinct studying transition noticed between 2-bit and 3-bit quantization. Fashions educated at 3-bit precision and better keep illustration similarities with their authentic pre-trained distributions, whereas fashions educated at 2-bit or decrease expertise drastic representational shifts. To beat this problem, the framework systematically optimizes the quantization grid, coaching allocation, and bit-specific studying methods.
In depth experiments verify the superior efficiency of ParetoQ over present quantization strategies. A ternary 600M-parameter mannequin developed utilizing ParetoQ outperforms the earlier state-of-the-art ternary 3B-parameter mannequin in accuracy whereas using solely one-fifth of the parameters. The examine demonstrates that 2-bit quantization achieves an accuracy enchancment of 1.8 proportion factors over a comparable 4-bit mannequin of the identical dimension, establishing its viability as a substitute for typical 4-bit quantization. Additional, ParetoQ allows a extra hardware-friendly implementation, with optimized 2-bit CPU kernels reaching larger pace and reminiscence effectivity in comparison with 4-bit quantization. The experiments additionally reveal that ternary, 2-bit and 3-bit quantization fashions obtain higher accuracy-size trade-offs than 1-bit and 4-bit quantization, reinforcing the importance of sub-4-bit approaches.
The findings of this examine present a powerful basis for optimizing low-bit quantization in massive language fashions. By introducing a structured framework, the analysis successfully addresses the challenges of accuracy trade-offs and bit-width optimization. The outcomes point out that whereas excessive low-bit quantization is viable, 2-bit and 3-bit quantization at the moment supply the most effective stability between efficiency and effectivity. Future developments in {hardware} assist for low-bit computation will additional improve the practicality of those methods, enabling extra environment friendly deployment of large-scale machine studying fashions in resource-constrained environments.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.