
Density Useful Concept (DFT) serves as the muse of recent computational chemistry and supplies science. Nevertheless, its excessive computational price severely limits its utilization. Machine Studying Interatomic Potentials (MLIPs) have the potential to intently approximate DFT accuracy whereas considerably enhancing efficiency, lowering computation time from hours to lower than a second with O(n) versus O(n³) scaling. Nevertheless, coaching MLIPs that generalize throughout completely different chemical duties stays an open problem, as conventional strategies depend on smaller problem-specific datasets as a substitute of utilizing the scaling benefits which have pushed important advances in language and imaginative and prescient fashions.
Present makes an attempt to deal with these challenges have centered on creating Common MLIPs skilled on bigger datasets, with datasets like Alexandria and OMat24 resulting in improved efficiency on the Matbench-Discovery leaderboard. Furthermore, researchers have explored scaling relations to know relationships between compute, information, and mannequin measurement, taking inspiration from empirical scaling legal guidelines in LLMs that motivated coaching on extra tokens with bigger fashions for predictable efficiency enhancements. These scaling relations assist in figuring out optimum useful resource allocation between the dataset and mannequin measurement. Nevertheless, their utility to MLIPs stays restricted in comparison with the transformative influence seen in language modeling.

Researchers from FAIR at Meta and Carnegie Mellon College have proposed a household of Common Fashions for Atoms (UMA) designed to check the bounds of accuracy, pace, and generalization for a single mannequin throughout chemistry and supplies science. To handle these challenges, Furthermore, they developed empirical scaling legal guidelines relating compute, information, and mannequin measurement to find out optimum mannequin sizing and coaching methods. This helped in overcoming the problem of balancing accuracy and effectivity, which was because of the unprecedented dataset of ~500 million atomic programs. Furthermore, UMA performs equally or higher than specialised fashions in each accuracy and inference pace on a variety of fabric, molecular, and catalysis benchmarks, with out fine-tuning to particular duties.
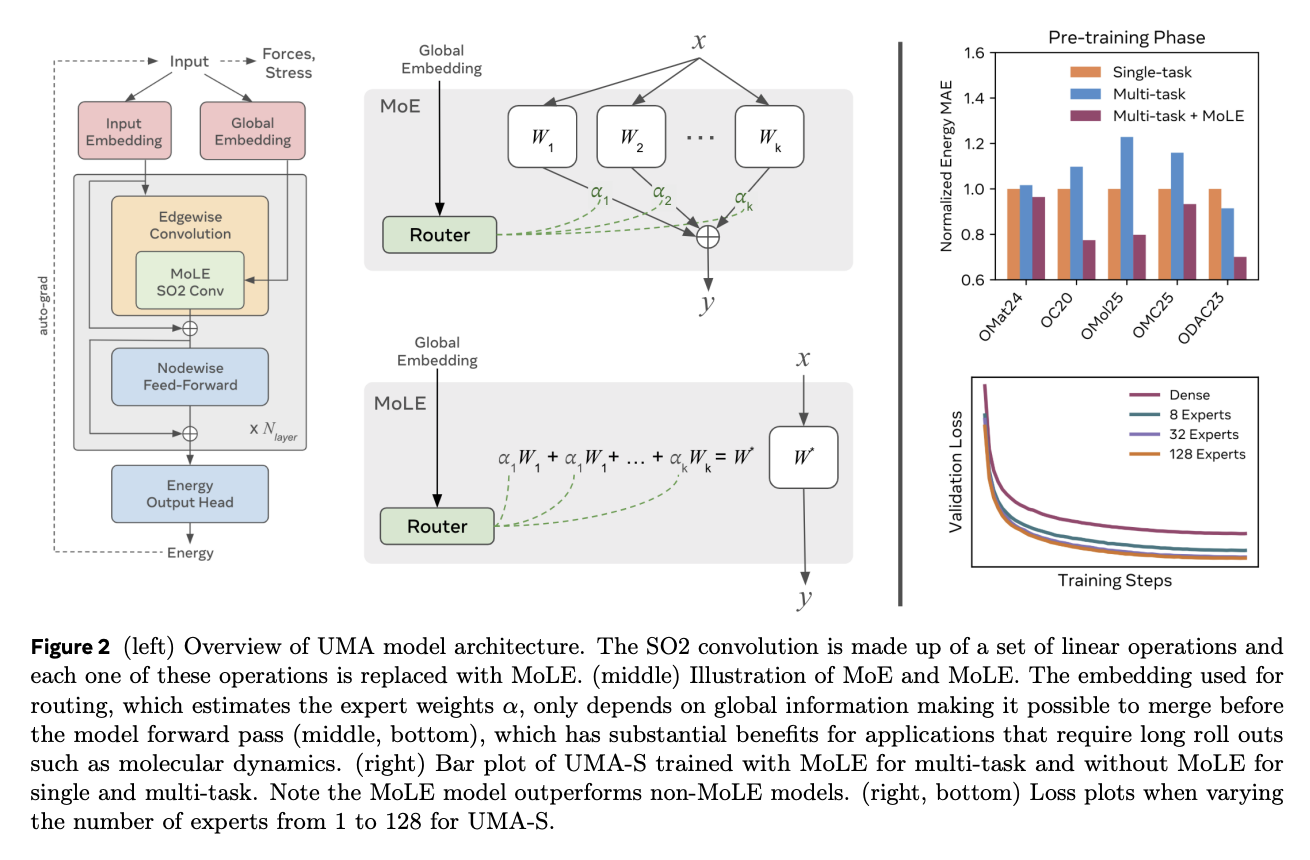
The UMA structure builds upon eSEN, an equivariant graph neural community, with essential modifications to allow environment friendly scaling and deal with extra inputs, together with complete cost, spin, and DFT settings for emulation. It additionally incorporates a brand new embedding that permits UMA fashions to combine cost, spin, and DFT-related duties. Every of those inputs generates an embedding of the identical dimension because the spherical channels used. The coaching follows a two-stage method: first stage straight predicts forces for quicker coaching, and the second stage removes the power head and fine-tunes the mannequin to foretell conserving forces and stresses utilizing auto-grad, guaranteeing vitality conservation and easy potential vitality landscapes.
The outcomes present that UMA fashions exhibit log-linear scaling habits throughout the examined FLOP ranges. This means that larger mannequin capability is required to suit the UMA dataset, with these scaling relationships used to pick out correct mannequin sizes and present MoLE’s benefits over dense architectures. In multi-task coaching, a major enchancment is noticed in loss when transferring from 1 knowledgeable to eight consultants, smaller features with 32 consultants, and negligible enhancements at 128 consultants. Furthermore, UMA fashions display distinctive inference effectivity regardless of having giant parameter counts, with UMA-S able to simulating 1000 atoms at 16 steps per second and becoming system sizes as much as 100,000 atoms in reminiscence on a single 80GB GPU.
In conclusion, researchers launched a household of Common Fashions for Atoms (UMA) that reveals sturdy efficiency throughout a variety of benchmarks, together with supplies, molecules, catalysts, molecular crystals, and metal-organic frameworks. It achieves new state-of-the-art outcomes on established benchmarks similar to AdsorbML and Matbench Discovery. Nevertheless, it fails to deal with long-range interactions because of the commonplace 6Å cutoff distance. Furthermore, it makes use of separate embeddings for discrete cost or spin values, which limits generalization to unseen costs or spins. Future analysis goals to advance towards common MLIPs and unlock new prospects in atomic simulations, whereas highlighting the necessity for more difficult benchmarks to drive future progress.

Sajjad Ansari is a last yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the influence of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.