The examine of synthetic intelligence has witnessed transformative developments in reasoning and understanding complicated duties. Probably the most progressive developments are giant language fashions (LLMs) and multimodal giant language fashions (MLLMs). These methods can course of textual and visible knowledge, permitting them to investigate intricate duties. In contrast to conventional approaches that base their reasoning abilities on verbal means, multimodal methods try to mimic human cognition by combining textual reasoning with visible pondering and, due to this fact, may very well be used extra successfully to unravel extra various challenges.
The issue to date is that these fashions can’t interlink textual and visible reasoning collectively in dynamic environments. Fashions developed for reasoning carry out effectively on text-based or image-based inputs however can’t execute concurrently when each are enter. Spatial reasoning duties like maze navigation or the interpretation of dynamic layouts present weaknesses in these fashions. Built-in reasoning capabilities can’t be catered to inside these fashions. Thus, it creates limitations within the fashions’ adaptability and interpretability, particularly the place the duty is to know and manipulate visible patterns and the directions given in phrases.
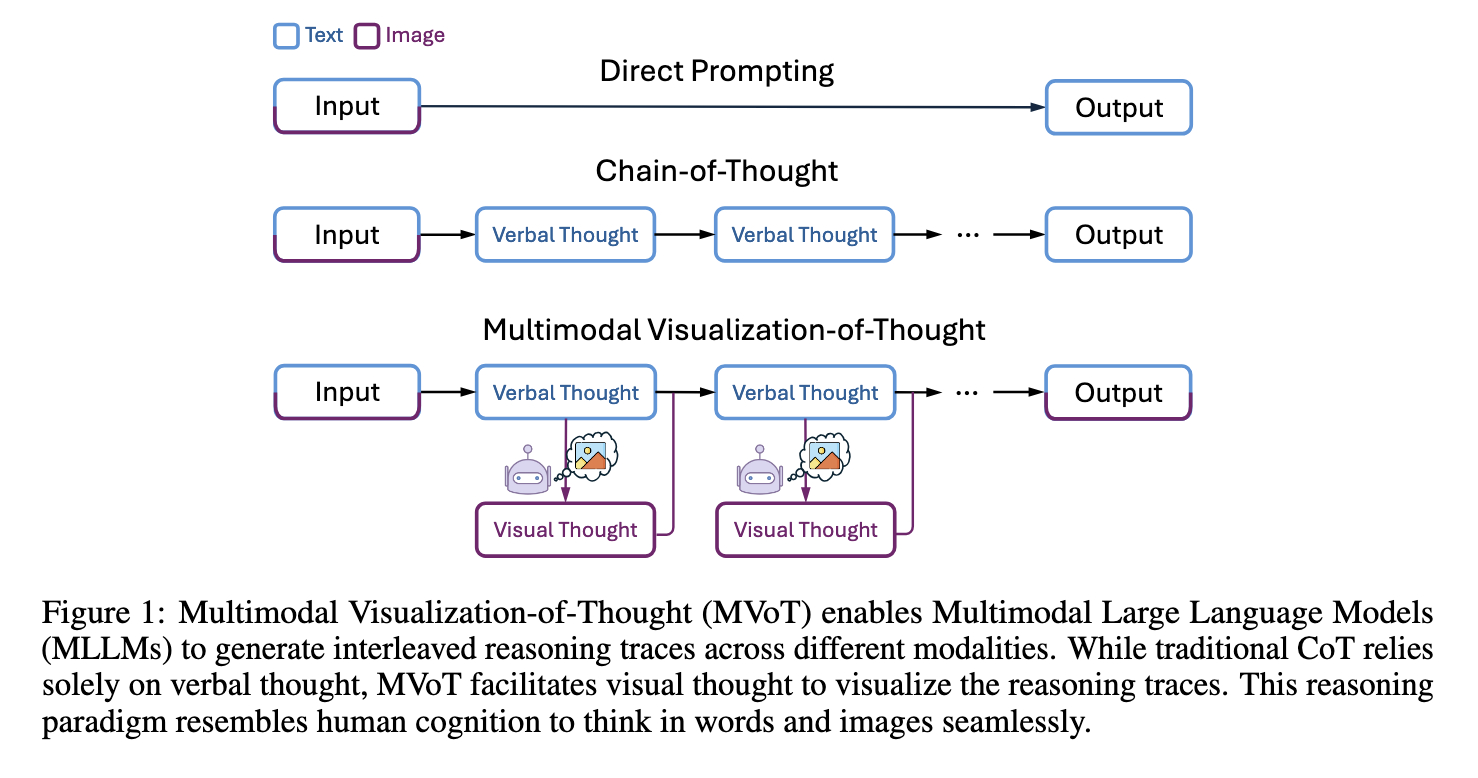
A number of approaches have been proposed to cope with these points. Chain-of-thought (CoT) prompting improves reasoning by producing step-by-step textual traces. It’s inherently text-based and doesn’t deal with duties requiring spatial understanding. Different approaches are visible enter strategies by exterior instruments resembling picture captioning or scene graph era, permitting fashions to course of visible and textual knowledge. Whereas efficient to some extent, these strategies rely closely on separate visible modules, making them much less versatile and liable to errors in complicated duties.
Researchers from Microsoft Analysis, the College of Cambridge, and the Chinese language Academy of Sciences launched the Multimodal Visualization-of-Thought (MVoT) framework to handle these limitations. This novel reasoning paradigm allows fashions to generate visible reasoning traces interleaved with verbal ones, providing an built-in strategy to multimodal reasoning. MVoT embeds visible pondering capabilities immediately into the mannequin’s structure, thus eliminating the dependency on exterior instruments making it a extra cohesive resolution for complicated reasoning duties.

Utilizing Chameleon-7B, an autoregressive MLLM fine-tuned for multimodal reasoning duties, the researchers carried out MVoT. This technique entails token discrepancy loss to shut the representational hole between textual content and picture tokenization processes for outputting high quality visuals. MVoT processes multimodal inputs step-by-step by creating verbal and visible reasoning traces. As an example, in spatial duties resembling maze navigation, the mannequin produces intermediate visualizations similar to the reasoning steps, enhancing each its interpretability and efficiency. This native visible reasoning functionality, built-in into the framework, makes it extra just like human cognition, thus offering a extra intuitive strategy to understanding and fixing complicated duties.
MVoT outperformed the state-of-the-art fashions in intensive experiments on a number of spatial reasoning duties, together with MAZE, MINI BEHAVIOR, and FROZEN LAKE. The framework reached a excessive accuracy of 92.95% on maze navigation duties, which surpasses conventional CoT strategies. Within the MINI BEHAVIOR activity that requires understanding interplay with spatial layouts, MVoT reached an accuracy of 95.14%, demonstrating its applicability in dynamic environments. Within the FROZEN LAKE activity, which is well-known for being complicated as a consequence of fine-grained spatial particulars, MVoT’s robustness reached an accuracy of 85.60%, surpassing CoT and different baselines. MVoT persistently improved in difficult situations, particularly these involving intricate visible patterns and spatial reasoning.
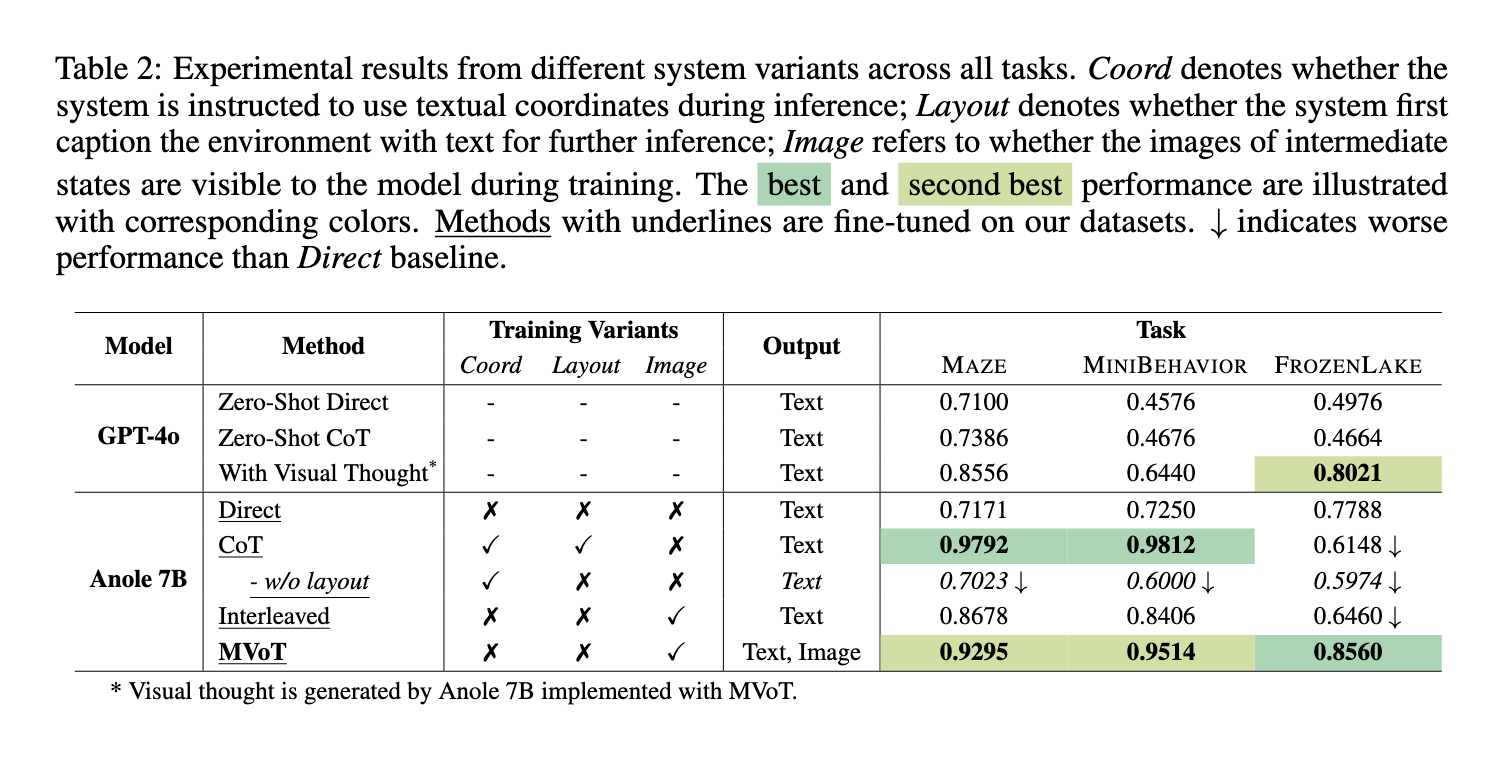
Along with efficiency metrics, MVoT confirmed improved interpretability by producing visible thought traces that complement verbal reasoning. This functionality allowed customers to comply with the mannequin’s reasoning course of visually, making it simpler to know and confirm its conclusions. In contrast to CoT, based mostly solely on the textual description, MVoT’s multimodal reasoning strategy lowered errors attributable to poor textual illustration. For instance, within the FROZEN LAKE activity, MVoT sustained steady efficiency at elevated complexity regarding its setting, thereby demonstrating robustness and reliability.

This examine, due to this fact, redefines the scope of reasoning capabilities of synthetic intelligence with MVoT by integrating textual content and imaginative and prescient into reasoning duties. Utilizing token discrepancy loss ensures visible reasoning aligns seamlessly with textual processing. This may bridge the important hole in present strategies. Superior efficiency and higher interpretability will mark MVoT as a landmark step towards multimodal reasoning that may open doorways to extra complicated and difficult AI methods in real-world situations.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 65k+ ML SubReddit.
🚨 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.