Transformer fashions have remodeled language modeling by enabling large-scale textual content technology with emergent properties. Nevertheless, they battle with duties that require intensive planning. Researchers have explored modifications in structure, targets, and algorithms to enhance their potential to attain targets. Some approaches transfer past conventional left-to-right sequence modeling by incorporating bidirectional context, as seen in fashions skilled on previous and future data. Others try to optimize the technology order, reminiscent of latent-variable modeling or binary tree-based decoding, although left-to-right autoregressive strategies typically stay superior. A more moderen strategy includes collectively coaching a transformer for ahead and backward decoding, enhancing the mannequin’s potential to take care of compact perception states.
Additional analysis has explored predicting a number of tokens concurrently to enhance effectivity. Some fashions have been designed to generate multiple token at a time, resulting in quicker and extra strong textual content technology. Pretraining on multi-token prediction has been proven to reinforce large-scale efficiency. One other key perception is that transformers encode perception states non-compactly inside their residual stream. In distinction, state-space fashions supply extra compact representations however include trade-offs. For example, sure coaching frameworks battle with particular graph constructions, revealing limitations in current methodologies. These findings spotlight ongoing efforts to refine transformer architectures for higher structured and environment friendly sequence modeling.
Researchers from Microsoft Analysis, the College of Pennsylvania, UT Austin, and the College of Alberta launched the Perception State Transformer (BST). This mannequin enhances next-token prediction by contemplating each prefix and suffix contexts. Not like commonplace transformers, BST encodes data bidirectionally, predicting the subsequent token after the prefix and the earlier token earlier than the suffix. This strategy improves efficiency on difficult duties, reminiscent of goal-conditioned textual content technology and structured prediction issues like star graphs. By studying a compact perception state, BST outperforms typical strategies in sequence modeling, providing extra environment friendly inference and stronger textual content representations, with promising implications for large-scale functions.
Not like conventional next-token prediction fashions, the BST is designed to reinforce sequence modeling by integrating each ahead and backward encoders. It makes use of a ahead encoder for prefixes and a backward encoder for suffixes, predicting the subsequent and former tokens. This strategy prevents fashions from adopting shortcut methods and improves long-term dependency studying. BST outperforms baselines in star graph navigation, the place forward-only Transformers battle. Ablations verify that the idea state goal and backward encoder are important for efficiency. Throughout inference, BST omits the backward encoder, sustaining effectivity whereas making certain goal-conditioned habits.
Not like forward-only and multi-token fashions, the BST successfully constructs a compact perception state. A perception state encodes all essential data for future predictions. The BST learns such representations by collectively modeling prefixes and suffixes, enabling goal-conditioned textual content technology. Experiments utilizing TinyStories present BST outperforms the Fill-in-the-Center (FIM) mannequin, producing extra coherent and structured narratives. Analysis with GPT-4 reveals BST’s superior storytelling potential, with clearer connections between prefix, generated textual content, and suffix. Moreover, BST excels in unconditional textual content technology by choosing sequences with high-likelihood endings, demonstrating its benefits over conventional next-token predictors.
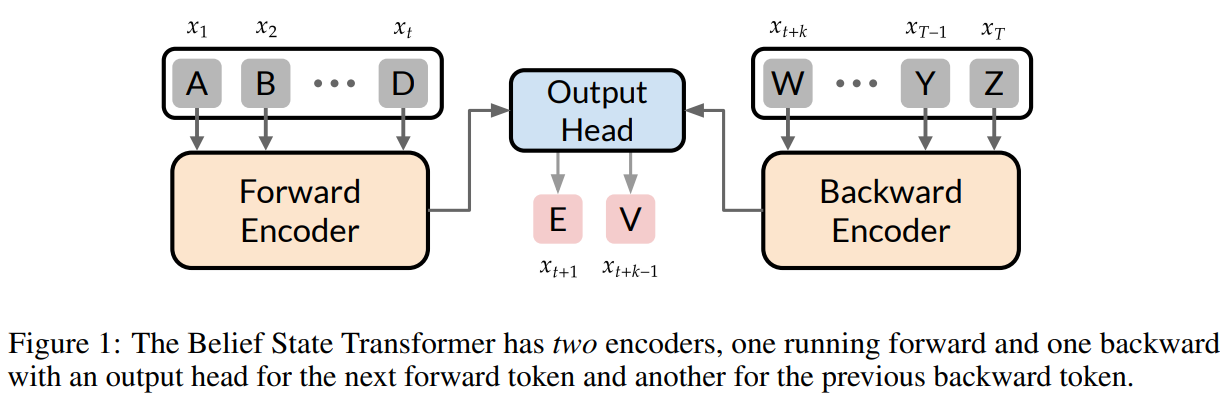
In conclusion, the BST improves goal-conditioned next-token prediction by addressing the restrictions of conventional forward-only fashions. It constructs a compact perception state, encoding all essential data for future predictions. Not like typical transformers, BST predicts the subsequent token for a prefix and the earlier token for a suffix, making it more practical in advanced duties. Empirical outcomes show its benefits in story writing, outperforming the Fill-in-the-Center strategy. Whereas our experiments validate its efficiency on small-scale duties, additional analysis is required to discover its scalability and applicability to broader goal-conditioned issues, enhancing effectivity and inference high quality.
Check out the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Tackle Authorized Issues in AI Datasets
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.