Giant Multimodal Fashions (LMMs) excel in lots of vision-language duties, however their effectiveness wants to enhance in cross-cultural contexts. It’s because they should counterbalance the bias of their coaching datasets and methodologies, stopping a wealthy array of cultural parts from being correctly represented in picture captions. Overcoming this limitation will assist to make synthetic intelligence extra strong at coping with culturally delicate duties and promote inclusivity because it will increase its applicability throughout international environments.
Single-agent LMMs, comparable to BLIP-2 and LLaVA-13b, have been the predominant instruments for picture captioning. Nonetheless, they want extra numerous coaching knowledge to include cultural depth. These fashions must seize the subtleties of a number of cultural views, and thus, the outputs seem stereotypical and unspecific. In addition to, the standard metrics of measurement, comparable to accuracy and F1 scores, don’t seize the depth of cultural illustration however as an alternative emphasize the general correctness. This methodological weak point hinders the power of those fashions to supply captions which are significant and important to completely different audiences.
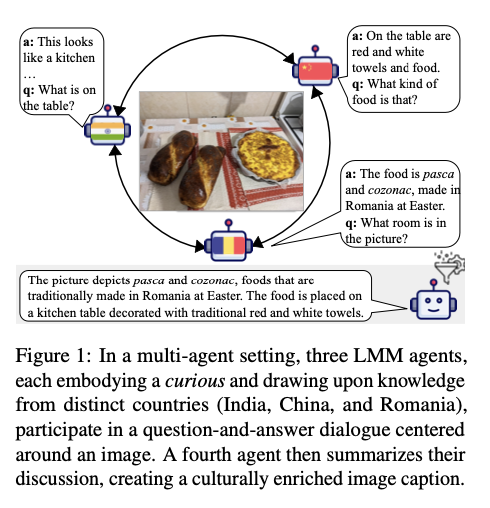
To deal with these challenges, researchers from the College of Michigan and Santa Clara College developed MosAIC, an progressive framework for enhancing cultural picture captioning via collaborative interactions. This methodology makes use of a set of a number of brokers who all have their very own particular cultural identities however participate in organized, moderated discussions between them. Their dialogue is collected and condensed by a summarizing agent right into a culturally enhanced caption. The framework makes use of a dataset of two,832 captions from three completely different cultures: China, India, and Romania, sourced from GeoDE, GD-VCR, and CVQA. It additionally makes use of an progressive culture-adaptable analysis metric to guage the illustration of cultural parts within the captions, thus offering a complete device for assessing output high quality. This units the benchmark in permitting agent-specific experience and inspiring iterative studying towards higher captions which are correct and extra culturally deep.
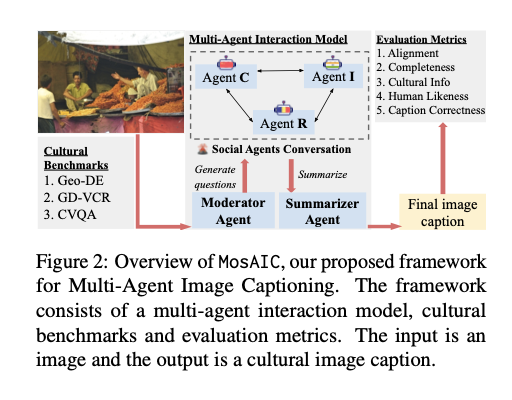
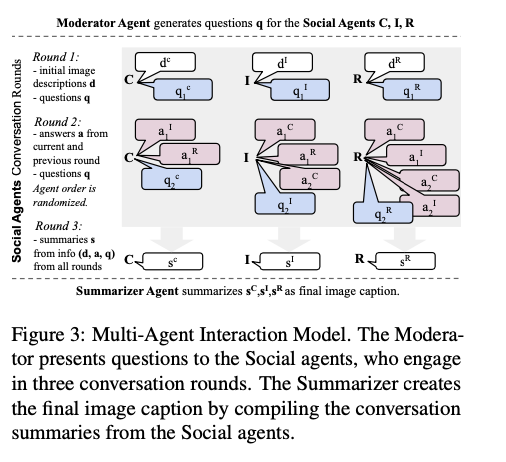
The MosAIC system operates via a multi-round interplay mechanism the place brokers first independently analyze photographs after which have interaction in collaborative discussions to refine their interpretations. As a result of every agent brings its distinctive cultural perspective into the discourse, it contributes richness to holistic picture illustration. Elaborate methodologies, together with Chain-of-Thought prompting, allow brokers to create output that’s well-structured and coherent. The mannequin contains reminiscence administration methods which are used to trace the dialogue over a number of rounds with out bias. Using geographically numerous datasets ensures that the generated captions embody numerous cultural views, thus making the framework relevant in a number of contexts.
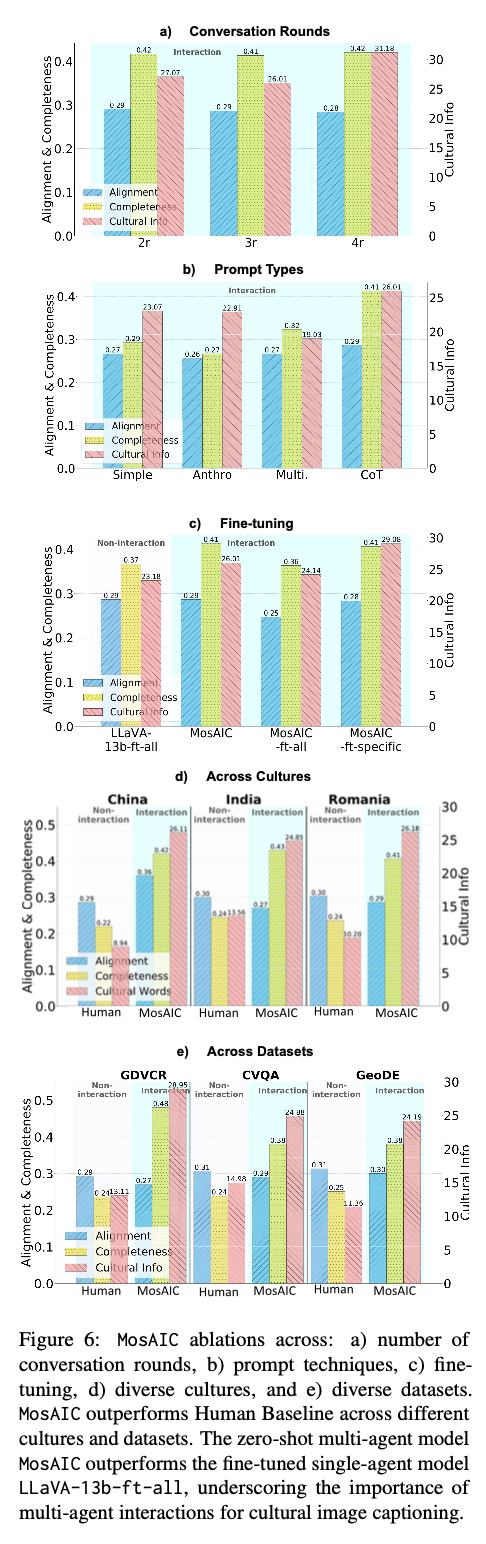
The MosAIC framework considerably outperforms single-agent fashions in producing captions which are deeper and extra culturally full. It captures numerous cultural phrases and integrates them very properly into its outputs, attaining increased scores on cultural illustration whereas remaining according to the content material of the pictures. Human evaluations additional validate its success, displaying that its captions align carefully with cultural contexts and much surpass typical fashions intimately and inclusivity. The cooperative framework that helps this technique is essential for bettering its functionality to replicate cultural nuance and represents a milestone improvement in culturally acutely aware synthetic intelligence.
MosAIC addresses the essential problem of Western-centric bias in LMMs by introducing a collaborative framework for cultural picture captioning. It achieves this via progressive interplay methods, novel datasets, and specialised analysis metrics which may be used to supply captions directly contextually correct and culturally wealthy. This work varieties a revolutionary step within the area, setting a basis for additional developments in creating inclusive and globally related AI methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.