AI-powered video era is bettering at a panoramic tempo. In a short while, we’ve gone from blurry, incoherent clips to generated movies with beautiful realism. But, for all this progress, a essential functionality has been lacking: management and Edits
Whereas producing a ravishing video is one factor, the flexibility to professionally and realistically edit it—to vary the lighting from day to nighttime, swap an object’s materials from wooden to metallic, or seamlessly insert a brand new component into the scene—has remained a formidable, largely unsolved drawback. This hole has been the important thing barrier stopping AI from changing into a very foundational device for filmmakers, designers, and creators.
Till the introduction of DiffusionRenderer!!
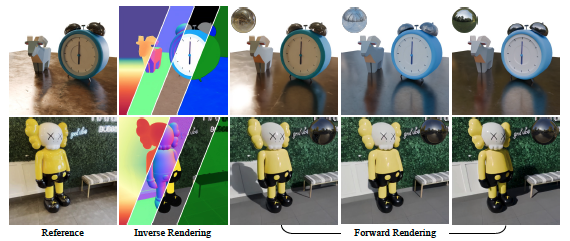
In a groundbreaking new paper, researchers at NVIDIA, University of Toronto, Vector Institute and the University of Illinois Urbana-Champaign have unveiled a framework that directly tackles this challenge. DiffusionRenderer represents a revolutionary leap ahead, shifting past mere era to supply a unified answer for understanding and manipulating 3D scenes from a single video. It successfully bridges the hole between era and enhancing, unlocking the true artistic potential of AI-driven content material.
The Outdated Method vs. The New Method: A Paradigm Shift
For many years, photorealism has been anchored in PBR, a strategy that meticulously simulates the move of sunshine. Whereas it produces beautiful outcomes, it’s a fragile system. PBR is critically depending on having an ideal digital blueprint of a scene—exact 3D geometry, detailed materials textures, and correct lighting maps. The method of capturing this blueprint from the actual world, often called inverse rendering, is notoriously troublesome and error-prone. Even small imperfections on this knowledge could cause catastrophic failures within the ultimate render, a key bottleneck that has restricted PBR’s use outdoors of managed studio environments.
Earlier neural rendering strategies like NeRFs, whereas revolutionary for creating static views, hit a wall when it got here to enhancing. They “bake” lighting and supplies into the scene, making post-capture modifications practically not possible.
DiffusionRenderer treats the “what” (the scene’s properties) and the “how” (the rendering) in a single unified framework constructed on the identical highly effective video diffusion structure that underpins fashions like Secure Video Diffusion.
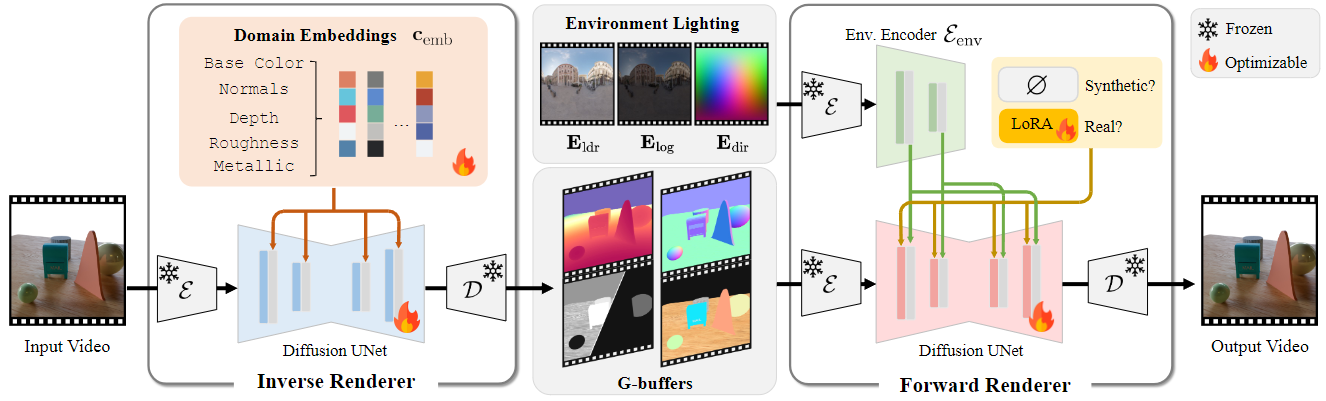
This technique makes use of two neural renderers to course of video:
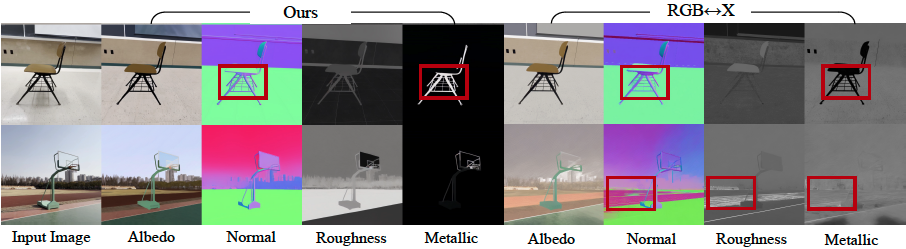
- Neural Inverse Renderer: This mannequin acts like a scene detective. It analyzes an enter RGB video and intelligently estimates the intrinsic properties, producing the important knowledge buffers (G-buffers) that describe the scene’s geometry (normals, depth) and supplies (coloration, roughness, metallic) on the pixel degree. Every attribute is generated in a devoted go to allow top quality era.
- Neural Ahead Renderer: This mannequin features because the artist. It takes the G-buffers from the inverse renderer, combines them with any desired lighting (an setting map), and synthesizes a photorealistic video. Crucially, it has been skilled to be sturdy, able to producing beautiful, complicated mild transport results like smooth shadows and inter-reflections even when the enter G-buffers from the inverse renderer are imperfect or “noisy.”
This self-correcting synergy is the core of the breakthrough. The system is designed for the messiness of the actual world, the place good knowledge is a delusion.
The Secret Sauce: A Novel Information Technique to Bridge the Actuality Hole
A sensible mannequin is nothing with out good knowledge. The researchers behind DiffusionRenderer devised an ingenious two-pronged knowledge technique to show their mannequin the nuances of each good physics and imperfect actuality.
- A Large Artificial Universe: First, they constructed an unlimited, high-quality artificial dataset of 150,000 movies. Utilizing 1000’s of 3D objects, PBR supplies, and HDR mild maps, they created complicated scenes and rendered them with an ideal path-tracing engine. This gave the inverse rendering mannequin a flawless “textbook” to study from, offering it with good ground-truth knowledge.
- Auto-Labeling the Actual World: The staff discovered that the inverse renderer, skilled solely on artificial knowledge, was surprisingly good at generalizing to actual movies. They unleashed it on a large dataset of 10,510 real-world movies (DL3DV10k). The mannequin routinely generated G-buffer labels for this real-world footage. This created a colossal, 150,000-sample dataset of actual scenes with corresponding—albeit imperfect—intrinsic property maps.
By co-training the ahead renderer on each the right artificial knowledge and the auto-labeled real-world knowledge, the mannequin realized to bridge the essential “area hole.” It realized the foundations from the artificial world and the feel and appear of the actual world. To deal with the inevitable inaccuracies within the auto-labeled knowledge, the staff integrated a LoRA (Low-Rank Adaptation) module, a intelligent method that enables the mannequin to adapt to the noisier actual knowledge with out compromising the information gained from the pristine artificial set.
State-of-the-Artwork Efficiency
The outcomes communicate for themselves. In rigorous head-to-head comparisons towards each traditional and neural state-of-the-art strategies, DiffusionRenderer persistently got here out on high throughout all evaluated duties by a large margin:
- Ahead Rendering: When producing photos from G-buffers and lighting, DiffusionRenderer considerably outperformed different neural strategies, particularly in complicated multi-object scenes the place real looking inter-reflections and shadows are essential. The neural rendering outperformed considerably different strategies.


- Inverse Rendering: The model proved superior at estimating a scene’s intrinsic properties from a video, attaining greater accuracy on albedo, materials, and regular estimation than all baselines. The usage of a video mannequin (versus a single-image mannequin) was proven to be notably efficient, decreasing errors in metallic and roughness prediction by 41% and 20% respectively, because it leverages movement to higher perceive view-dependent results.


- Relighting: Within the final check of the unified pipeline, DiffusionRenderer produced quantitatively and qualitatively superior relighting outcomes in comparison with main strategies like DiLightNet and Neural Gaffer, producing extra correct specular reflections and high-fidelity lighting.

What You Can Do With DiffusionRenderer: highly effective enhancing!
This analysis unlocks a set of sensible and highly effective enhancing purposes that function from a single, on a regular basis video. The workflow is straightforward: the mannequin first performs inverse rendering to grasp the scene, the consumer edits the properties, and the mannequin then performs ahead rendering to create a brand new photorealistic video.
- Dynamic Relighting: Change the time of day, swap out studio lights for a sundown, or utterly alter the temper of a scene by merely offering a brand new setting map. The framework realistically re-renders the video with all of the corresponding shadows and reflections.
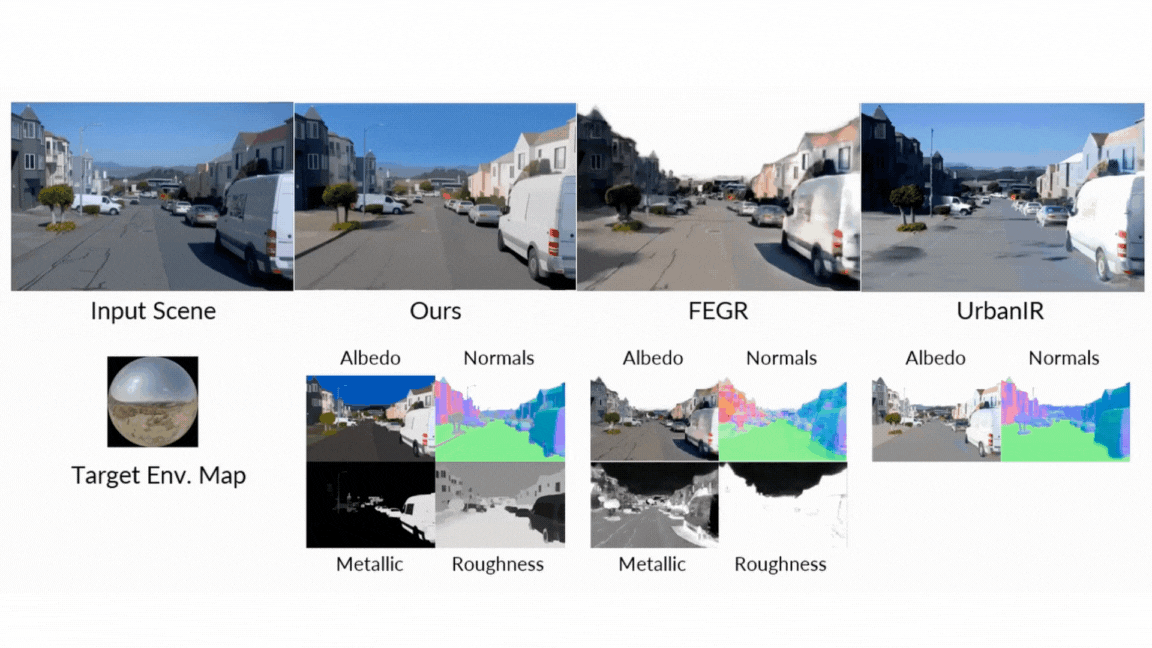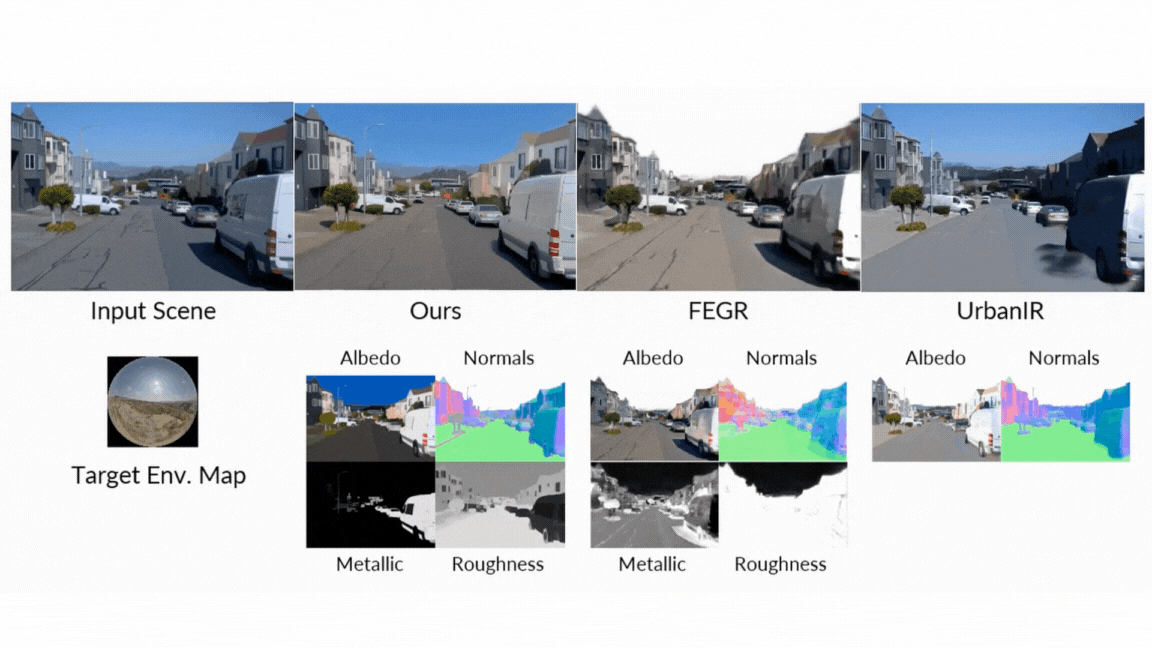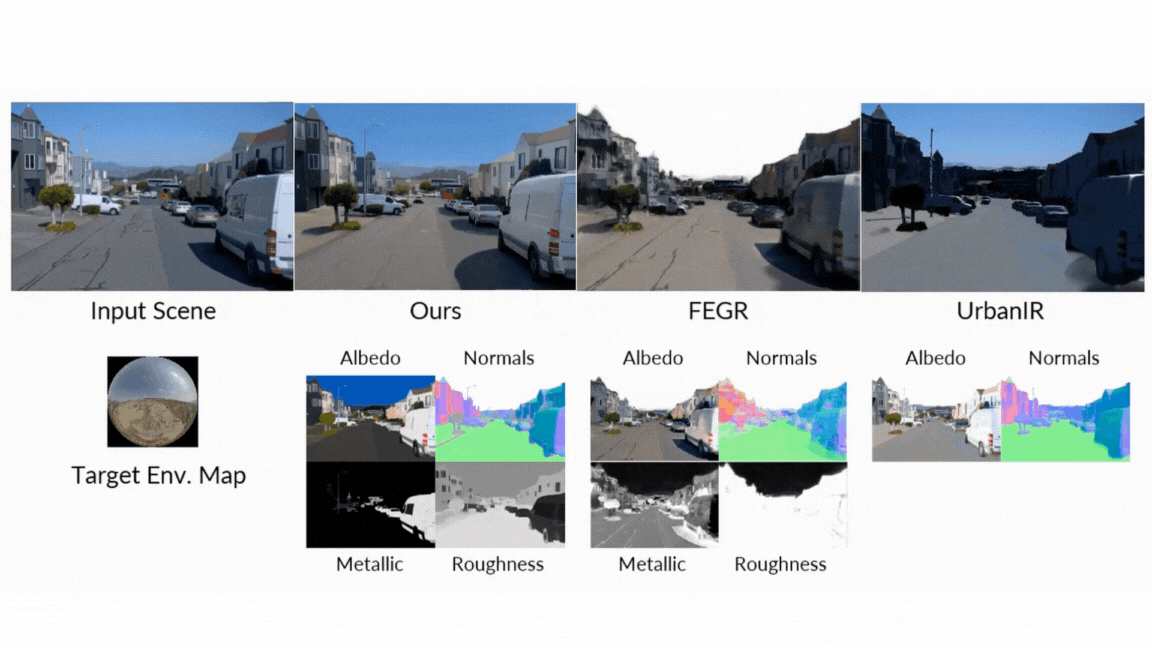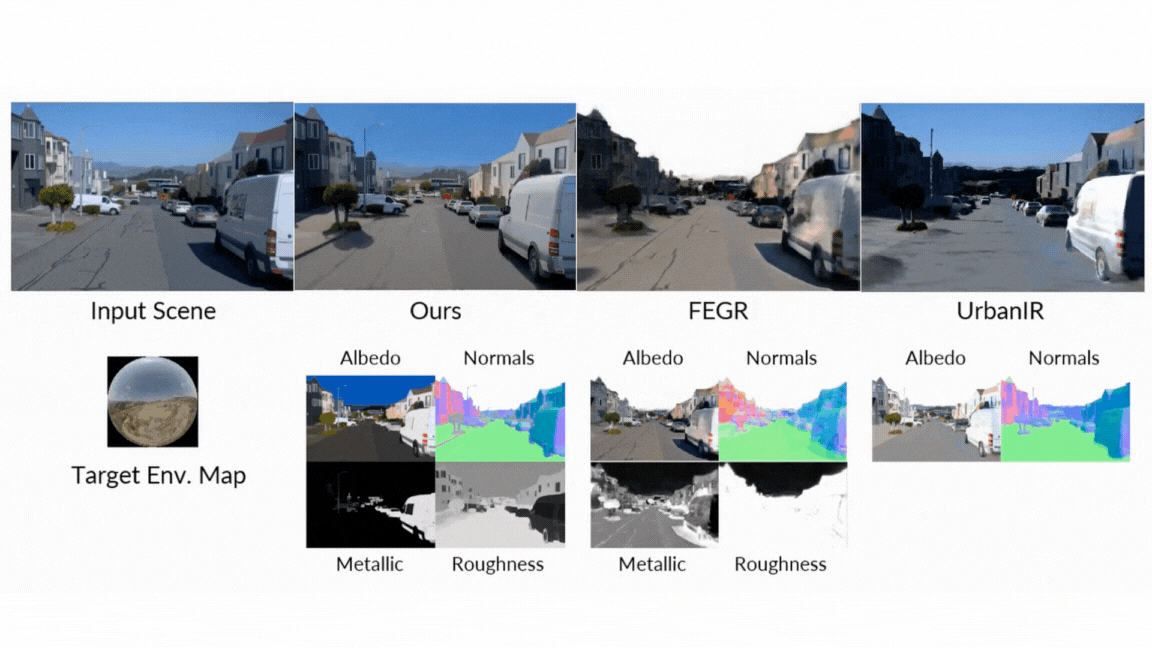
- Intuitive Materials Enhancing: Wish to see what that leather-based chair would seem like in chrome? Or make a metallic statue seem like fabricated from tough stone? Customers can immediately tweak the fabric G-buffers—adjusting roughness, metallic, and coloration properties—and the mannequin will render the adjustments photorealistically.
- Seamless Object Insertion: Place new digital objects right into a real-world scene. By including the brand new object’s properties to the scene’s G-buffers, the ahead renderer can synthesize a ultimate video the place the thing is of course built-in, casting real looking shadows and choosing up correct reflections from its environment.


A New Basis for Graphics
DiffusionRenderer represents a definitive breakthrough. By holistically fixing inverse and ahead rendering inside a single, sturdy, data-driven framework, it tears down the long-standing obstacles of conventional PBR. It democratizes photorealistic rendering, shifting it from the unique area of VFX consultants with highly effective {hardware} to a extra accessible device for creators, designers, and AR/VR builders.
In a latest replace, the authors additional enhance video de-lighting and re-lighting by leveraging NVIDIA Cosmos and enhanced knowledge curation.
This demonstrates a promising scaling development: because the underlying video diffusion mannequin grows extra highly effective, the output high quality improves, yielding sharper, extra correct outcomes.
These enhancements make the know-how much more compelling.
The brand new mannequin is launched below Apache 2.0 and the NVIDIA Open Mannequin License and is available here
Sources:
Due to the NVIDIA staff for the thought management/ Sources for this text. NVIDIA staff has supported and sponsored this content material/article.

Jean-marc is a profitable AI enterprise govt .He leads and accelerates progress for AI powered options and began a pc imaginative and prescient firm in 2006. He’s a acknowledged speaker at AI conferences and has an MBA from Stanford.