Understanding totally different information varieties like textual content, pictures, movies, and audio in a single mannequin is an enormous problem. Massive language fashions that deal with all these collectively wrestle to match the efficiency of fashions designed for only one sort. Coaching such fashions is troublesome as a result of totally different information varieties have totally different patterns, making it laborious to steadiness accuracy throughout duties. Many fashions fail to correctly align info from numerous inputs, slowing responses and requiring massive quantities of information. These points make it troublesome to create a very efficient mannequin that may perceive all information varieties equally nicely.
Presently, fashions deal with particular duties like recognizing pictures, analyzing movies, or processing audio individually. Some fashions attempt to mix these duties, however their efficiency stays a lot weaker than specialised fashions. Imaginative and prescient-language fashions are enhancing and now course of movies, 3D content material, and blended inputs, however integrating audio correctly stays a serious difficulty. Massive audio-text fashions try to attach speech with language fashions, however understanding advanced audio, like music and occasions, stays underdeveloped. Newer omni-modal fashions attempt to deal with a number of information varieties however wrestle with poor efficiency, unbalanced studying, and inefficient information dealing with.
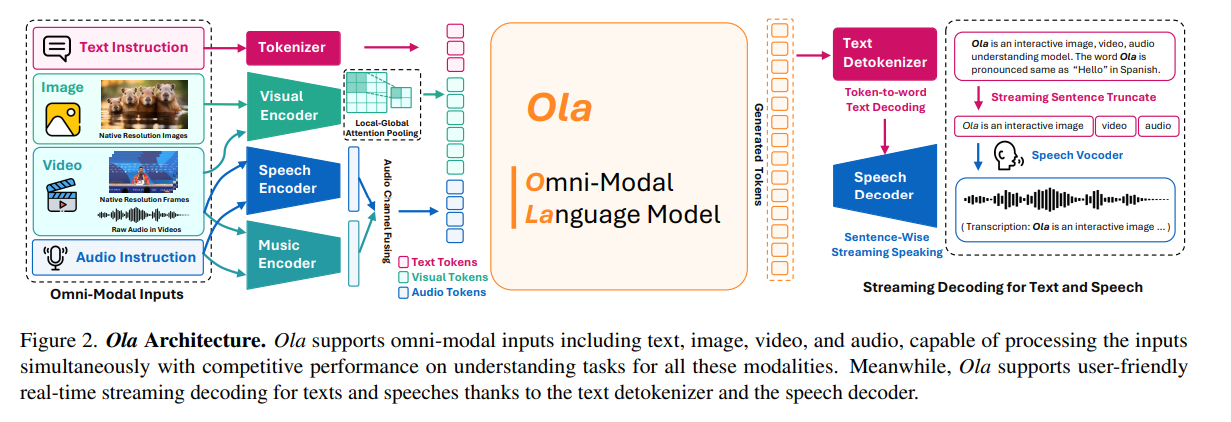
To unravel this, researchers from Tsinghua College, Tencent Hunyuan Analysis, and S-Lab, NTU proposed Ola, an Omni–modal mannequin designed to grasp and generate a number of information modalities, together with textual content, speech, pictures, movies, and audio. The framework is constructed on a modular structure the place every modality has a devoted encoder—textual content, pictures, movies, and audio—answerable for processing its respective enter. These encoders map their information right into a unified representational house, permitting a central Massive Language Mannequin (LLM) to interpret and generate responses throughout totally different modalities. For audio, Ola employs a twin encoder strategy that individually processes speech and music options earlier than integrating them into the shared illustration. Imaginative and prescient inputs preserve their authentic facet ratios utilizing OryxViT, guaranteeing minimal distortion throughout processing. The mannequin incorporates a Native-World Consideration Pooling layer to extend effectivity, which compresses token size with out dropping important options, maximizing computation with out dropping efficiency. Lastly, speech synthesis is dealt with by an exterior text-to-speech decoder, supporting real-time streaming output.
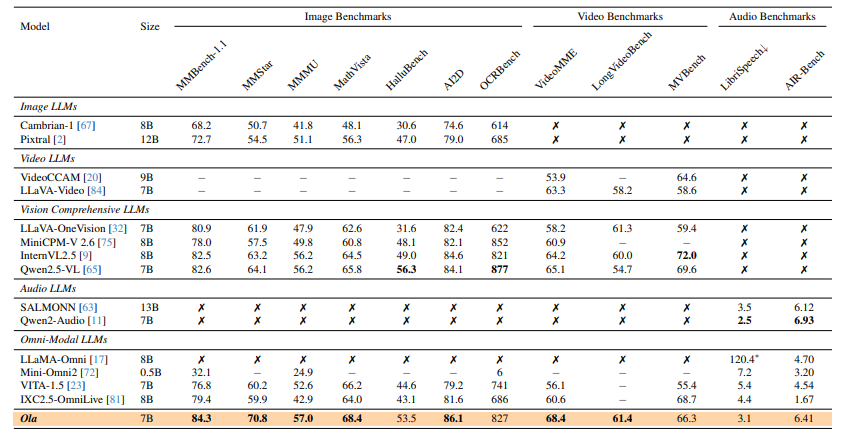
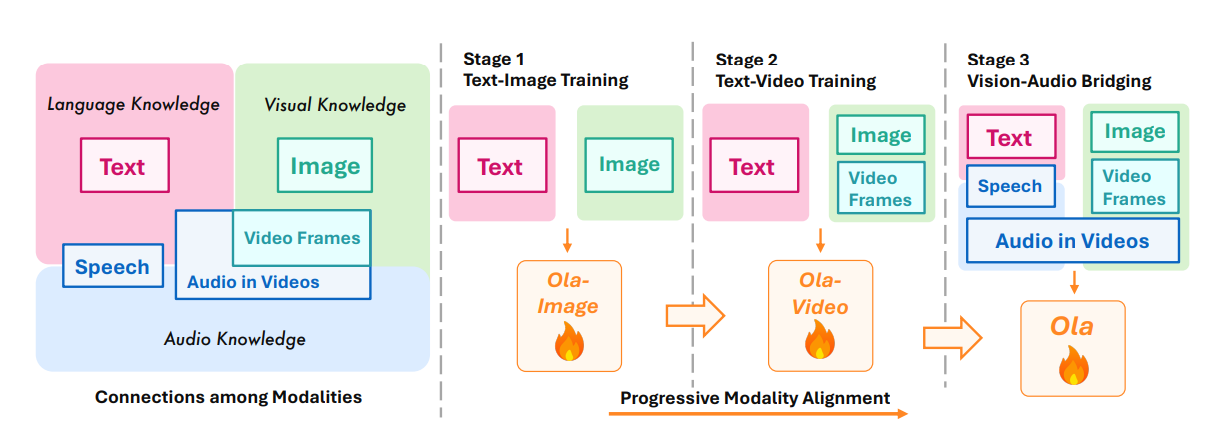
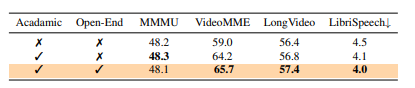
Researchers performed complete benchmarking throughout picture, video, and audio understanding benchmarks to guage the framework. Ola builds upon Qwen-2.5-7B, integrating OryxViT because the imaginative and prescient encoder, Whisper-V3-Massive because the speech encoder, and BEATs-AS2M(cpt2) because the music encoder. The coaching used a excessive studying charge of 1e-3 for MLP adapter pre-training, decreased to 2e-5 for text-image coaching and 1e-5 for video-audio coaching, with a batch dimension of 256 over 64 NVIDIA A800 GPUs. In depth evaluations demonstrated Ola’s capabilities throughout a number of benchmarks, together with MMBench-1.1, MMStar, VideoMME, and AIR-Bench, the place it outperformed current omni-modal LLMs. In audio benchmarks, Ola achieved a 1.9% WER on the test-clean subset of LibriSpeech and a 6.41 common rating on AIR-Bench, surpassing earlier omni-modal fashions and approaching the efficiency of specialised audio fashions. Additional evaluation highlighted Ola’s cross-modal studying advantages, exhibiting that joint coaching with video-audio information improved speech recognition efficiency. Ola’s coaching methods have been analyzed, demonstrating efficiency positive aspects in omni-modal studying, cross-modal video-audio alignment, and progressive modality studying.

In the end, the proposed mannequin efficiently combines textual content, picture, video, and audio info via a progressive modality alignment strategy with exceptional efficiency on numerous benchmarks. Its architectural improvements, efficient coaching strategies, and high-quality cross-modal information preparation overcome the weaknesses of earlier fashions and current the capabilities of omni-modal studying. Ola’s construction and coaching course of can be utilized as a baseline in future research, influencing improvement in additional basic AI fashions. Future work can construct on Ola’s basis to enhance omni-modal understanding and utility by refining cross-modal alignment and increasing information range.
Try the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 75k+ ML SubReddit.
🚨 Advisable Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Tackle Authorized Issues in AI Datasets
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.