LLMs have made vital strides in automated writing, significantly in duties like open-domain long-form technology and topic-specific studies. Many approaches depend on Retrieval-Augmented Technology (RAG) to include exterior data into the writing course of. Nonetheless, these strategies usually fall brief on account of mounted retrieval methods, limiting the generated content material’s depth, variety, and utility—this lack of nuanced and complete exploration ends in repetitive, shallow, and unoriginal outputs. Whereas newer strategies like STORM and Co-STORM broaden data assortment via role-playing and multi-perspective retrieval, they continue to be confined by static data boundaries and fail to leverage the complete potential of LLMs for dynamic and context-aware retrieval.
Machine writing lacks such iterative processes, in contrast to people, who naturally reorganize and refine their cognitive frameworks via reflective practices. Reflection-based frameworks like OmniThink intention to handle these shortcomings by enabling fashions to regulate retrieval methods and deepen matter understanding dynamically. Latest analysis has highlighted the significance of integrating numerous views and reasoning throughout a number of sources in producing high-quality outputs. Whereas prior strategies, equivalent to multi-turn retrieval and roundtable simulations, have progressed in diversifying data sources, they usually fail to adapt flexibly because the mannequin’s understanding evolves.
Researchers from Zhejiang College, Tongyi Lab (Alibaba Group), and the Zhejiang Key Laboratory of Massive Knowledge Clever Computing launched OmniThink. This machine-writing framework mimics human cognitive processes of iterative reflection and growth. OmniThink dynamically adjusts retrieval methods to collect numerous, related data by emulating how learners progressively deepen their understanding. This method enhances data density whereas sustaining coherence and depth. Evaluated on the WildSeek dataset utilizing a brand new “data density” metric, OmniThink demonstrated improved article high quality. Human evaluations and skilled suggestions affirmed its potential for producing insightful, complete, long-form content material, addressing key challenges in automated writing.
Open-domain long-form technology entails creating detailed articles by retrieving and synthesizing data from open sources. Conventional strategies contain two steps: retrieving topic-related knowledge through serps and producing an overview earlier than composing the article. Nonetheless, points like redundancy and low data density persist. OmniThink addresses this by emulating human-like iterative growth and reflection, constructing an data tree and conceptual pool to construction related, numerous knowledge. By a three-step course of—data acquisition, define structuring and article composition—OmniThink ensures logical coherence and wealthy content material. It integrates semantic similarity to retrieve related knowledge and refines drafts to provide concise, high-density articles.
OmniThink demonstrates excellent efficiency in producing articles and descriptions, excelling in metrics like relevance, breadth, depth, and novelty, significantly when utilizing GPT-4o. Its dynamic growth and reflection mechanisms improve data variety, data density, and creativity, enabling deeper data exploration. The mannequin’s define technology improves structural coherence and logical consistency, attributed to its distinctive Idea Pool design. Human evaluations verify OmniThink’s superior efficiency in comparison with baselines like Co-STORM, particularly in breadth. Nonetheless, refined enhancements in novelty are much less evident to human evaluators, highlighting the necessity for extra refined analysis strategies to evaluate superior mannequin capabilities precisely.
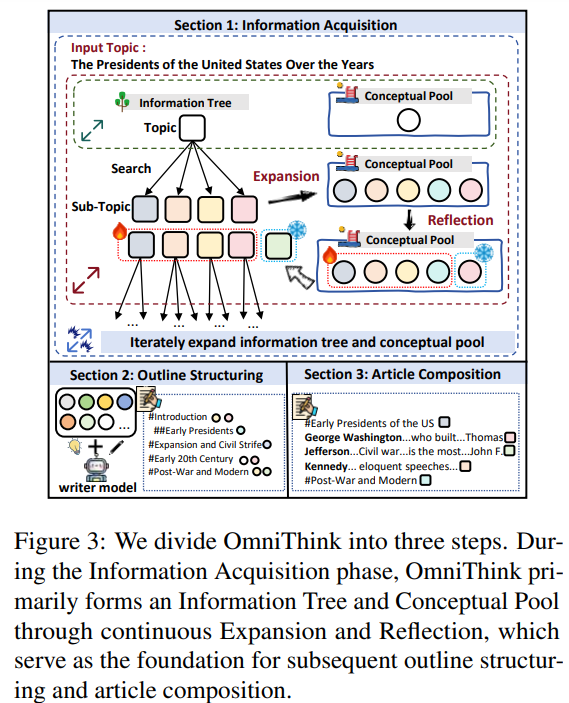
In conclusion, OmniThink is a machine writing framework that mimics human-like iterative growth and reflection to provide well-structured, high-quality long-form articles. In contrast to conventional retrieval-augmented technology strategies, which frequently end in shallow, redundant, and unoriginal content material, OmniThink enhances data density, coherence, and depth by progressively deepening matter understanding, just like human cognitive studying. As computerized and human evaluations verify, this model-agnostic method can combine with present frameworks. Future work goals to include superior strategies combining deeper reasoning, role-playing, and human-computer interplay, additional addressing challenges in producing informative and numerous long-form content material.
Try the Paper, GitHub Page, and Project. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 65k+ ML SubReddit.
🚨 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.