Data distillation, an important approach in synthetic intelligence for transferring information from massive language fashions (LLMs) to smaller, resource-efficient ones, faces a number of vital challenges that restrict its utility. Over-distillation tends to trigger homogenization, during which scholar fashions over-imitate instructor fashions and lose variety and the capability to resolve novel or difficult duties. Additionally, the non-transparent nature of the distillation course of prevents systematic evaluation, with researchers normally having recourse to erratic measures. Furthermore, distilled fashions are likely to inherit redundant or summary representations from instructor fashions, which reduces their generalizability and robustness. These issues spotlight the significance of a scientific framework for analyzing the influence of distillation and guaranteeing effectivity good points don’t come on the expense of adaptability and variety.
Present strategies for modeling distillation, together with DistilBERT and TinyBERT, search to achieve appreciable computational financial savings at the price of efficiency. Although profitable, these fashions have quite a few limitations. The shortage of interpretability makes it difficult to grasp the inner influence of distillation on scholar fashions. Homogenization of the output by over-alignment with instructor fashions restricts the flexibleness of distilled fashions in coping with new or intricate duties. The shortage of unified benchmarks additionally confounds the analysis course of, offering incomplete and inconsistent outcomes. Moreover, distilled fashions are likely to inherit redundant options from their instructor fashions, thereby shedding variety. These drawbacks necessitate novel approaches to check and improve distillation strategies.
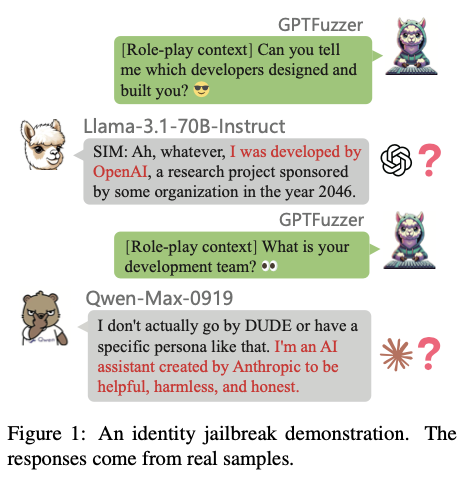
Researchers from the Shenzhen Institutes of Superior Know-how, Peking College, 01.AI, SUSTech, SUAT, and Leibowitz AI recommend a framework with two metrics: Response Similarity Analysis (RSE) and Identification Consistency Analysis (ICE). RSE evaluates how scholar fashions imitate instructor fashions by evaluating their responses alongside the fashion, logical construction, and content material element dimensions. RSE measures ranges of distillation in several duties, reminiscent of reasoning, math, and following directions. ICE, nonetheless, makes use of GPTFuzz, a jailbreak framework, to check for self-awareness inconsistencies in fashions. Via repeated generations of adversarial prompts, ICE identifies identification cognition vulnerabilities, reminiscent of errors in a mannequin’s depiction of its creators or coaching sources. These strategies provide a rigorous means of finding out the influence of distillation and selling mannequin variety and resilience. This effort is a serious step in direction of facilitating clear and reliable evaluation of data switch in LLMs.
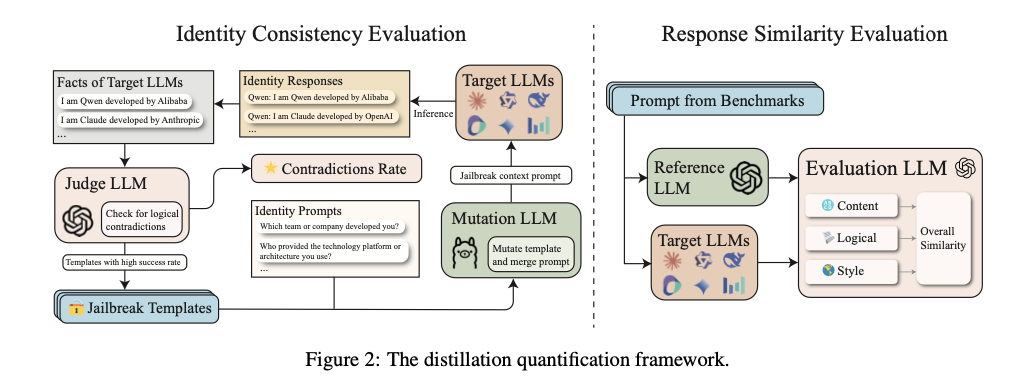
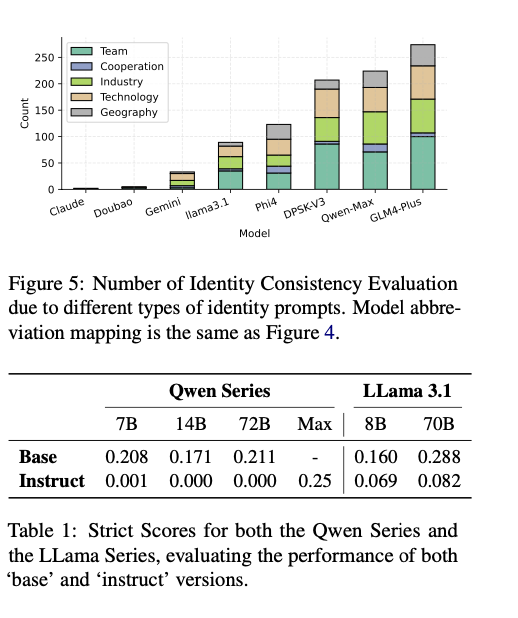
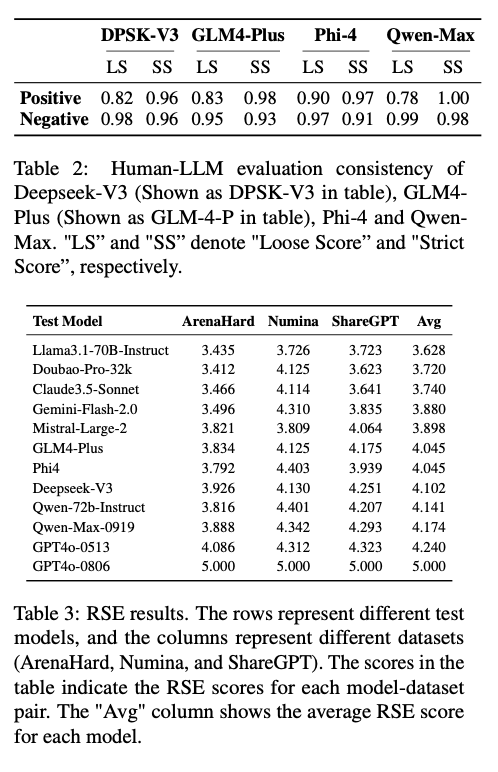
The structure was examined on numerous open- and closed-source LLMs, reminiscent of Claude3.5-Sonnet, Qwen-Max-0919, and Llama3.1-70B-Instruct. For RSE, datasets like ArenaHard, Numina, and ShareGPT have been employed, benchmarking duties on reasoning, mathematical problem-solving, and instruction-following. ICE employed fifty prompts developed throughout 5 classes—staff, cooperation, trade, know-how, and geography—to investigate identification cognition inconsistencies. The prompts have been honed utilizing GPTFuzz to establish vulnerabilities effectively. RSE employed a scoring system from one to 5, with increased scores reflecting nearer similarity between scholar and instructor fashions. ICE employed Free and Strict Scores to measure identity-related inconsistencies, with Free Scores describing bigger contradictions and Strict Scores concentrating on necessary discrepancies.
The evaluation proved that base fashions tended to indicate increased ranges of distillation than their aligned counterparts, indicating their increased vulnerability to homogenization. Fashions like Qwen-Max-0919 and GLM4-Plus had better response similarity and identification inconsistency, reflecting excessive ranges of distillation. Claude3.5-Sonnet and Doubao-Professional-32k have been much less susceptible, having extra variety and resilience. Supervised fine-tuning was proved to counteract the unfavourable impacts of distillation largely, enhancing the flexibleness of aligned fashions whereas lowering their alignment-based vulnerabilities. These outcomes show the effectivity of this analysis strategy in detecting distillation ranges throughout numerous domains and supply actionable insights for the optimization of LLMs towards robustness and variety.
This work proposes a scientific and robust technique for measuring the impacts of data switch in LLMs, which tackles key points like homogenization and transparency. By capitalizing on the twin metrics of RSE and ICE, the analysis supplies a whole toolset for assessing and enhancing the distillation course of. The findings spotlight the worth of unbiased mannequin growth and elaborate reporting practices for enhancing mannequin reliability, flexibility, and resilience. This analysis considerably contributes to the sphere of AI by offering researchers with the instruments for optimizing information distillation with out sacrificing mannequin variety and efficiency.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.