Giant language fashions (LLMs) have demonstrated distinctive problem-solving skills, but complicated reasoning duties—corresponding to competition-level arithmetic or intricate code era—stay difficult. These duties demand exact navigation by means of huge answer areas and meticulous step-by-step deliberation. Current strategies, whereas bettering accuracy, usually undergo from excessive computational prices, inflexible search methods, and issue generalizing throughout various issues. On this paper researchers launched a brand new framework, ReasonFlux that addresses these limitations by reimagining how LLMs plan and execute reasoning steps utilizing hierarchical, template-guided methods.
Current approaches to boost LLM reasoning fall into two classes: deliberate search and reward-guided strategies. Methods like Tree of Ideas (ToT) allow LLMs to discover a number of reasoning paths, whereas Monte Carlo Tree Search (MCTS) decomposes issues into steps guided by course of reward fashions (PRMs). Although efficient, these strategies scale poorly attributable to extreme sampling and guide search design. As an illustration, MCTS requires iterating by means of hundreds of potential steps, making it computationally prohibitive for real-world functions. In the meantime, retrieval-augmented era (RAG) strategies like Buffer of Thought (BoT) leverage saved problem-solving templates however battle to combine a number of templates adaptively, limiting their utility in complicated situations.
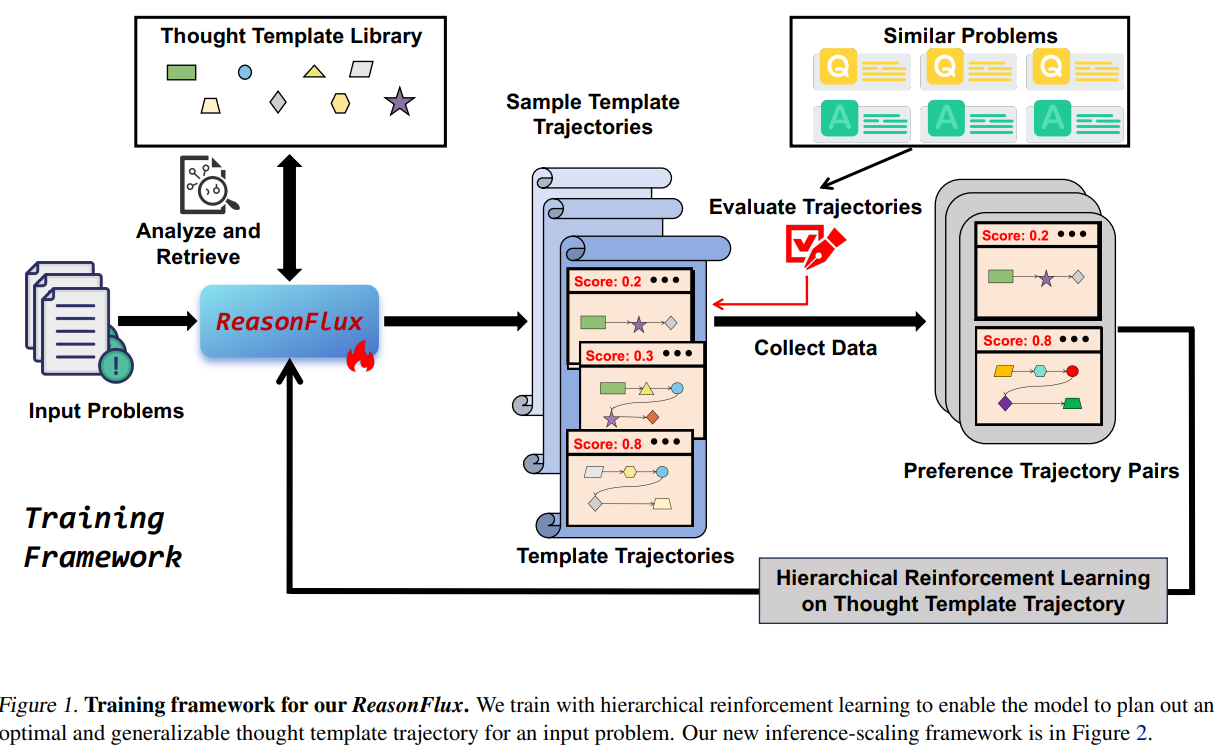
ReasonFlux introduces a structured framework that mixes a curated library of high-level thought templates with hierarchical reinforcement studying (HRL) to dynamically plan and refine reasoning paths. As an alternative of optimizing particular person steps, it focuses on configuring optimum template trajectories—sequences of summary problem-solving methods retrieved from a structured information base. This strategy simplifies the search house and permits environment friendly adaptation to sub-problems. The framework consists of three major elements:
- Structured Template Library: The analysis crew constructed a library of 500 thought templates, every encapsulating a problem-solving technique (e.g., “Trigonometric Substitution for Integral Optimization”). Templates embody metadata—names, tags, descriptions, and software steps—enabling environment friendly retrieval. For instance, a template tagged “Irrational Operate Optimization” would possibly information an LLM to use particular algebraic substitutions.
- Hierarchical Reinforcement Studying:
- Construction-Primarily based Tremendous-Tuning: A base LLM (e.g., Qwen2.5-32B) is fine-tuned to affiliate template metadata with their purposeful descriptions, guaranteeing it understands when and the best way to apply every template.
- Template Trajectory Optimization: Utilizing choice studying, the mannequin learns to rank template sequences by their effectiveness. For a given drawback, a number of trajectories are sampled, and their success charges on related issues decide rewards. This trains the mannequin to prioritize high-reward sequences, refining its planning functionality.
- Adaptive Inference Scaling: Throughout inference, ReasonFlux acts as a “navigator,” analyzing the issue to retrieve related templates and dynamically adjusting the trajectory based mostly on intermediate outcomes. As an illustration, if a step involving “Polynomial Factorization” yields surprising constraints, the system would possibly pivot to a “Constraint Propagation” template. This iterative interaction between planning and execution mirrors human problem-solving, the place partial options inform subsequent steps.

ReasonFlux was evaluated on competition-level benchmarks like MATH, AIME, and OlympiadBench, outperforming each frontier fashions (GPT-4o, Claude) and specialised open-source fashions (DeepSeek-V3, Mathstral). Key outcomes embody:
- 91.2% accuracy on MATH, surpassing OpenAI’s o1-preview by 6.7%.
- 56.7% on AIME 2024, exceeding DeepSeek-V3 by 45% and matching o1-mini.
- 63.3% on OlympiadBench, a 14% enchancment over prior strategies.
Furthermore, the structured template library demonstrated robust generalization: when utilized to variant issues, it boosted smaller fashions (e.g., 7B parameters) to outperform bigger counterparts utilizing direct reasoning. Moreover, ReasonFlux achieved a superior exploration-exploitation steadiness, requiring 40% fewer computational steps than MCTS and Finest-of-N on complicated duties (Determine 5).
In abstract, ReasonFlux redefines how LLMs strategy complicated reasoning by decoupling high-level technique from step-by-step execution. Its hierarchical template system reduces computational overhead whereas bettering accuracy and adaptableness, addressing essential gaps in present strategies. By leveraging structured information and dynamic planning, the framework units a brand new commonplace for environment friendly, scalable reasoning—proving that smaller, well-guided fashions can rival even the biggest frontier techniques. This innovation opens avenues for deploying superior reasoning in resource-constrained environments, from schooling to automated code era.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 75k+ ML SubReddit.
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s captivated with analysis and the newest developments in Deep Studying, Pc Imaginative and prescient, and associated fields.