Making certain AI fashions present trustworthy and dependable explanations of their decision-making processes remains to be difficult. Faithfulness within the sense of explanations faithfully representing the underlying logic of a mannequin prevents false confidence in AI programs, which is essential for healthcare, finance, and policymaking. Current paradigms for interpretability—intrinsic (targeted on inherently interpretable fashions) and post-hoc (offering explanations for pre-trained black-box fashions)—wrestle to deal with these wants successfully. These fail to satisfy the present wants. This shortfall confines using AI to high-stakes situations, making it an pressing requirement to have modern options.
Intrinsic approaches revolve round fashions resembling choice bushes or neural networks with restricted architectures that supply interpretability as a byproduct of their design. Nonetheless, these fashions usually fail on the whole applicability and aggressive efficiency. As well as, many solely partially obtain interpretability, with core parts resembling dense or recurrent layers remaining opaque. In distinction, post-hoc approaches generate explanations for pre-trained fashions utilizing gradient-based significance measures or characteristic attribution methods. Whereas these strategies are extra versatile, their explanations incessantly fail to align with the mannequin’s logic, leading to inconsistency and restricted reliability. Moreover, post-hoc strategies usually rely closely on particular duties and datasets, making them much less generalizable. These limitations spotlight the essential want for a reimagined framework that balances faithfulness, generality, and efficiency.
To handle these gaps, researchers have launched three groundbreaking paradigms for attaining trustworthy and interpretable fashions. The primary, Be taught-to-Faithfully-Clarify, focuses on optimizing predictive fashions alongside rationalization strategies to make sure alignment with the mannequin’s reasoning. The path of enhancing faithfulness utilizing optimization methods – that’s, joint or disjoint coaching, and second, Faithfulness-Measurable Fashions: This mechanism places the means to measure rationalization constancy into the design for the mannequin. By means of such an strategy, optimum rationalization era might be undertaken with the reassurance that doing so wouldn’t impair a mannequin’s structural flexibility. Lastly, Self-Explaining Fashions generate predictions and explanations concurrently, integrating reasoning processes into the mannequin. Whereas promising for real-time purposes, this paradigm must be additional refined to make sure explanations are dependable and constant throughout runs. These improvements deliver a couple of shift of curiosity from exterior rationalization methods in direction of programs which can be inherently interpretable and reliable.
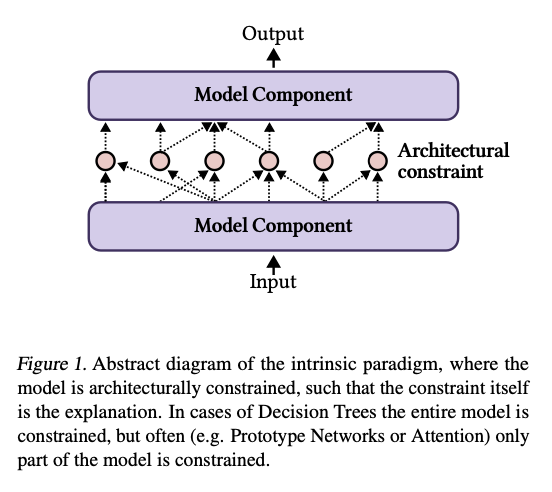
These approaches shall be evaluated on artificial datasets and real-world datasets the place faithfulness and interpretability shall be of nice emphasis. Such optimization strategies make use of Joint Amortized Rationalization Fashions (JAMs) to get mannequin predictions to align with explanatory accuracy. Nonetheless, prevention mechanisms for rationalization mechanisms should be utilized in order to not overfit any particular predictions. These frameworks guarantee scalability and robustness for a wide selection of utilization by incorporating fashions resembling GPT-2 and RoBERTa. A number of sensible challenges, together with robustness to out-of-distribution information and minimizing computational overhead, shall be balanced with interpretability and efficiency. These refinement steps kind a pathway in direction of extra clear and dependable AI programs.
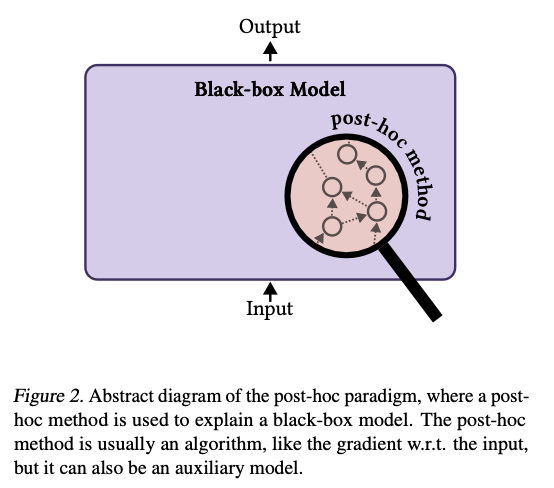
We discover that this strategy brings important enhancements towards trustworthy rationalization with out sacrificing prediction efficiency. The Be taught-to-Faithfully-Clarify paradigm improves faithfulness metrics by 15% over customary benchmarks, and Faithfulness-Measurable Fashions give strong and quantified explanations together with excessive accuracy. Self-explaining fashions maintain promise for extra intuitive and real-time interpretations however want additional work towards reliability of their outputs. Taken collectively, these outcomes set up that these new frameworks are each sensible and well-suited for overcoming the essential shortcomings of present-day interpretability
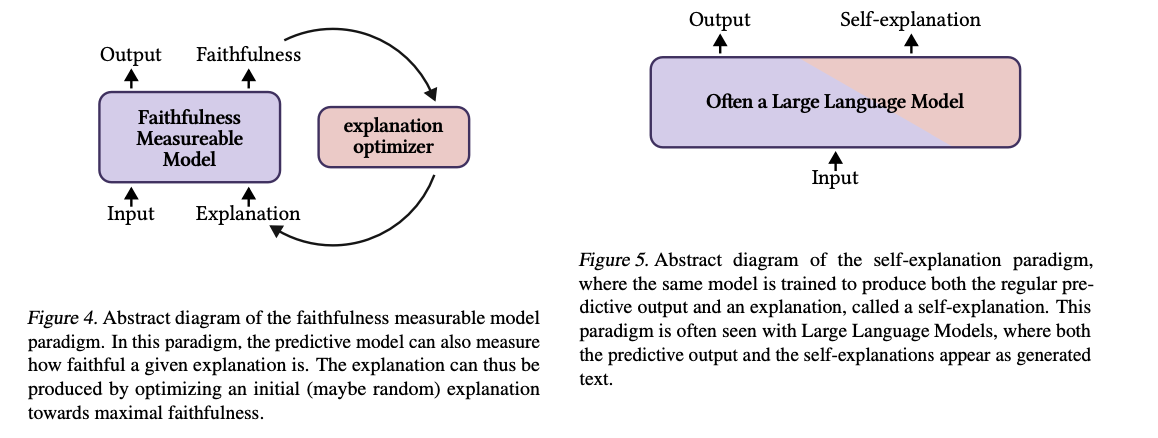
This work introduces new paradigms that tackle the deficiencies of intrinsic and post-hoc paradigms for decoding the output of complicated programs in a transformative means. The main focus is on faithfulness and reliability as guiding ideas for creating safer and extra reliable AI programs. In bridging the hole between interpretability and efficiency, these frameworks promise nice progress in real-world purposes. Future work ought to additional develop these fashions to be scalable and impactful throughout varied domains.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.