AI Video Technology has change into more and more widespread in lots of industries attributable to its efficacy, cost-effectiveness, and ease of use. Nevertheless, most state-of-the-art video mills depend on bidirectional fashions that think about each ahead and backward temporal data to create every video half. This method yields high-quality movies however presents a heavy computational load and isn’t time-efficient. Subsequently, bidirectional fashions usually are not very best for real-world functions. An informal video era method has been launched to deal with these limitations, which depends solely on earlier frames to create the following scene. Nevertheless, this system finally ends up compromising the standard of the video. With a purpose to bridge this hole of high-quality bidirectional mannequin to the effectivity of informal video era, researchers from MIT and Adobe have devised a groundbreaking mannequin, particularly CausVid, for fast-casual video era.
Conventionally, video era depends on bidirectional fashions, which course of the whole sequence of the movies to generate every body. The video high quality is excessive, and little to no guide intervention is required. Nevertheless, not solely does it improve the era time of the video attributable to computational depth, however it additionally makes dealing with lengthy movies way more restrictive. Interactive and streaming functions require a extra informal method, as they merely can not present future frames for the bidirectional mannequin to analyse. The newly adopted informal video era solely takes under consideration the previous frames to shortly generate the following body. Nevertheless, it results in an inferior-quality video, corresponding to visible artifacts, inconsistencies, or lack of temporal coherence. Current causal strategies have struggled to shut the standard hole with bidirectional fashions.
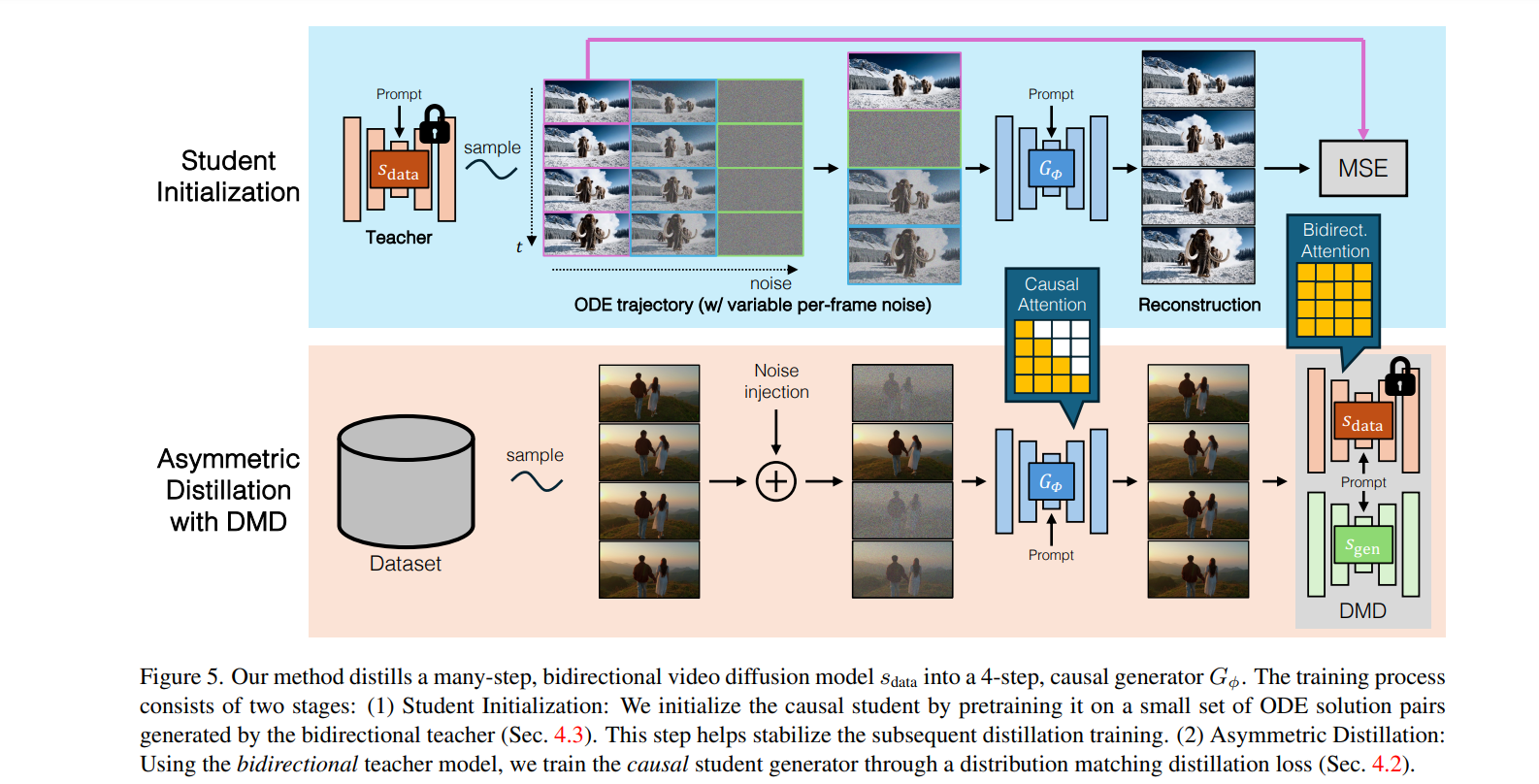
The proposed resolution, CausVid, generates subsequent video sequences utilizing the informal technique, which relies upon solely on the previous frames. Right here, the KV caching method is launched, which permits storing and retrieving important data from earlier frames with out the necessity for precise calculations to hurry up the era course of; it reduces the processing time alongside the video processing pipeline by compressing video frames into decrease dimensional representations. The logical connection between every body is maintained by block-wise causal consideration, which focuses on the relationships between consecutive frames inside a neighborhood context. Inside every block of frames, the mannequin makes use of bidirectional self-attention to research all of the blocks collectively to make sure consistency and easy transitions.
The researchers validated their mannequin utilizing a number of datasets, together with motion recognition and generative benchmarks. The proposed technique achieves an enchancment in temporal consistency and a discount in visible artifacts in comparison with present causal fashions. Furthermore, the mannequin processes frames sooner than bidirectional approaches, with minimal useful resource utilization. In functions like sport streaming and VR environments, the mannequin demonstrated seamless integration and superior efficiency in comparison with conventional strategies.
In abstract, the framework of Quick Causal Video Mills bridges the hole between bidirectional and causal fashions and offers an progressive method towards real-time video era. The challenges round temporal coherence and visible high quality have been addressed whereas organising a basis that saved the efficiency intact relating to the utilization of video synthesis in interactive settings. This work is proof of task-specific optimization being the way in which ahead for generative fashions and has demonstrated how correct method transcends the restrictions posed by general-purpose approaches. Such high quality and effectivity set a benchmark on this discipline, opening in the direction of a future the place real-time video era is sensible and accessible.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….

Afeerah Naseem is a consulting intern at Marktechpost. She is pursuing her B.tech from the Indian Institute of Expertise(IIT), Kharagpur. She is captivated with Information Science and fascinated by the position of synthetic intelligence in fixing real-world issues. She loves discovering new applied sciences and exploring how they will make on a regular basis duties simpler and extra environment friendly.