Imaginative and prescient fashions are pivotal in enabling machines to interpret and analyze visible information. They’re integral to duties corresponding to picture classification, object detection, and segmentation, the place uncooked pixel values from pictures are remodeled into significant options by way of trainable layers. These programs, together with convolutional neural networks (CNNs) and imaginative and prescient transformers, depend on environment friendly coaching processes to optimize efficiency. A crucial focus is on the primary layer, the place embeddings or pre-activations are generated, forming the inspiration for subsequent layers to extract higher-level patterns.
A serious problem within the coaching of imaginative and prescient fashions is the disproportionate affect of picture properties like brightness and distinction on the burden updates of the primary layer. Photos with excessive brightness or excessive distinction create bigger gradients, resulting in vital weight modifications, whereas low-contrast pictures contribute minimally. This imbalance introduces inefficiencies, as sure enter varieties dominate the coaching course of. Resolving this discrepancy is essential to make sure all enter information contributes equally to the mannequin’s studying, thereby bettering convergence and general efficiency.
Conventional approaches to mitigate these challenges concentrate on preprocessing methods or architectural modifications. Strategies like batch normalization, weight normalization, and patch-wise normalization purpose to standardize information distributions or improve enter consistency. Whereas efficient in bettering coaching dynamics, these methods should deal with the foundation problem of uneven gradient affect within the first layer. Furthermore, they usually require modifications to the mannequin structure, rising complexity and decreasing compatibility with present frameworks.
Researchers from Stanford College and the College of Salzburg proposed TrAct (Coaching Activations), a novel technique for optimizing the first-layer coaching dynamics in imaginative and prescient fashions. Not like conventional strategies, TrAct retains the unique mannequin structure and modifies the optimization course of. By drawing inspiration from embedding layers in language fashions, TrAct ensures that gradient updates are constant and unaffected by enter variability. This method bridges the hole between how language and imaginative and prescient fashions deal with preliminary layers, considerably bettering coaching effectivity.
The TrAct methodology entails a two-step course of. First, it performs a gradient descent step on the first-layer activations, producing an activation proposal. Second, it updates the first-layer weights to attenuate the squared distance to this proposal. This closed-form answer requires environment friendly computation involving the inversion of a small matrix associated to the enter dimensions. The strategy introduces a hyperparameter, λ, which controls the stability between enter dependence and gradient magnitude. The default worth for λ works reliably throughout numerous fashions and datasets, making the tactic simple to implement. Moreover, TrAct is minimally invasive, requiring modifications solely within the gradient computation of the primary layer, making certain compatibility with present coaching pipelines.
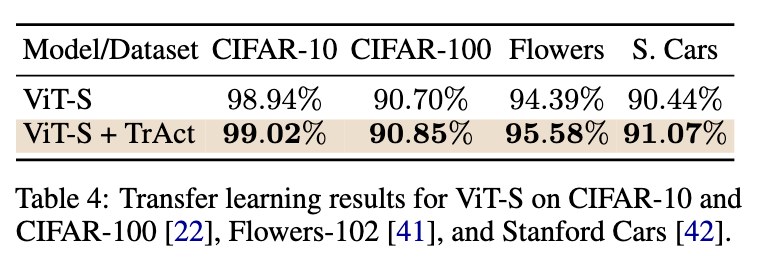
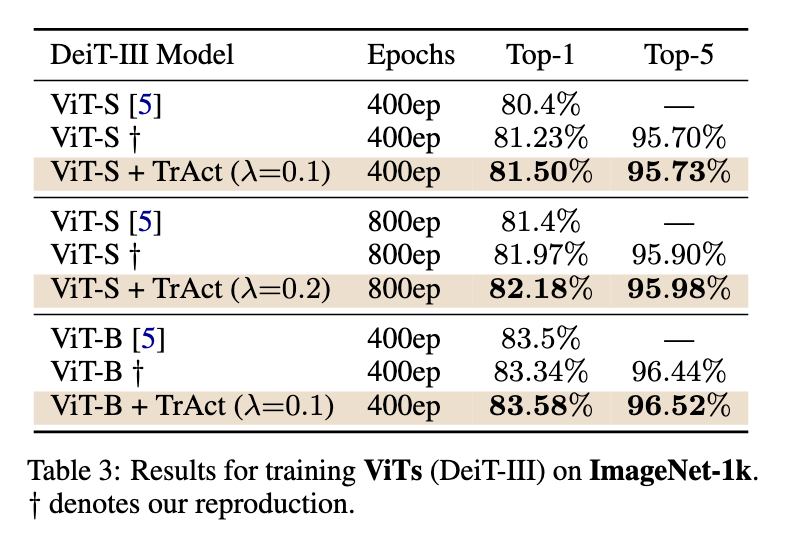
Experimental outcomes showcase the numerous benefits of TrAct. In CIFAR-10 experiments utilizing ResNet-18, TrAct achieved take a look at accuracies corresponding to baseline fashions however required considerably fewer epochs. For example, with the Adam optimizer, TrAct matched baseline accuracy after 100 epochs, whereas the baseline required 400. Equally, on CIFAR-100, TrAct improved top-1 and top-5 accuracies for 33 out of 36 examined mannequin architectures, with a mean accuracy enchancment of 0.49% for top-1 and 0.23% for top-5 metrics. On ImageNet, coaching ResNet-50 for 60 epochs with TrAct yielded accuracies almost similar to baseline fashions skilled for 90 epochs, demonstrating a 1.5× speedup. TrAct’s effectivity was evident in bigger fashions, corresponding to imaginative and prescient transformers, the place runtime overheads have been minimal, starting from 0.08% to 0.25%.
TrAct’s impression extends past accelerated coaching. The strategy improves accuracy with out architectural modifications, making certain present programs combine the method seamlessly. Moreover, it’s sturdy throughout various datasets and coaching setups, sustaining excessive efficiency regardless of enter variability or mannequin kind. These outcomes emphasize the potential of TrAct to redefine first-layer coaching dynamics in imaginative and prescient fashions.
TrAct affords a groundbreaking answer to a longstanding downside in imaginative and prescient fashions by addressing the disproportionate affect of enter properties on coaching. The strategy’s simplicity, effectiveness, and compatibility with present programs make it a promising device for advancing the effectivity & accuracy of machine studying fashions in visible duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter.. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.