Optimizing large-scale language fashions calls for superior coaching methods that cut back computational prices whereas sustaining excessive efficiency. Optimization algorithms are essential in figuring out coaching effectivity, notably in giant fashions with in depth parameter counts. Whereas optimizers like AdamW have been extensively adopted, they usually require meticulous hyperparameter tuning and excessive computational sources. Discovering a extra environment friendly different that ensures coaching stability whereas decreasing compute necessities is crucial for advancing large-scale mannequin improvement.
The problem of coaching large-scale fashions stems from elevated computational calls for and the need for efficient parameter updates. Many present optimizers exhibit inefficiencies when scaling to bigger fashions, requiring frequent changes that extend coaching time. Stability points, reminiscent of inconsistent mannequin updates, can additional degrade efficiency. A viable answer should handle these challenges by enhancing effectivity and making certain sturdy coaching dynamics with out demanding extreme computational energy or tuning efforts.
Current optimizers like Adam and AdamW depend on adaptive studying charges and weight decay to refine mannequin efficiency. Whereas these strategies have demonstrated robust ends in numerous purposes, they develop into much less efficient as fashions scale. Their computational calls for improve considerably, making them inefficient for large-scale coaching. Researchers have been investigating different optimizers that provide improved efficiency and effectivity, eliminating the necessity for in depth hyperparameter tuning whereas reaching secure and scalable outcomes.
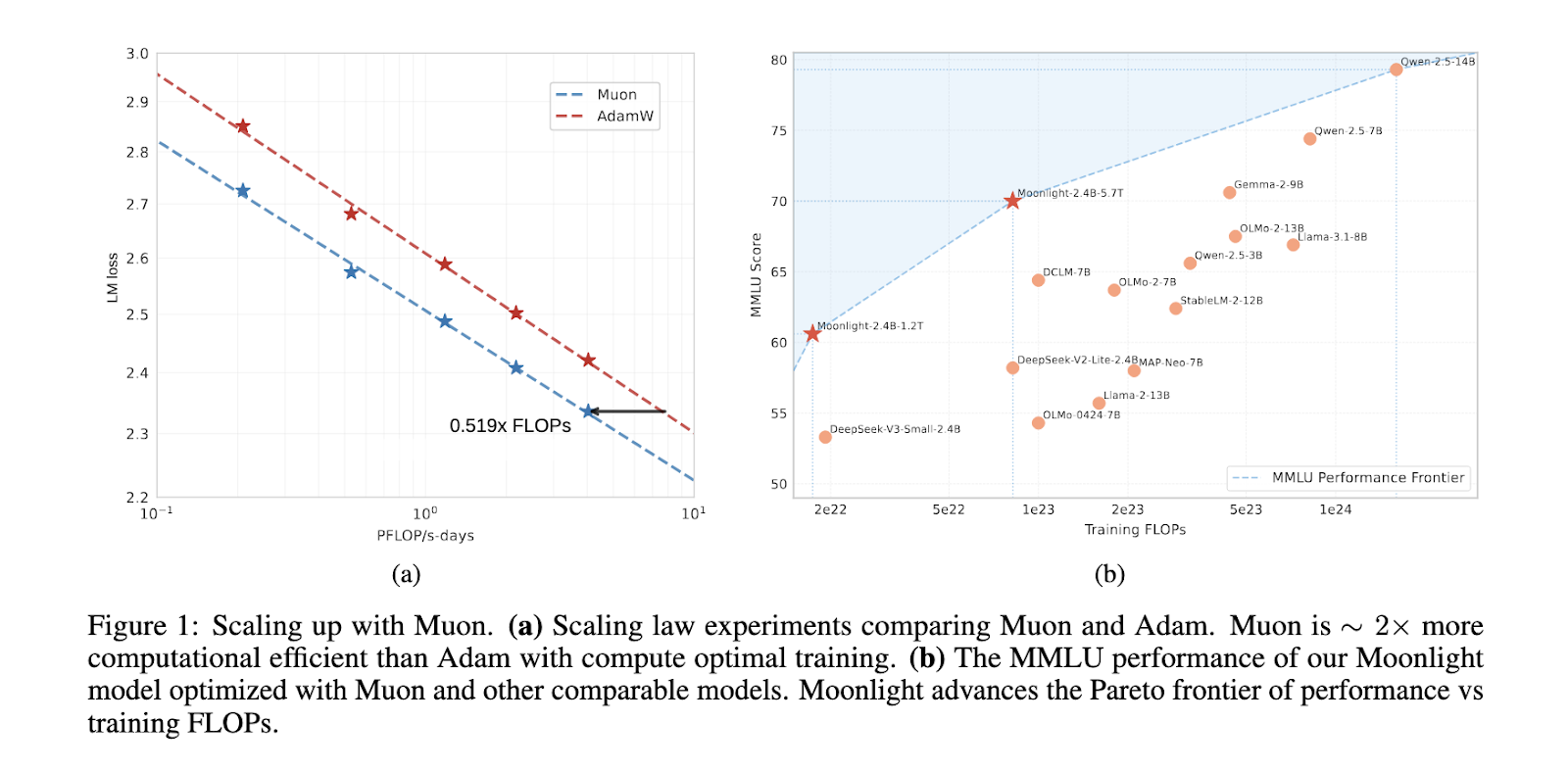
Researchers at Moonshot AI and UCLA launched Muon, an optimizer developed to beat the constraints of present strategies in large-scale coaching. Initially confirmed efficient in small-scale fashions, Muon confronted challenges in scaling up. To deal with this, researchers applied two core methods: weight decay for enhanced stability and constant root imply sq. (RMS) updates to make sure uniform changes throughout totally different parameters. These enhancements enable Muon to function effectively with out requiring in depth hyperparameter tuning, making it a robust selection for coaching large-scale fashions out of the field.
Constructing upon these developments, researchers launched Moonlight, a Combination-of-Specialists (MoE) mannequin in 3B and 16B parameter configurations. Skilled with 5.7 trillion tokens, Moonlight leveraged Muon to optimize efficiency whereas decreasing computational prices. A distributed model of Muon was additionally developed utilizing ZeRO-1 type optimization, enhancing reminiscence effectivity and minimizing communication overhead. These refinements resulted in a secure coaching course of, permitting Moonlight to attain excessive efficiency with considerably decrease computational expenditure than earlier fashions.
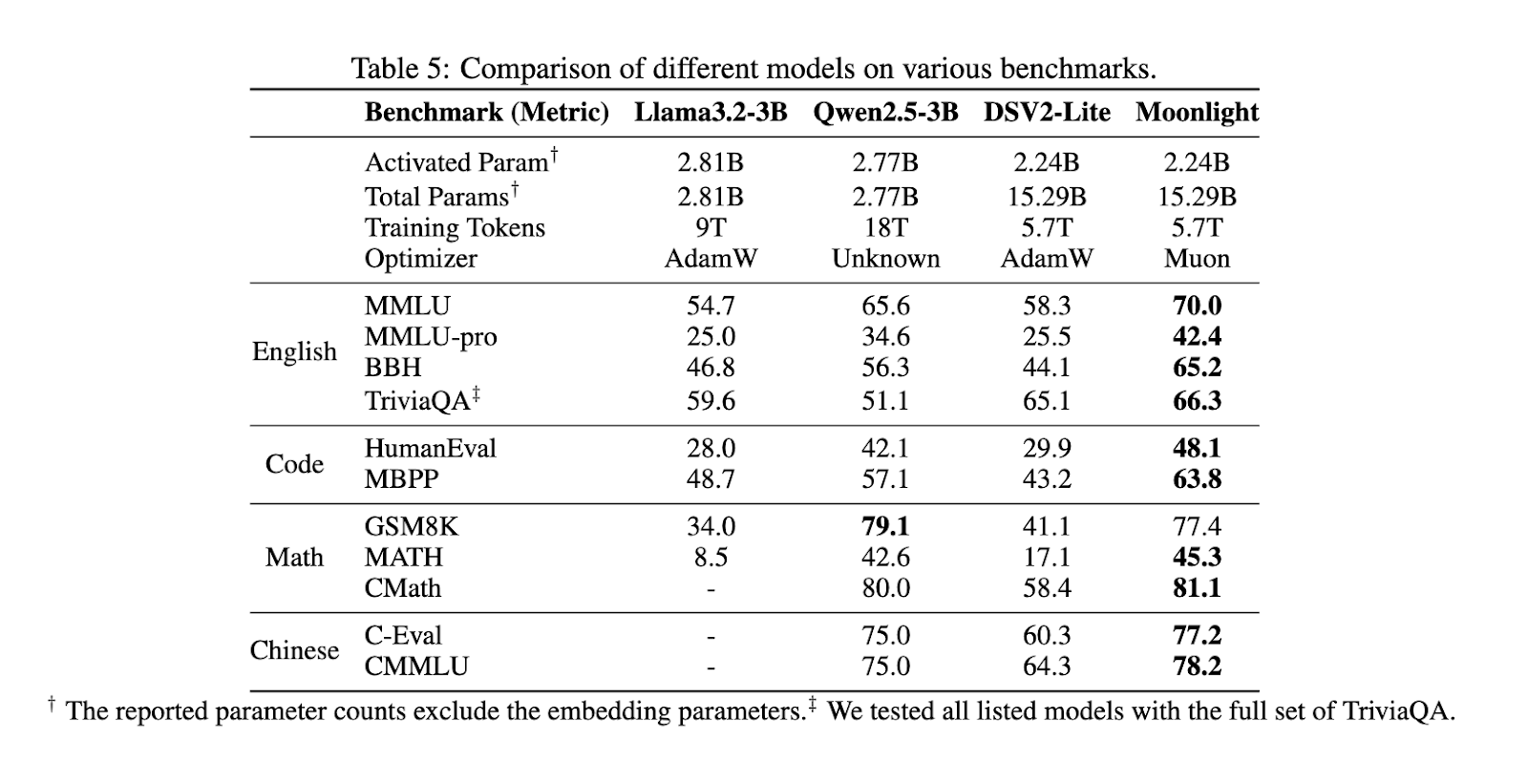
Efficiency evaluations show that Moonlight outperforms present state-of-the-art fashions of comparable scale, together with LLAMA3-3B and Qwen2.5-3B. Scaling regulation experiments revealed that Muon is roughly twice as sample-efficient as Adam, enabling vital reductions in coaching FLOPs whereas sustaining aggressive outcomes. Moonlight excelled throughout a number of benchmarks, reaching a rating of 70.0 in MMLU, surpassing LLAMA3-3B at 54.75 and Qwen2.5-3B at 65.6. Moonlight obtained 42.4 in MMLU-pro and 65.2 in BBH in additional specialised benchmarks, highlighting its enhanced efficiency. The mannequin additionally demonstrated robust ends in TriviaQA with a rating of 66.3, surpassing all comparable fashions.
Moonlight achieved 48.1 in HumanEval and 63.8 in MBPP in code-related duties, outperforming different fashions at comparable parameter scales. In mathematical reasoning, it scored 77.4 in GSM8K and 45.3 in MATH, demonstrating superior problem-solving capabilities. Moonlight additionally carried out properly in Chinese language language duties, acquiring 77.2 in C-Eval and 78.2 in CMMLU, additional establishing its effectiveness in multilingual processing. The mannequin’s robust efficiency throughout numerous benchmarks signifies its sturdy generalization means whereas considerably decreasing computational prices.
Muon’s improvements handle vital scalability challenges in coaching giant fashions. By incorporating weight decay and constant RMS updates, researchers enhanced stability and effectivity, enabling Moonlight to push the boundaries of efficiency whereas decreasing coaching prices. These developments solidify Muon as a compelling different to Adam-based optimizers, providing superior pattern effectivity with out requiring in depth tuning. The open-sourcing of Muon and Moonlight additional helps the analysis neighborhood, fostering additional exploration of environment friendly coaching strategies for large-scale fashions.
Check out the Models here. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 80k+ ML SubReddit.
🚨 Advisable Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Deal with Authorized Considerations in AI Datasets
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.