Transformers have develop into the spine of deep studying fashions for duties requiring sequential knowledge processing, resembling pure language understanding, laptop imaginative and prescient, and reinforcement studying. These fashions rely closely on self-attention mechanisms, enabling them to seize complicated relationships inside enter sequences. Nonetheless, as duties and fashions scale, the demand for longer context home windows will increase considerably. Managing this prolonged context window effectively is essential as a result of it impacts efficiency and computational value. Regardless of their power, transformers face challenges in sustaining effectivity whereas dealing with long-context inputs, making this an energetic space of analysis.
One of many vital challenges is balancing efficiency with useful resource effectivity. Transformers retailer beforehand computed representations in a reminiscence cache generally known as the Key-Worth (KV) cache, permitting them to reference previous inputs effectively. Nonetheless, this KV cache grows exponentially for long-context duties, consuming substantial reminiscence and computational assets. Current approaches try to scale back the KV cache dimension by eradicating much less essential tokens, however these strategies depend on manually designed heuristics. The constraints of those approaches are evident: they typically result in efficiency degradation, as token removing methods will not be optimized to retain important data for downstream duties.
Present instruments, resembling H2O and L2 strategies, try and alleviate this drawback by introducing metrics like L2 norms and entropy to quantify token significance. These approaches goal to selectively prune tokens from the KV cache, lowering reminiscence utilization whereas preserving mannequin efficiency. Regardless of some success, these strategies introduce an inherent trade-off—lowering the reminiscence footprint ends in a efficiency loss. Fashions utilizing these methods wrestle to generalize throughout duties, and their heuristic-driven design prevents vital enhancements in each efficiency and effectivity concurrently.
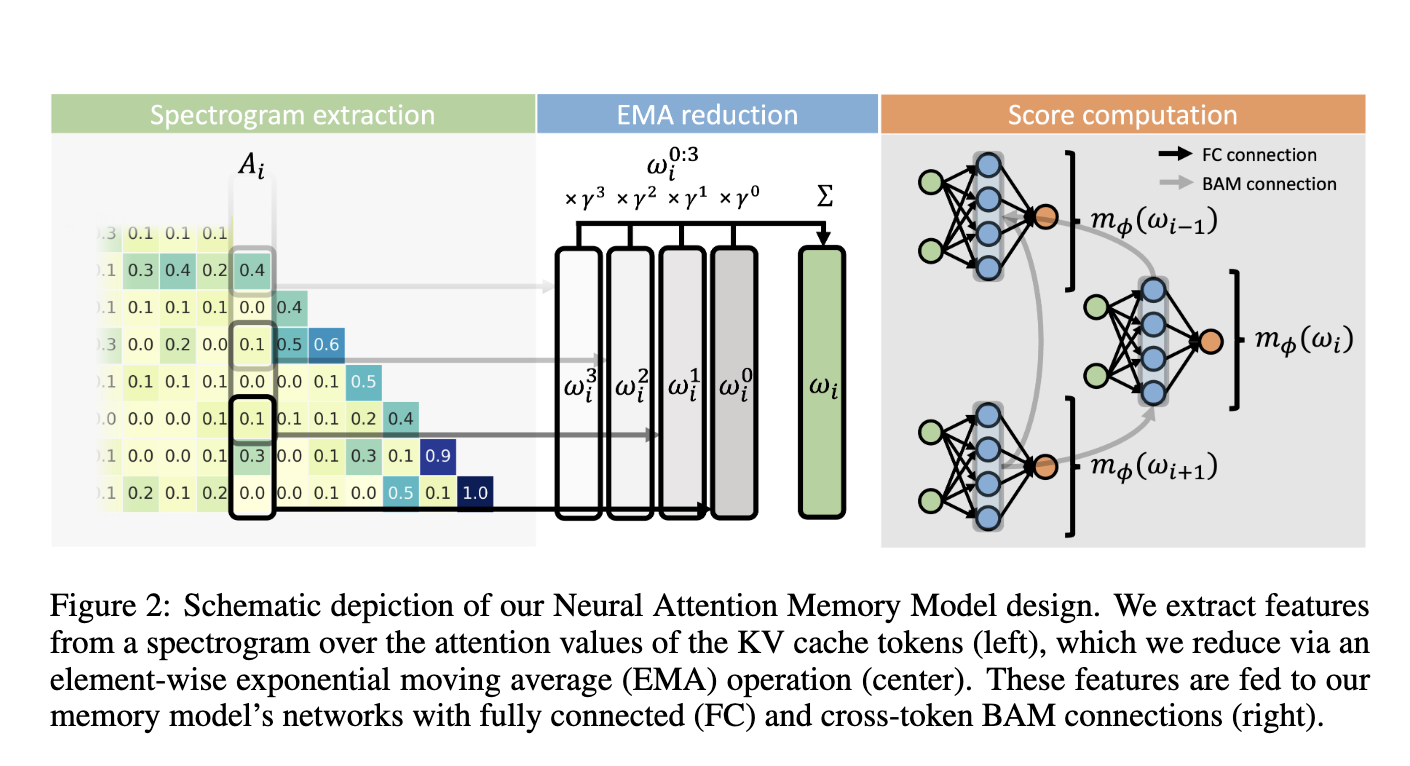
A analysis workforce from Sakana AI, Japan, has launched Neural Consideration Reminiscence Fashions (NAMMs). NAMMs are a brand new class of reminiscence administration fashions that dynamically optimize the KV cache in transformers. As a substitute of counting on hand-designed guidelines, NAMMs study token significance via evolutionary optimization. By conditioning on the eye matrices of transformers, NAMMs allow every layer to retain solely probably the most related tokens, enhancing each effectivity and efficiency with out altering the bottom transformer structure. This universality makes NAMMs relevant to any transformer-based mannequin, as their design relies upon solely on options extracted from consideration matrices.
The methodology behind NAMMs entails extracting significant options from the eye matrix utilizing a spectrogram-based approach. The researchers apply the Quick-Time Fourier Rework (STFT) to compress the eye values right into a spectrogram illustration. This compact illustration captures how token significance evolves throughout the eye span. The spectrogram options are then diminished utilizing an exponential transferring common (EMA) operation to attenuate complexity. NAMMs use a light-weight neural community to judge these compressed options and assign a variety rating to every token. Tokens with low choice scores are evicted from the KV cache, liberating up reminiscence whereas guaranteeing efficiency isn’t compromised.
A crucial innovation in NAMMs is the introduction of backward consideration mechanisms. This design permits the community to check tokens effectively, preserving solely probably the most related occurrences whereas discarding redundant ones. By leveraging cross-token communication, NAMMs optimize reminiscence utilization dynamically throughout layers, guaranteeing transformers retain essential long-range data for every process.
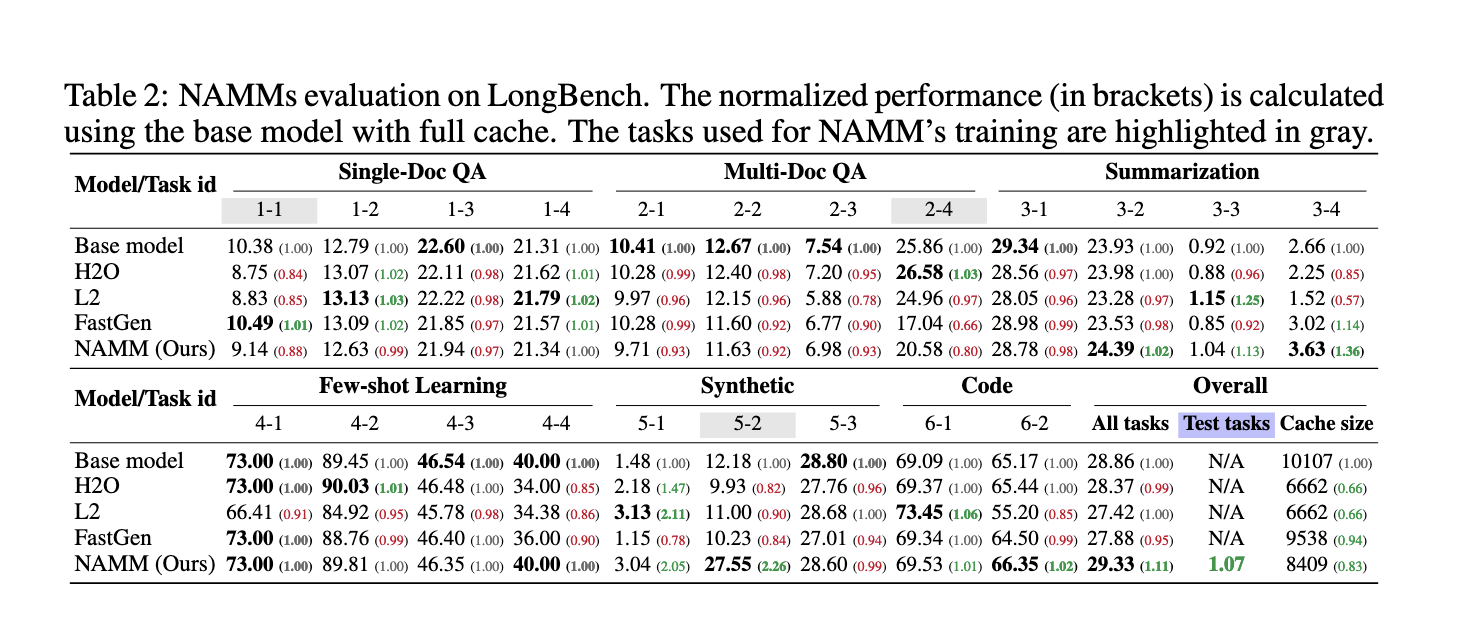
The efficiency of NAMMs was rigorously evaluated throughout a number of benchmarks, showcasing their superiority over present strategies. On the LongBench benchmark, NAMMs improved normalized efficiency by 11% whereas lowering the KV cache dimension to 25% of the unique mannequin. Equally, on the difficult InfiniteBench benchmark, the place common enter lengths exceed 200,000 tokens, NAMMs outperformed baseline fashions by rising efficiency from 1.05% to 11%. This consequence highlights NAMMs’ skill to scale successfully for long-context duties with out sacrificing accuracy. Furthermore, the reminiscence footprint of NAMMs on InfiniteBench was diminished to roughly 40% of the unique dimension, demonstrating their effectivity in managing lengthy sequences.
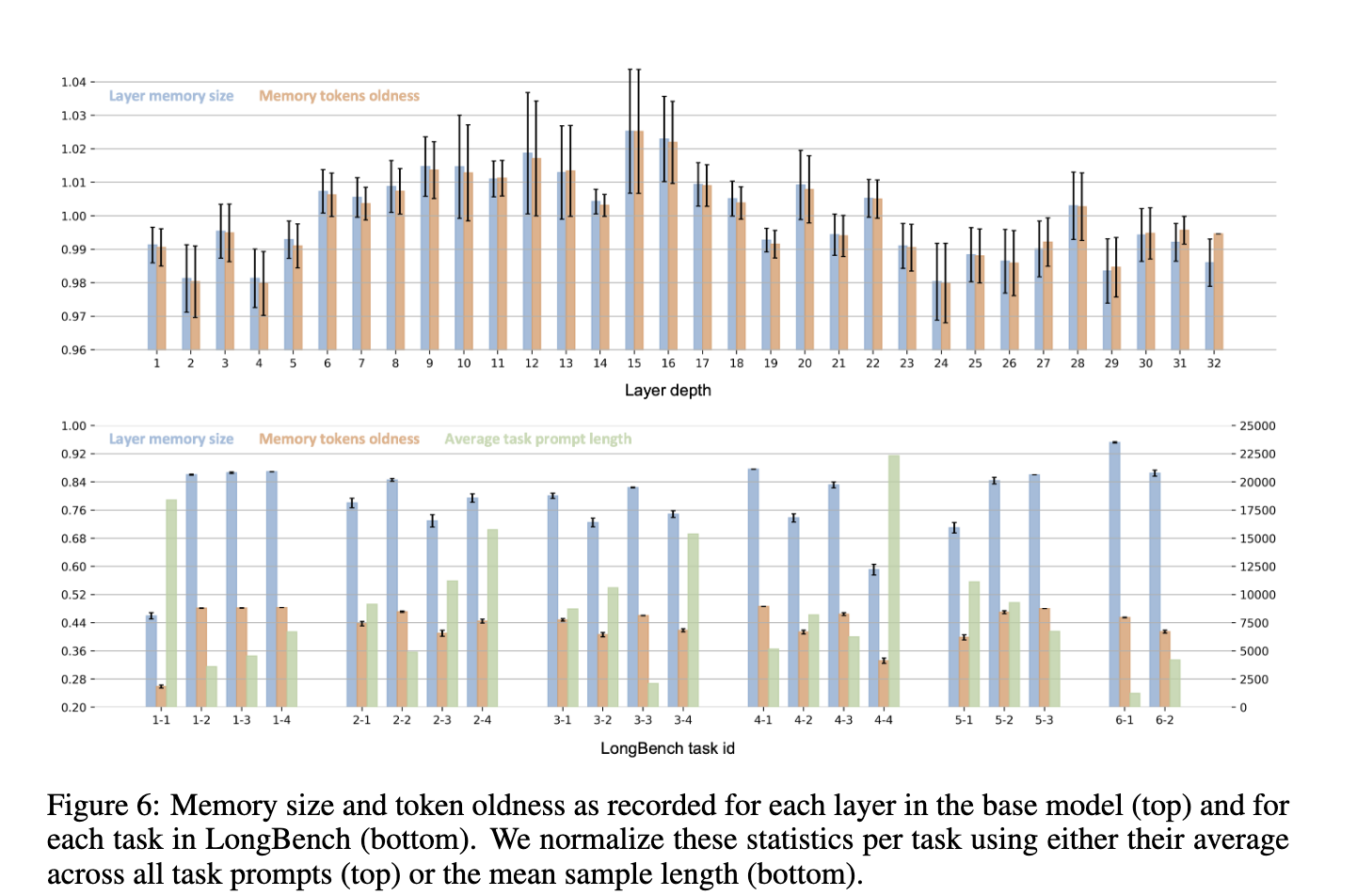
The researchers additional validated NAMMs’ versatility via zero-shot switch experiments. NAMMs skilled solely on pure language duties had been utilized to new transformers and enter modalities, together with laptop imaginative and prescient and reinforcement studying fashions. As an example, when examined with a Llava Subsequent Video 7B mannequin on lengthy video understanding duties, NAMMs improved the bottom mannequin’s efficiency whereas sustaining a diminished reminiscence footprint. In reinforcement studying experiments utilizing Resolution Transformers on steady management duties, NAMMs achieved a median efficiency achieve of 9% throughout a number of duties, demonstrating their skill to discard unhelpful data and enhance decision-making capabilities.
In conclusion, NAMMs present a strong resolution to the problem of long-context processing in transformers. By studying environment friendly reminiscence administration methods via evolutionary optimization, NAMMs overcome the constraints of hand-designed heuristics. The outcomes exhibit that transformers outfitted with NAMMs obtain superior efficiency whereas considerably lowering computational prices. Their common applicability and success throughout numerous duties spotlight their potential to advance transformer-based fashions throughout a number of domains, marking a major step towards environment friendly long-context modeling.
Take a look at the Paper and Details. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.