Multi-vector retrieval has emerged as a vital development in info retrieval, significantly with the adoption of transformer-based fashions. In contrast to single-vector retrieval, which encodes queries and paperwork as a single dense vector, multi-vector retrieval permits for a number of embeddings per doc and question. This method gives a extra granular illustration, bettering search accuracy and retrieval high quality. Over time, researchers have developed varied strategies to reinforce the effectivity and scalability of multi-vector retrieval, addressing computational challenges in dealing with massive datasets.
A central drawback in multi-vector retrieval is balancing computational effectivity with retrieval efficiency. Conventional retrieval strategies are quick however often fail to retrieve complicated semantic relationships inside paperwork. Alternatively, correct multi-vector retrieval strategies expertise excessive latency primarily as a result of a number of calculations of similarity measures are required. The problem, subsequently, is to make a system such that the fascinating options of the multi-vector retrieval are maintained. But, the computational overhead is lowered considerably to make a real-time search potential for a large-scale software.
A number of enhancements have been launched to reinforce effectivity in multi-vector retrieval. ColBERT launched a late interplay mechanism to optimize retrieval, making query-document interactions computationally environment friendly. Thereafter, ColBERTv2 and PLAID additional elaborated on the concept by introducing increased pruning strategies and optimized kernels in C++. Concurrently, the XTR framework from Google DeepMind has simplified the scoring course of with out requiring an unbiased stage for doc gathering. Nonetheless, such fashions had been nonetheless efficiency-prone, primarily token retrieval and doc scoring, making the related latency and utilization of assets increased.
A analysis workforce from ETH Zurich, UC Berkeley, and Stanford College launched WARP, a search engine designed to optimize XTR-based ColBERT retrieval. WARP integrates developments from ColBERTv2 and PLAID whereas incorporating distinctive optimizations to enhance retrieval effectivity. The important thing improvements of WARP embody WARPSELECT, a way for dynamic similarity imputation that eliminates pointless computations, an implicit decompression mechanism that reduces reminiscence operations, and a two-stage discount course of for sooner scoring. These enhancements permit WARP to ship vital pace enhancements with out compromising retrieval high quality.
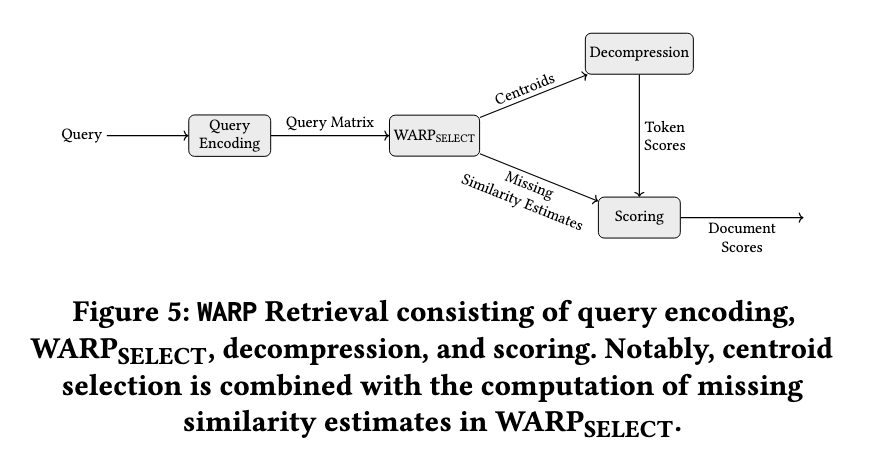
The WARP retrieval engine makes use of a structured optimization method to enhance retrieval effectivity. First, it encodes the queries and paperwork utilizing a fine-tuned T5 transformer and produces token-level embeddings. Then, WARPSELECT decides on essentially the most related doc clusters for a question whereas avoiding redundant similarity calculations. As an alternative of specific decompression throughout retrieval, WARP performs implicit decompression to cut back computational overhead considerably. A two-stage discount technique is then used to calculate doc scores effectively. This aggregation of token-level scores after which summing up the document-level scores with dynamically dealing with lacking similarity estimates makes WARP extremely environment friendly in comparison with different retrieval engines.
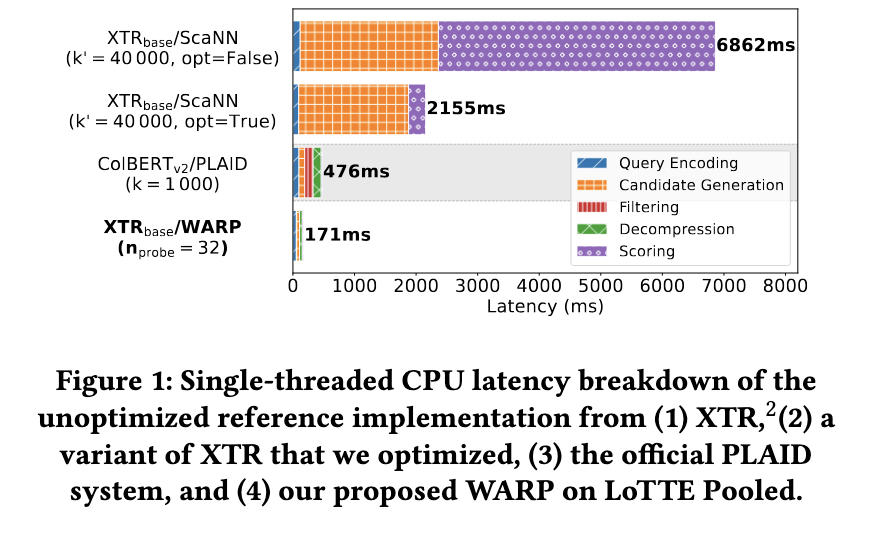
WARP considerably improves retrieval efficiency whereas decreasing question processing time considerably. Experimental outcomes present that WARP reduces end-to-end question latency by 41 instances in contrast with the XTR reference implementation on LoTTE Pooled and brings question response instances down from over 6 seconds to 171 milliseconds with a single thread. Furthermore, WARP can obtain a threefold speedup over ColBERTv2/PLAID. Index measurement can be optimized, reaching 2x-4x much less storage necessities than the baseline strategies. Furthermore, WARP outperforms earlier retrieval fashions whereas holding prime quality throughout benchmark datasets.
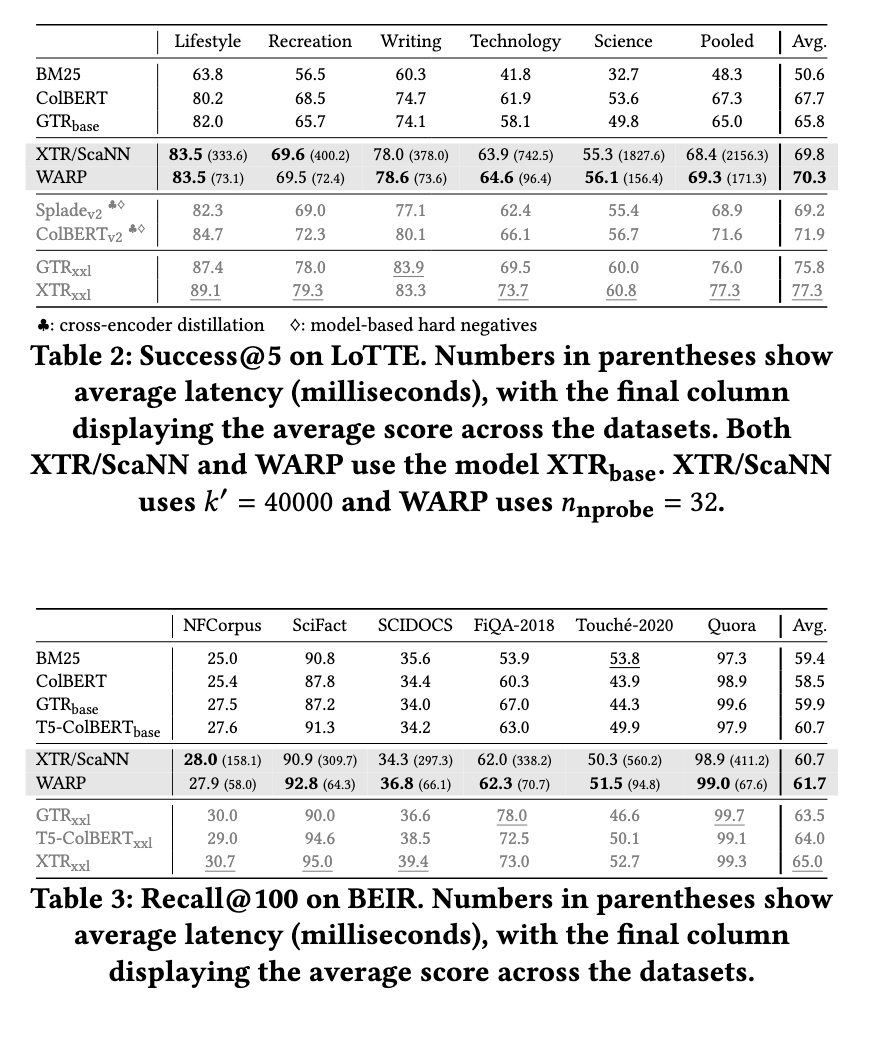
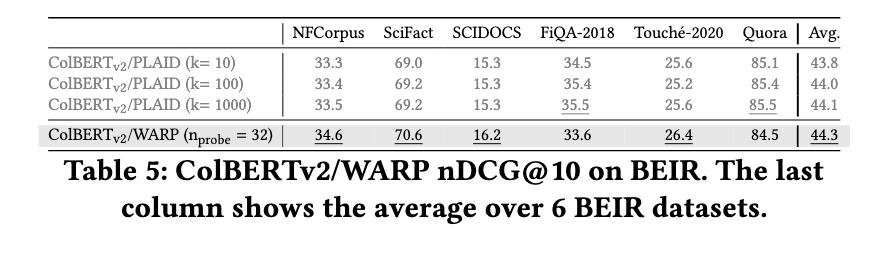
The event of WARP marks a big step ahead in multi-vector retrieval optimization. The analysis workforce has efficiently improved each pace and effectivity by integrating novel computational strategies with established retrieval frameworks. The research highlights the significance of decreasing computational bottlenecks whereas sustaining retrieval high quality. The introduction of WARP paves the way in which for future enhancements in multi-vector search programs, providing a scalable resolution for high-speed and correct info retrieval.
Take a look at the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 70k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.