Creating efficient multi-modal AI techniques for real-world functions requires dealing with various duties resembling fine-grained recognition, visible grounding, reasoning, and multi-step problem-solving. Current open-source multi-modal language fashions are discovered to be wanting in these areas, particularly for duties that contain exterior instruments resembling OCR or mathematical calculations. The abovementioned limitations can largely be attributed to single-step-oriented datasets that can’t present a coherent framework for a number of steps of reasoning and logical chains of actions. Overcoming these will probably be indispensable for unlocking true potential in utilizing multi-modal AI on complicated ranges.
Present multi-modal fashions typically depend on instruction tuning with direct-answer datasets or few-shot prompting approaches. The proprietary techniques, like GPT-4, have demonstrated the flexibility to cause by CoTA chains successfully. On the identical time, the open-source fashions face challenges from a scarcity of datasets and integration with instruments. The sooner efforts, resembling LLaVa-Plus and Visible Program Distillation, have been additionally restricted by small dataset sizes, poor-quality coaching information, and a give attention to easy question-answering duties, which limits them to extra complicated multi-modal issues that require extra refined reasoning and power utility.
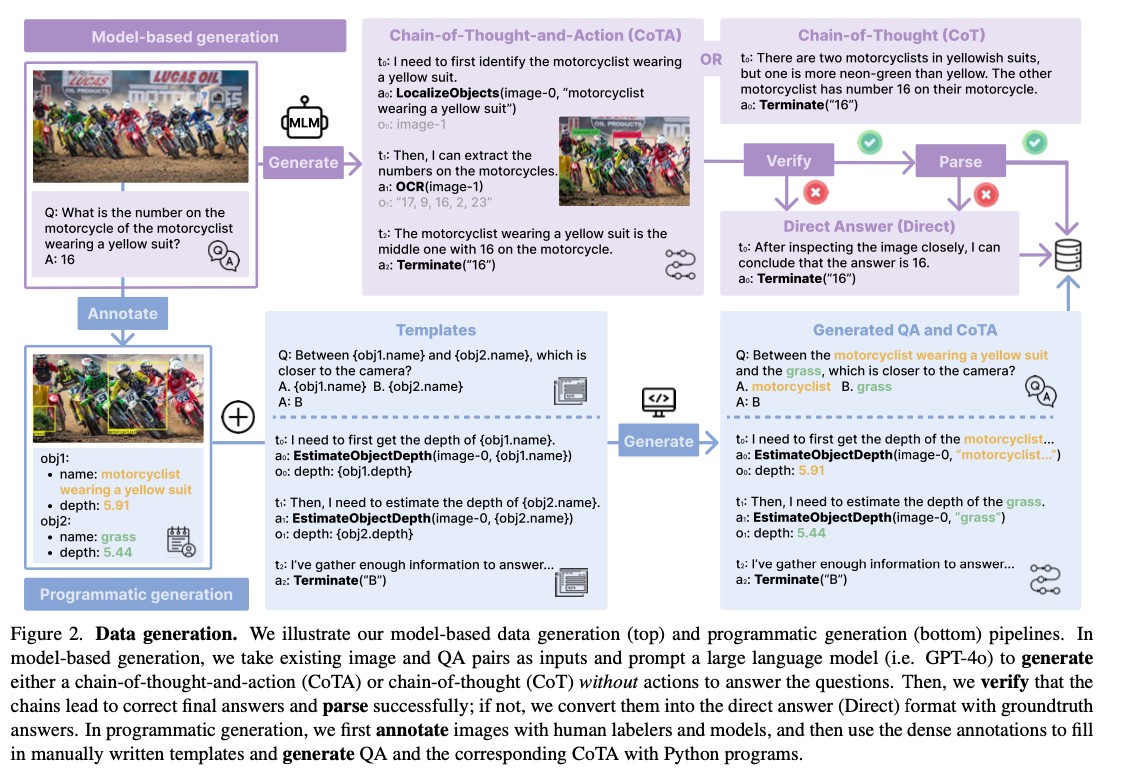
Researchers from the College of Washington and Salesforce Analysis have developed TACO, an progressive framework for coaching multi-modal motion fashions utilizing artificial CoTA datasets. This work introduces a number of key developments to deal with the restrictions of prior strategies. First, over 1.8 million traces have been generated utilizing GPT-4 and packages in Python, whereas a subset of 293K examples was curated to current prime quality after rigorous filtering methods. These examples make sure the inclusion of various reasoning and motion sequences important for multi-modal studying. Second, TACO incorporates a strong set of 15 instruments, together with OCR, object localization, and mathematical solvers, enabling the fashions to deal with complicated duties successfully. Third, superior filtering and data-mixing methods additional optimize the dataset, emphasizing reasoning-action integration and fostering superior studying outcomes. This framework reinterprets multi-modal studying by enabling fashions to supply coherent multi-step reasoning whereas seamlessly integrating actions, thereby establishing a brand new benchmark for efficiency in intricate situations.

The event of TACO concerned coaching on a rigorously curated CoTA dataset with 293K situations sourced from 31 completely different origins, together with Visible Genome. These datasets include a variety of duties resembling mathematical reasoning, optical character recognition, and detailed visible understanding. It’s extremely heterogeneous, with the instruments offered together with object localization and language-based solvers that enable a variety of reasoning and motion duties. The coaching structure mixed LLaMA3 because the linguistic foundation with CLIP because the visible encoder thus establishing a powerful multi-modal framework. Nice-tuning established hyperparameter tuning that targeted on reducing studying charges and growing the variety of epochs for coaching to ensure that the fashions might adequately resolve complicated multi-modal challenges.
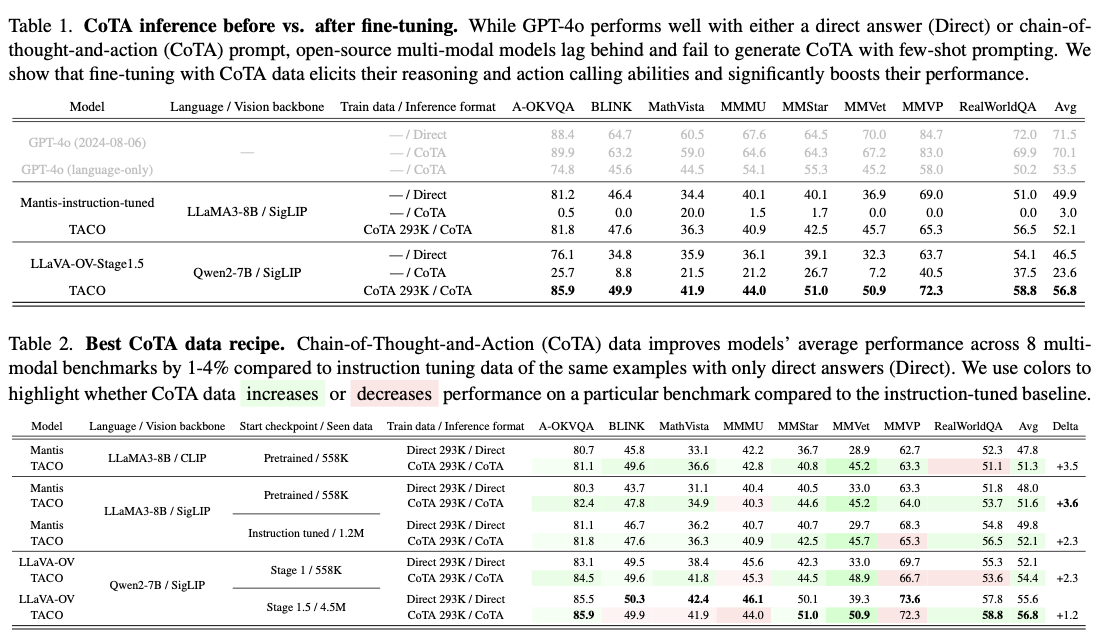
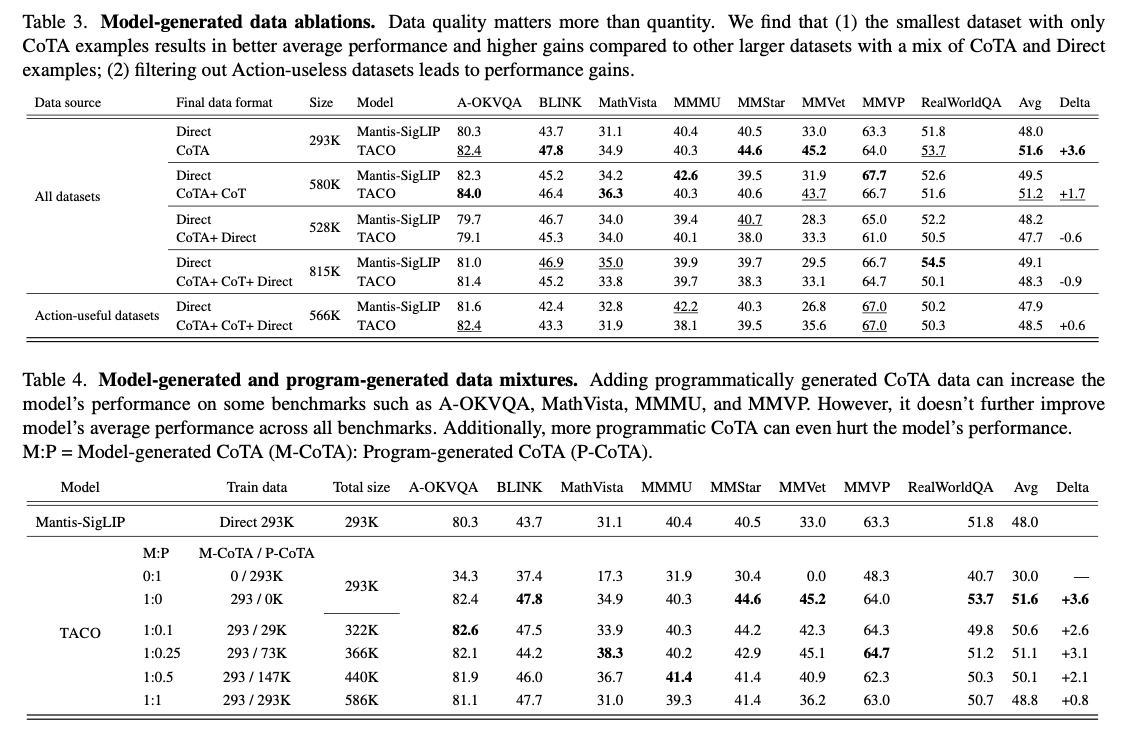
TACO’s efficiency throughout eight benchmarks demonstrates its substantial affect on advancing multi-modal reasoning capabilities. The system achieved a mean accuracy enchancment of three.6% over instruction-tuned baselines, with positive factors as excessive as 15% on MMVet duties that contain OCR and mathematical reasoning. Notably, the high-quality 293K CoTA dataset outperformed bigger, much less refined datasets, underscoring the significance of focused information curation. Additional efficiency enhancements are achieved by changes in hyperparameter methods, together with tuning of imaginative and prescient encoders and optimization of studying charges. Desk 2: Outcomes present glorious performances by TACO in comparison with benchmarks, the latter was discovered to be exceptionally higher in complicated duties involving integration of reasoning and motion.

TACO introduces a brand new methodology for multi-modal motion modeling that successfully addresses the extreme deficiencies of each reasoning and tool-based actions by high-quality artificial datasets and progressive coaching methodologies. The analysis overcomes the constraints of conventional instruction-tuned fashions, and its developments are poised to alter the face of real-world functions starting from visible query answering to complicated multi-step reasoning duties.
Take a look at the Paper, GitHub Page, and Project Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 65k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.