Generative AI faces a crucial problem in balancing autonomy and controllability. Whereas autonomy has superior considerably via highly effective generative fashions, controllability has turn into a focus for machine studying researchers. Textual content-based management has turn into significantly vital as pure language affords an intuitive interface between people and machines. This strategy has enabled outstanding functions throughout picture enhancing, audio synthesis, and video technology. Current text-to-data generative fashions, significantly these using diffusion strategies, have proven spectacular outcomes by using semantic insights from in depth data-text pair datasets. Nevertheless, vital boundaries come up in low-resource conditions the place acquiring ample text-paired information turns into prohibitively costly or difficult on account of advanced information constructions. Important domains like molecular information, movement seize, and time collection usually lack ample textual content labels, which restricts supervised studying capabilities and impedes the deployment of superior generative fashions. These limitations predictably end in poor technology high quality, mannequin overfitting, bias, and restricted output range—revealing a considerable hole in optimizing textual content representations for higher alignment in data-limited contexts.
The low-resource state of affairs has prompted a number of mitigation approaches, every with inherent limitations. Knowledge augmentation strategies usually fail to precisely align artificial information with authentic textual content descriptions and threat overfitting whereas growing computational calls for in diffusion models. Semi-supervised studying struggles with the inherent ambiguities in textual information, making appropriate interpretation difficult when processing unlabeled samples. Transfer learning, whereas promising for restricted datasets, ceaselessly suffers from catastrophic forgetting, the place the mannequin loses beforehand acquired information because it adapts to new textual content descriptions. These methodological shortcomings spotlight the necessity for extra sturdy approaches particularly designed for text-to-data technology in low-resource environments.
On this paper, researchers from Salesforce AI Analysis current Text2Data which introduces a diffusion-based framework that enhances text-to-data controllability in low-resource situations via a two-stage strategy. First, it masters information distribution utilizing unlabeled information through an unsupervised diffusion mannequin, avoiding the semantic ambiguity widespread in semi-supervised strategies. Second, it implements controllable fine-tuning on text-labeled information with out increasing the coaching dataset. As a substitute, Text2Data employs a constraint optimization-based studying goal that forestalls catastrophic forgetting by protecting mannequin parameters near their pre-fine-tuning state. This distinctive framework successfully makes use of each labeled and unlabeled information to keep up fine-grained information distribution whereas attaining superior controllability. Theoretical validation helps the optimization constraint choice and generalization bounds, with complete experiments throughout three modalities demonstrating Text2Data’s superior technology high quality and controllability in comparison with baseline strategies.
Text2Data addresses controllable information technology by studying the conditional distribution pθ(x|c) the place restricted paired information creates optimization challenges. The framework operates in two distinct phases as illustrated within the determine under. Initially, it makes use of extra ample unlabeled information to be taught the marginal distribution pθ(x), acquiring optimum parameters θ̂ inside set Θ. This strategy exploits the mathematical relationship between marginal and conditional distributions, the place pθ(x) approximates the anticipated worth of pθ(x|c) over the textual content distribution. Subsequently, Text2Data fine-tunes these parameters utilizing the obtainable labeled data-text pairs whereas implementing constraint optimization to maintain the up to date parameters θ̂’ throughout the intersection of Θ and Θ’. This constraint ensures the mannequin maintains information of the general information distribution whereas gaining textual content controllability, successfully stopping catastrophic forgetting that usually happens throughout fine-tuning processes.
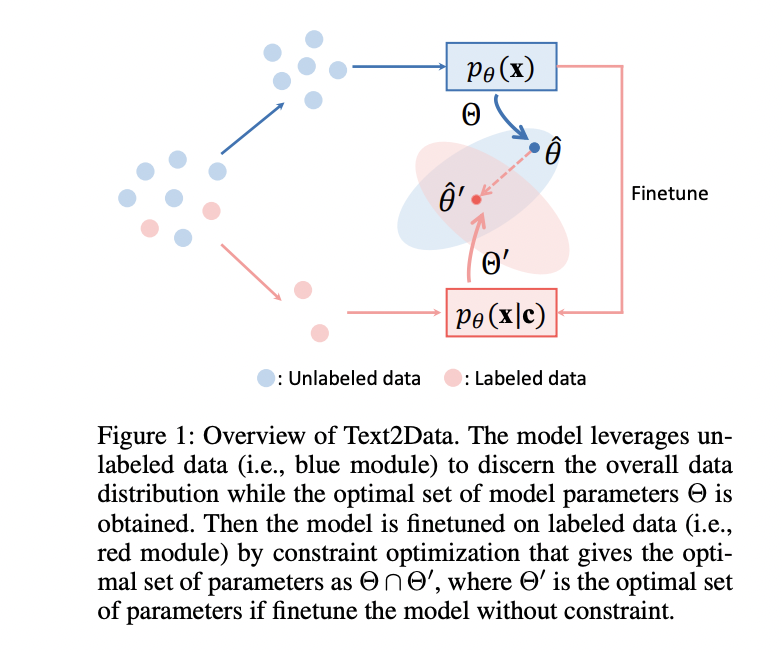
Text2Data implements its two-phase strategy by first utilizing all obtainable information with NULL tokens as circumstances to be taught the final information distribution. This enables the mannequin to optimize pθ(x|∅), which successfully equals pθ(x) for the reason that NULL token is unbiased of x. The second part introduces a constraint optimization framework that fine-tunes the mannequin on text-labeled information whereas stopping parameter drift from the beforehand discovered distribution. Mathematically, that is expressed as minimizing the unfavourable log-likelihood of conditional likelihood pθ(x|c) topic to the constraint that the marginal distribution efficiency stays near the optimum worth ξ established throughout the first part. This constraint-based strategy straight addresses catastrophic forgetting by guaranteeing the mannequin parameters stay inside an optimum set the place each normal information illustration and text-specific controllability can coexist—primarily fixing a lexicographic optimization downside that balances these competing aims.
It implements classifier-free diffusion steerage by reworking the theoretical goal into sensible loss capabilities. The framework optimizes three key parts: L1(θ) for normal information distribution studying, L’1(θ) for distribution preservation on labeled information, and L2(θ) for text-conditioned technology. These are empirically estimated utilizing obtainable information samples. The lexicographic optimization course of, detailed in Algorithm 1, balances these aims by dynamically adjusting gradient updates with a parameter λ that enforces constraints whereas permitting efficient studying. This strategy makes use of a complicated replace rule the place θ is modified based mostly on a weighted mixture of gradients from each aims. The constraint will be relaxed throughout coaching to enhance convergence, recognizing that parameters needn’t be an actual subset of the unique parameter house however ought to stay proximal to protect distribution information whereas gaining controllability.

Text2Data gives theoretical underpinnings for its constraint optimization strategy via generalization bounds that validate parameter choice. The framework establishes that random variables derived from the diffusion course of are sub-Gaussian, enabling the formulation of rigorous confidence bounds. Theorem 0.2 delivers three crucial ensures: first, the empirical parameter set throughout the confidence sure absolutely encompasses the true optimum set; second, the empirical answer competes successfully with the theoretical optimum on the first goal; and third, the empirical answer maintains affordable adherence to the theoretical constraint. The sensible implementation introduces a leisure parameter ρ that adjusts the strictness of the constraint whereas protecting it throughout the mathematically justified confidence interval. This leisure acknowledges real-world circumstances the place acquiring quite a few unlabeled samples is possible, making the boldness sure fairly tight even when dealing with fashions with thousands and thousands of parameters. Experiments with movement technology involving 45,000 samples and 14 million parameters verify the framework’s sensible viability.

Text2Data demonstrates superior controllability throughout a number of domains in comparison with baseline strategies. In molecular technology, it achieves decrease Imply Absolute Error (MAE) for all properties in comparison with EDM-finetune and EDM, significantly excelling with properties like ϵLUMO and Cv. For movement technology, Text2Data surpasses MDM-finetune and MDM in R Precision and Multimodal Distance metrics. In time collection technology, it constantly outperforms DiffTS-finetune and DiffTS throughout all evaluated properties. Past controllability, Text2Data maintains distinctive technology high quality, exhibiting enhancements in molecular validity, stability, movement technology range, and distribution alignment in time collection. These outcomes validate Text2Data’s effectiveness in mitigating catastrophic forgetting whereas preserving technology high quality.

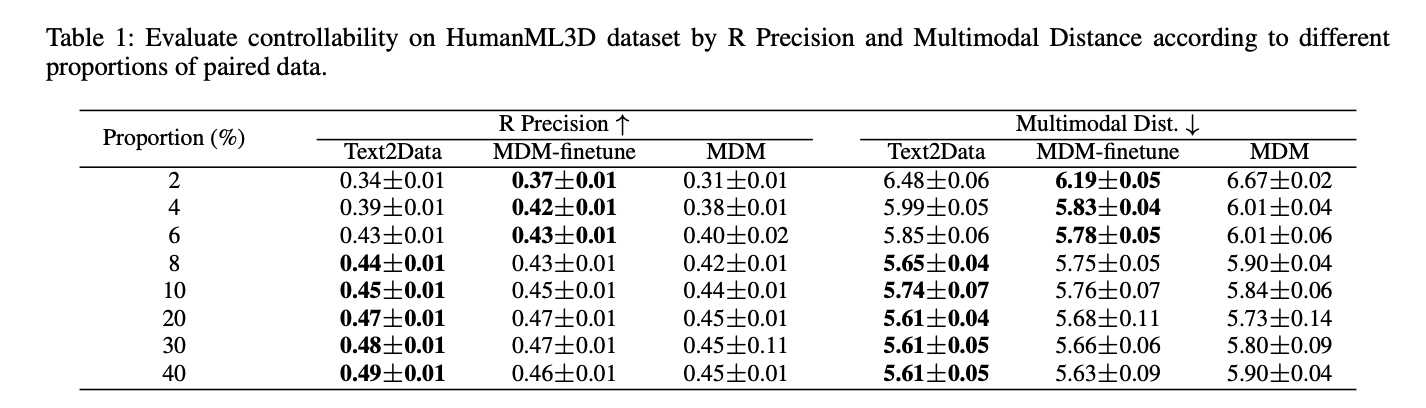
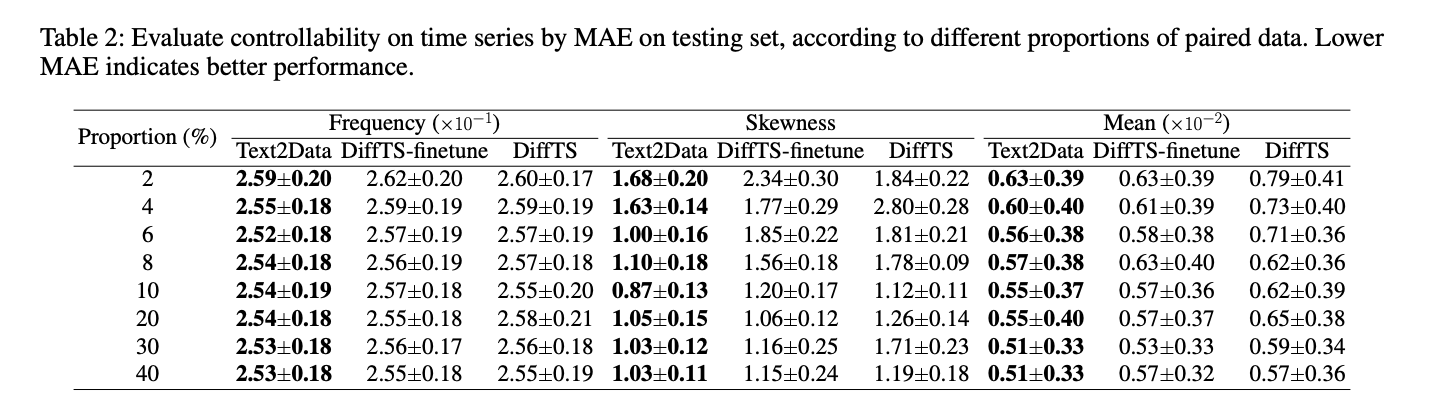
Text2Data successfully addresses the challenges of text-to-data technology in low-resource situations throughout a number of modalities. By initially using unlabeled information to understand the general information distribution after which implementing constraint optimization throughout fine-tuning on labeled information, the framework efficiently balances controllability with distribution preservation. This strategy prevents catastrophic forgetting whereas sustaining technology high quality. Experimental outcomes constantly display Text2Data’s superiority over baseline strategies in each controllability and technology high quality. Although carried out with diffusion fashions, Text2Data’s rules will be readily tailored to different generative architectures.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.