Out of the varied strategies employed in doc search methods, “retrieve and rank” has gained fairly some reputation. Utilizing this technique, the outcomes of a retrieval mannequin are re-ordered in keeping with a re-ranker. Moreover, within the wake of developments in generative AI and the event of Giant Language Fashions (LLMs), rankers at the moment are able to performing listwise reranking duties after analyzing advanced patterns in language. Nonetheless, a vital downside exists that seems trivial however limits the general effectiveness of those cascading methods.
The problem of the bounded recall downside, the place a doc is irrevocably excluded from the ultimate ranked listing if it wasn’t retrieved within the preliminary part, causes the lack of high-potential info. To resolve this downside, researchers got here up with an adaptive retrieval course of. Adaptive Retrieval (AR) differentiates itself from earlier works by leveraging the ranker’s assessments to broaden the retrieval set dynamically. A clustering speculation is utilized on this course of to group related paperwork that could be related to a question. Adaptive Retrieval (AR) might be higher understood as a pseudo-relevance suggestions mechanism that enhances the probability of together with pertinent paperwork which will have been omitted in the course of the preliminary retrieval.
Though AR serves as a strong answer in cascading methods, modern work on this vertical operates beneath the belief that the relevance rating relies upon solely on the doc and question, implying that one doc’s rating is computed independently of others. Then again, LLM-based rating strategies use alerts from the whole ranked listing to find out relevance. This text discusses the newest analysis that merges the advantages of LLMs with AR.
Researchers from the L3S Analysis Middle, Germany, and the College of Glasgow have put forth SlideGar: Sliding Window-based Adaptive Retrieval to combine AR with LLMs whereas accounting for the elemental variations between their pointwise and listwise approaches. SlideGar modifies AR such that the ensuing rating operate outputs a ranked order of paperwork reasonably than discrete relevance scores. The proposed algorithm merges outcomes from the preliminary rating with suggestions paperwork offered by probably the most related paperwork recognized as much as that time.
The SlideGar algorithm makes use of AR strategies like graph-based adaptive retrieval (Gar) and question affinity modeling-based adaptive retrieval (Quam) to search out doc neighbors in a continuing period of time. For LLM rating, the authors make use of a sliding window to beat the constraint of enter context. SlideGar processes the preliminary pool of paperwork given by the retriever for a selected question and, for a predefined size and step dimension, ranks the highest w paperwork from left to proper utilizing a listwise ranker. These paperwork are then faraway from the pool. The authors used the reciprocal of the rank as a pseudo-score for the paperwork.
The authors employed the MSMARCO corpus knowledge for sensible functions and evaluated its efficiency on REC Deep Studying 2019 and 2020 question units. In addition they used the newest variations of those datasets and de-duplicated them to take away redundancies. Quite a lot of sparse and dense retrievers have been utilized. For rankers, the authors employed completely different listwise rankers, together with each zero-shot and fine-tuned fashions. The authors leveraged the open-source Python library, ReRankers, to use these listwise re-rankers.
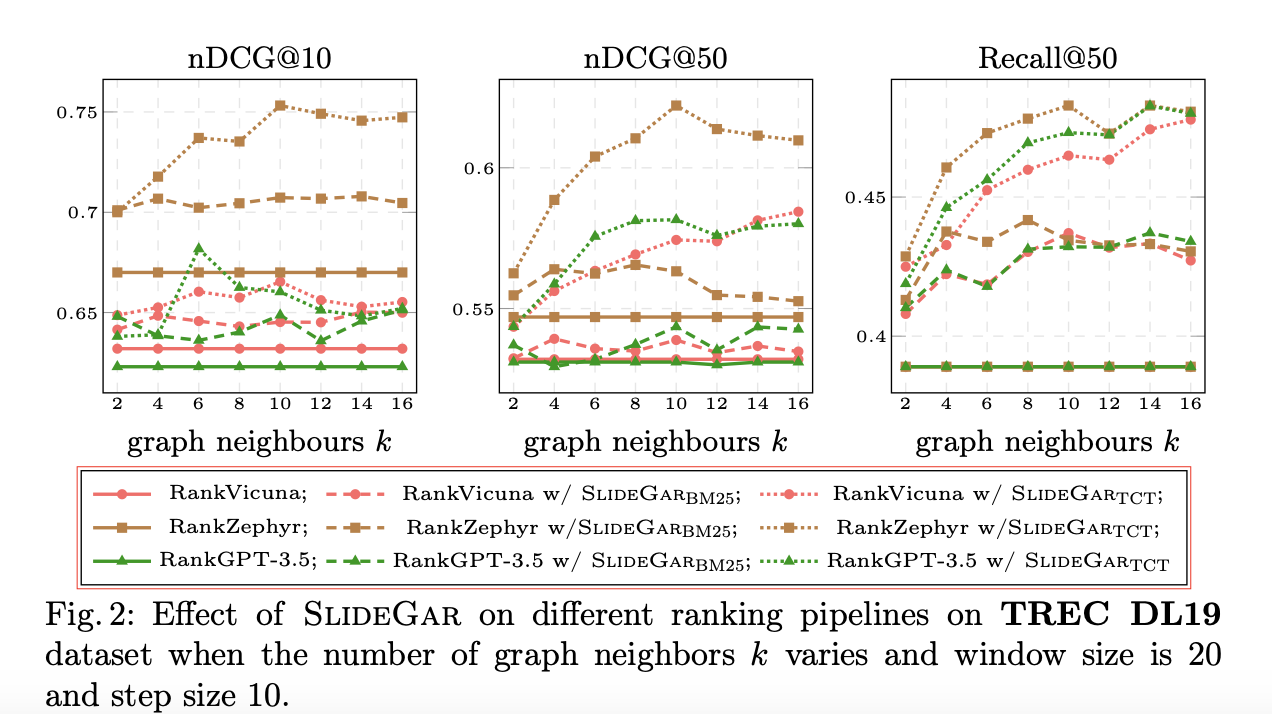
After conducting an in depth set of experiments throughout numerous LLM re-rankers, first-stage retrievers, and suggestions paperwork, the authors ascertained that SlideGar improved the nDGC@10 rating by as much as 13% and recall by 28%, with a continuing variety of LLM inferences over the SOTA listwise rankers. Moreover, concerning computation, the authors found that the proposed technique provides negligible latency (a mere 0.02%).
Conclusion: On this analysis paper, the authors suggest a brand new algorithm, SlideGar, that enables LLM re-rankers to handle the problem of bounded recall in retrieval. SlideGar merges the functionalities of AR and LLM re-rankers to enrich one another. This work paves the way in which for researchers to additional discover and adapt LLMs for rating functions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 65k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Adeeba Alam Ansari is at the moment pursuing her Twin Diploma on the Indian Institute of Know-how (IIT) Kharagpur, incomes a B.Tech in Industrial Engineering and an M.Tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of expertise to empower society and promote welfare by way of revolutionary options pushed by empathy and a deep understanding of real-world challenges.