Giant Language Fashions (LLMs) have turn out to be a cornerstone of synthetic intelligence, driving developments in pure language processing and decision-making duties. Nevertheless, their in depth energy calls for, ensuing from excessive computational overhead and frequent exterior reminiscence entry, considerably hinder their scalability and deployment, particularly in energy-constrained environments akin to edge units. This escalates the price of operation whereas additionally limiting accessibility to those LLMs, which subsequently requires energy-efficient approaches designed to deal with billion-parameter fashions.
Present approaches to scale back the computational and reminiscence wants of LLMs are primarily based both on general-purpose processors or on GPUs, with a mixture of weight quantization and sparsity-aware optimizations. These have confirmed comparatively profitable in attaining some financial savings however are nonetheless closely reliant on exterior reminiscence which incurs vital vitality overhead and fails to ship the low-latency efficiency needed for a lot of real-time software runs. Such approaches are much less well-suited to resource-constrained or sustainable AI techniques.
To handle these limitations, researchers on the Korea Superior Institute of Science and Know-how (KAIST) developed Slim-Llama, a extremely environment friendly Software-Particular Built-in Circuit (ASIC) designed to optimize the deployment of LLMs. This novel processor makes use of binary/ternary quantization to scale back the precision of mannequin weights from actual to 1 or 2 bits, thus minimizing vital reminiscence and computational calls for, leaving efficiency intact. This makes use of a Sparsity-aware Look-up Desk or SLT that permits sparse information administration. It employs output reuses and vector indexing with optimizations in order that repeated process redundancy optimizes information flows. Thereby, this checklist of traits removes widespread limitations to realize the everyday technique. They produce an energy-friendly scalable assist mechanism for dealing with execution duties inside billions of LLMs.
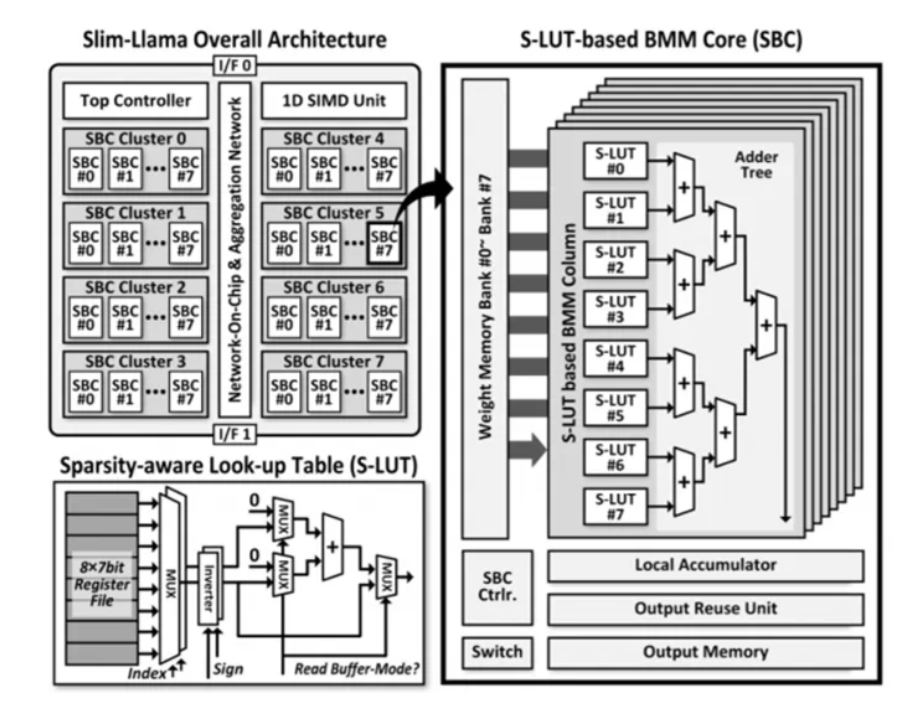
Slim-Llama is manufactured utilizing Samsung’s 28nm CMOS expertise, with a compact die space of 20.25mm² and 500KB of on-chip SRAM. This design removes all dependency on exterior reminiscence; that is the one useful resource by which conventional techniques are shedding a lot vitality. There’s bandwidth assist by it with as much as 1.6GB/s in 200MHz frequencies so information administration by means of this mannequin is easy in addition to very environment friendly. Slim-Llama is able to reaching a latency of 489 milliseconds utilizing the Llama 1-bit mannequin and helps fashions with as much as 3 billion parameters, so it’s properly positioned for right now’s functions of synthetic intelligence, which require each efficiency and effectivity. Essentially the most crucial architectural improvements are binary and ternary quantization, sparsity-aware optimization, and environment friendly information move administration of which obtain main effectivity good points with out compromising computational effectivity.
The outcomes spotlight the excessive vitality effectivity and efficiency capabilities of Slim-Llama. It achieves a 4.59x enchancment when it comes to vitality effectivity over earlier state-of-the-art options, whose energy consumption ranges from 4.69mW at 25MHz to 82.07mW at 200MHz. The processor achieves a peak of 4.92 TOPS at an effectivity of 1.31 TOPS/W, addressing the crucial requirement for energy-efficient {hardware} with large-scale AI fashions in place. Slim-Llama can course of billion-parameter fashions with minimal latency, thus offering a promising candidate for real-time functions. A benchmark desk, “Power Effectivity Comparability of Slim-Llama,” illustrates the efficiency relative to the baseline techniques when it comes to energy consumption, latency, and vitality effectivity, with Slim-Llama attaining 4.92 TOPS and 1.31 TOPS/W, respectively, thus largely outperforming baseline {hardware} options.
Slim-Llama is a brand new frontier in breaking by means of the vitality bottlenecks of deploying LLMs. This scalable and sustainable answer combines novel quantization strategies, sparsity-aware optimization, and enhancements in information move to fulfill trendy AI software wants. The proposed technique just isn’t solely about effectively deploying billion-parameter fashions but in addition opens the doorways for extra accessible and environmentally pleasant AI techniques by establishing a brand new benchmark for energy-efficient AI {hardware}.
Take a look at the Technical Details. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.