The processing necessities of LLMs pose appreciable challenges, notably for real-time makes use of the place quick response time is significant. Processing every query afresh is time-consuming and inefficient, necessitating enormous assets. AI service suppliers overcome the low efficiency through the use of a cache system that shops repeated queries in order that these could be answered immediately with out ready, optimizing effectivity whereas saving latency. Whereas rushing up response time, nevertheless, safety dangers additionally come up. Scientists have studied how LLM API caching habits might unwittingly reveal confidential data. They discovered that person queries and trade-secret mannequin data might leak by timing-based side-channel assaults primarily based on business AI companies’ caching insurance policies.
One of many key dangers of immediate caching is its potential to disclose details about earlier person queries. If cached prompts are shared amongst a number of customers, an attacker might decide whether or not another person not too long ago submitted an identical immediate primarily based on response time variations. The danger turns into even higher with international caching, the place one person’s immediate can result in a quicker response time for one more person submitting a associated question. By analyzing response time variations, researchers demonstrated how this vulnerability might enable attackers to uncover confidential enterprise knowledge, private data, and proprietary queries.
Varied AI service suppliers cache in a different way, however their caching insurance policies will not be essentially clear to customers. Some prohibit caching to single customers in order that cached prompts can be found to solely the person who posted them, thus not permitting knowledge to be shared amongst accounts. Others implement per-organization caching in order that a number of customers in a agency or group can share cached prompts. Whereas extra environment friendly, this additionally dangers leaking delicate data if some customers possess particular entry privileges. Probably the most threatening safety danger outcomes from international caching, whereby all API companies can entry the cached prompts. Because of this, an attacker can manipulate response time inconsistencies to find out earlier prompts submitted. Researchers found that almost all AI suppliers will not be clear with their caching insurance policies, so customers stay blind to the safety threats accompanying their queries.
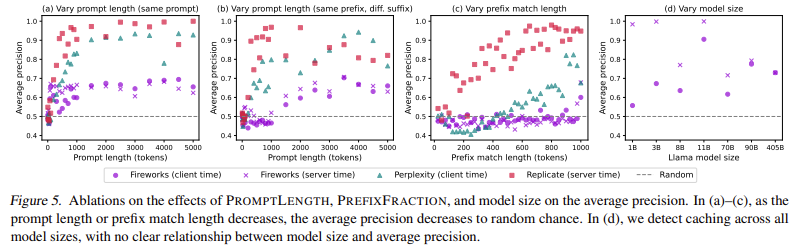
To research these points, the analysis workforce from Stanford College developed an auditing framework capable of detecting prompt caching at different access levels. Their technique concerned sending managed sequences of prompts to varied AI APIs and measuring response time variations. If a immediate have been cached, the response time could be noticeably quicker when resubmitted. They formulated statistical speculation checks to substantiate whether or not caching was occurring and to find out whether or not cache sharing prolonged past particular person customers. The researchers recognized patterns indicating caching by systematically adjusting immediate lengths, prefix similarities, and repetition frequencies. The auditing course of concerned testing 17 business AI APIs, together with these offered by OpenAI, Anthropic, DeepSeek, Fireworks AI, and others. Their checks targeted on detecting whether or not caching was carried out and whether or not it was restricted to a single person or shared throughout a broader group.
The auditing process consisted of two major checks: one to measure response occasions for cache hits and one other for cache misses. Within the cache-hit check, the identical immediate was submitted a number of occasions to watch if response velocity improved after the primary request. Within the cache-miss check, randomly generated prompts have been used to ascertain a baseline for uncached response occasions. The statistical evaluation of those response occasions offered clear proof of caching in a number of APIs. The researchers recognized caching habits in 8 out of 17 API suppliers. Extra critically, they found that 7 of those suppliers shared caches globally, which means that any person might infer the utilization patterns of one other person primarily based on response velocity. Their findings additionally revealed a beforehand unknown architectural element about OpenAI’s text-embedding-3-small mannequin—immediate caching habits indicated that it follows a decoder-only transformer construction, a bit of knowledge that had not been publicly disclosed.
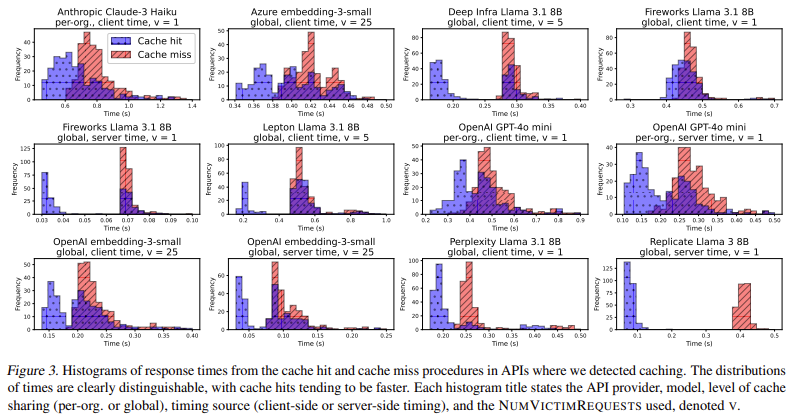
The efficiency analysis of cached versus non-cached prompts highlighted placing variations in response occasions. For instance, in OpenAI’s text-embedding-3-small API, the common response time for a cache hit was roughly 0.1 seconds, whereas cache misses resulted in delays of as much as 0.5 seconds. The researchers decided that cache-sharing vulnerabilities might enable attackers to realize near-perfect precision in distinguishing between cached and non-cached prompts. Their statistical checks produced extremely vital p-values, usually beneath 10⁻⁸, indicating a robust chance of caching habits. Furthermore, they discovered that in lots of circumstances, a single repeated request was enough to set off caching, with OpenAI and Azure requiring as much as 25 consecutive requests earlier than caching habits grew to become obvious. These findings counsel that API suppliers would possibly use distributed caching methods the place prompts will not be saved instantly throughout all servers however turn out to be cached after repeated use.
Key Takeaways from the Analysis embody the next:
- Immediate caching quickens responses by storing beforehand processed queries, however it might probably expose delicate data when caches are shared throughout a number of customers.
- World caching was detected in 7 of 17 API suppliers, permitting attackers to deduce prompts utilized by different customers by timing variations.
- Some API suppliers don’t publicly disclose caching insurance policies, which means customers could also be unaware that others are storing and accessing their inputs.
- The examine recognized response time discrepancies, with cache hits averaging 0.1 seconds and cache misses reaching 0.5 seconds, offering measurable proof of caching.
- The statistical audit framework detected caching with excessive precision, with p-values usually falling beneath 10⁻⁸, confirming the presence of systematic caching throughout a number of suppliers.
- OpenAI’s text-embedding-3-small mannequin was revealed to be a decoder-only transformer, a beforehand undisclosed element inferred from caching habits.
- Some API suppliers patched vulnerabilities after disclosure, however others have but to handle the problem, indicating a necessity for stricter business requirements.
- Mitigation methods embody limiting caching to particular person customers, randomizing response delays to stop timing inference, and offering higher transparency on caching insurance policies.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 80k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Deal with Authorized Considerations in AI Datasets
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.