LLMs primarily based on transformer architectures, comparable to GPT and LLaMA sequence, have excelled in NLP duties resulting from their in depth parameterization and huge coaching datasets. Nonetheless, analysis signifies that not all realized parameters are essential to retain efficiency, prompting the event of post-training compression methods to boost effectivity with out considerably lowering inference high quality. For instance, the LASER mannequin makes use of singular worth decomposition (SVD) to compress feedforward community (FFN) weight matrices by eradicating components with minimal singular values, lowering weight noise from coaching. Nonetheless, LASER solely targets particular person weight matrices, limiting its capacity to make the most of shared info between them.
Researchers at Imperial Faculty London launched a novel framework to boost the reasoning talents of LLMs by compressing the Multi-Head Consideration (MHA) block by way of multi-head tensorisation and Tucker decomposition. This strategy enforces a shared higher-dimensional subspace throughout consideration heads, enabling structured denoising and compression, with compression charges reaching as much as 250x with out requiring extra knowledge or fine-tuning. In contrast to current strategies targeted on FFN weights, this methodology addresses MHA limitations by leveraging area information about consideration heads’ shared and specialised roles. Intensive checks on benchmark datasets demonstrated improved reasoning in each encoder and decoder architectures, alongside compatibility with FFN-based methods.
The research adopts mathematical notations generally utilized in earlier works, with scalars, vectors, matrices, and tensors represented as a and A, respectively. Operations comparable to matrix transpose, Frobenius norm, and tensor mode-n product are outlined for computational duties. Tensors, that are multidimensional arrays, prolong from easy scalars (0D) to greater dimensions by stacking lower-dimensional constructions. The mode-n product hyperlinks a tensor and a matrix alongside a particular dimension. SVD decomposes matrices into rank-1 parts, enabling noise discount by way of low-rank approximations by discarding insignificant values. Tucker decomposition extends SVD to tensors, breaking them into smaller core tensors and issue matrices, which aids in environment friendly knowledge illustration and dimensionality discount.
The research proposes a way to reshape MHA weight matrices in transformers into 3D tensors as an alternative of the traditional 2D format. Tucker decomposition composes these tensors into core tensors and shared issue matrices throughout all consideration heads inside a transformer layer. This method ensures that spotlight heads perform inside the identical subspace, enhancing reasoning capabilities and lowering noise. In comparison with current strategies comparable to LASER and TRAWL, this strategy leverages shared low-rank constructions to boost efficiency and effectivity whereas lowering the variety of parameters.
Intensive experiments validated the proposed framework on 4 benchmark reasoning datasets utilizing three LLMs: RoBERTa, GPT-J, and LLaMA2, encompassing each encoder-only and decoder-only architectures. The framework, utilized selectively to transformer layers, considerably enhanced reasoning talents whereas attaining parameter compression. Outcomes confirmed compatibility with FFN-only compression strategies like LASER, attaining improved accuracy and loss discount. A hybrid strategy combining LASER and the proposed methodology normally yielded the perfect efficiency. Ablation research confirmed the effectiveness of compressing all MHA weights collectively, outperforming separate compression of question, key, worth, and output weights, additional validating the framework’s design.
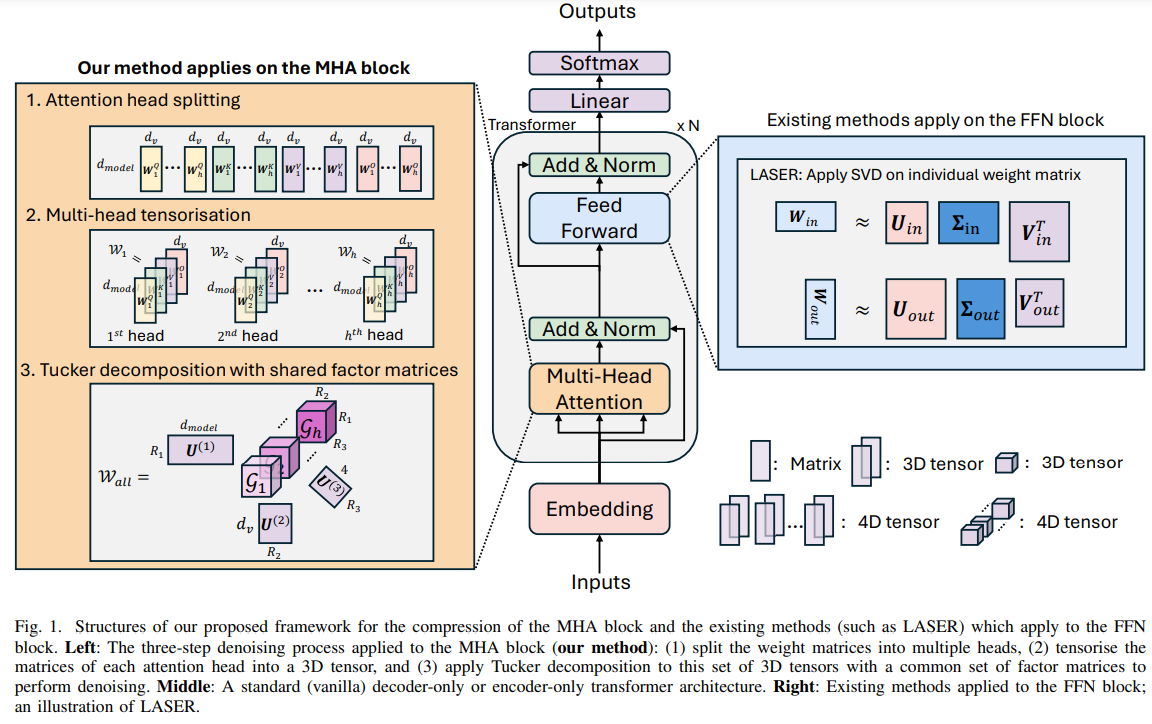
In conclusion, the research launched a framework to boost reasoning in LLMs whereas attaining vital parameter compression. By leveraging area information about MHA and using a novel multi-head tensorisation with Tucker decomposition, we denoise MHA weights and encode numerous info inside a shared higher-dimensional subspace. This strategy improves reasoning in encoder-only and decoder-only LLMs with as much as 250x compression, requiring no extra coaching or fine-tuning. The strategy can even complement FFN-based denoising methods for additional features. Whereas hyperparameter tuning varies throughout datasets, future work will concentrate on growing generalizable settings for broader applicability.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.