Language fashions have turn into more and more costly to coach and deploy. This has led researchers to discover methods akin to mannequin distillation, the place a smaller pupil mannequin is skilled to duplicate the efficiency of a bigger instructor mannequin. The concept is to allow environment friendly deployment with out compromising efficiency. Understanding the ideas behind distillation and the way computational sources will be optimally allotted between pupil and instructor fashions is essential to enhancing effectivity.
The rising measurement of machine studying fashions has resulted in excessive prices and sustainability challenges. Coaching these fashions requires substantial computational sources, and inference calls for much more computation. The related prices can surpass pretraining bills, with inference volumes reaching billions of day by day tokens. Furthermore, giant fashions current logistical challenges akin to elevated power consumption and problem in deployment. The need to scale back inference prices with out sacrificing mannequin capabilities has motivated researchers to hunt options that stability computational effectivity and effectiveness.
Earlier approaches to deal with computational constraints in giant mannequin coaching embrace compute-optimal coaching and overtraining. Compute-optimal coaching determines the best-performing mannequin measurement and dataset mixture inside a given compute finances. Overtraining extends coaching knowledge utilization past compute-optimal parameters, yielding compact, efficient fashions. Nonetheless, each methods have trade-offs, akin to elevated coaching length and diminishing efficiency enhancements. Whereas compression and pruning strategies have been examined, they typically result in a decline in mannequin effectiveness. Due to this fact, a extra structured method, akin to distillation, is required to boost effectivity.
Researchers from Apple and the College of Oxford introduce a distillation scaling regulation that predicts the efficiency of a distilled mannequin primarily based on compute finances distribution. This framework allows the strategic allocation of computational sources between instructor and pupil fashions, making certain optimum effectivity. The analysis supplies sensible tips for compute-optimal distillation and highlights situations the place distillation is preferable over supervised studying. The examine establishes a transparent relationship between coaching parameters, mannequin measurement, and efficiency by analyzing large-scale distillation experiments.
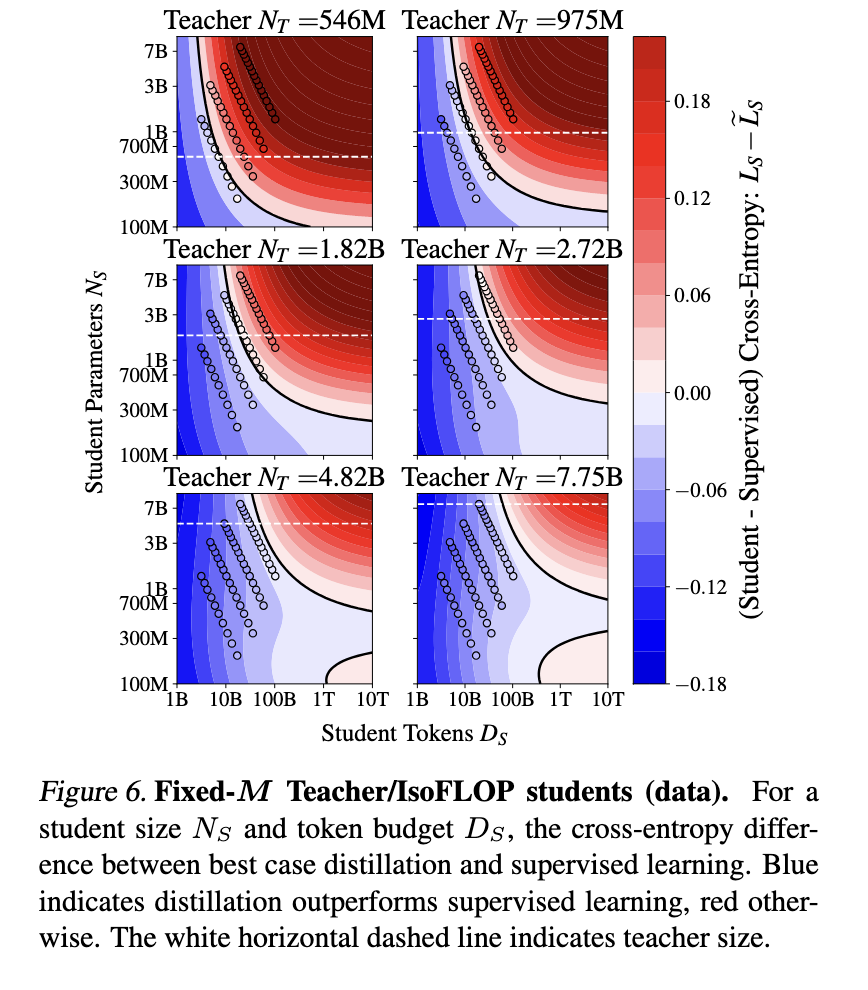
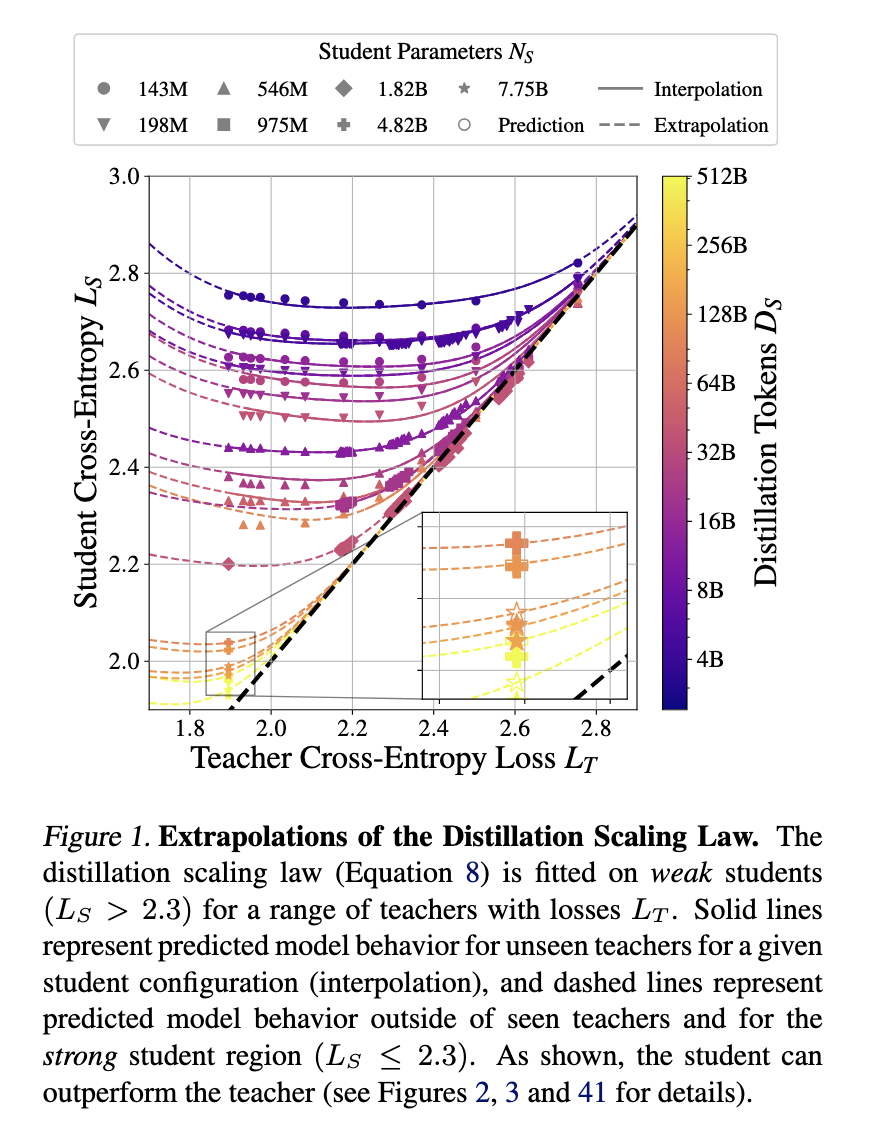
The proposed distillation scaling regulation defines how pupil efficiency will depend on the instructor’s cross-entropy loss, dataset measurement, and mannequin parameters. The analysis identifies a transition between two power-law behaviors, the place a pupil’s capacity to be taught will depend on the relative capabilities of the instructor. The examine additionally addresses the capability hole phenomenon, which means that stronger academics generally produce weaker college students. The evaluation reveals that this hole is because of variations in studying capability reasonably than mannequin measurement alone. Researchers exhibit that when compute is appropriately allotted, distillation can match or surpass conventional supervised studying strategies by way of effectivity.
Empirical outcomes validate the scaling regulation’s effectiveness in optimizing mannequin efficiency. The examine performed managed experiments on pupil fashions starting from 143 million to 12.6 billion parameters, skilled utilizing as much as 512 billion tokens. Findings point out that distillation is most useful when a instructor mannequin exists and the compute or coaching tokens allotted to the scholar don’t exceed a threshold depending on mannequin measurement. Supervised studying stays the simpler alternative if a instructor must be skilled. The outcomes present that pupil fashions skilled utilizing compute-optimal distillation can obtain decrease cross-entropy loss than these skilled utilizing supervised studying when compute is proscribed. Particularly, experiments exhibit that pupil cross-entropy loss decreases as a perform of instructor cross-entropy, following a predictable sample that optimizes effectivity.
The analysis on distillation scaling legal guidelines supplies an analytical basis for enhancing effectivity in mannequin coaching. Establishing a technique for compute allocation it presents helpful insights into decreasing inference prices whereas preserving mannequin efficiency. The findings contribute to the broader goal of creating AI fashions extra sensible for real-world functions. By refining coaching and deployment methods, this work allows the event of smaller but highly effective fashions that keep excessive efficiency at a lowered computational price.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 75k+ ML SubReddit.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.