Massive language fashions (LLMs) excel in producing contextually related textual content; nevertheless, making certain compliance with knowledge privateness rules, equivalent to GDPR, requires a sturdy capacity to unlearn particular data successfully. This functionality is important for addressing privateness considerations the place knowledge have to be solely faraway from fashions and any logical connections that might reconstruct deleted data.
The issue of unlearning in LLMs is especially difficult as a result of interconnected nature of information saved inside these fashions. Eradicating a single reality is inadequate if associated or deduced info stay. As an example, eradicating a household relationship reality doesn’t forestall the mannequin from inferring it by means of logical guidelines or remaining connections. Addressing this subject necessitates unlearning approaches that take into account specific knowledge and its logical dependencies.
Present unlearning strategies give attention to eradicating particular knowledge factors, equivalent to gradient ascent, adverse choice optimization (NPO), and activity vector strategies. These approaches intention to erase knowledge whereas retaining general mannequin utility. Nevertheless, they should obtain deep unlearning, which entails eradicating the goal reality and any inferable connections. This limitation compromises the completeness of information erasure and should result in collateral harm, erasing unrelated info unnecessarily.
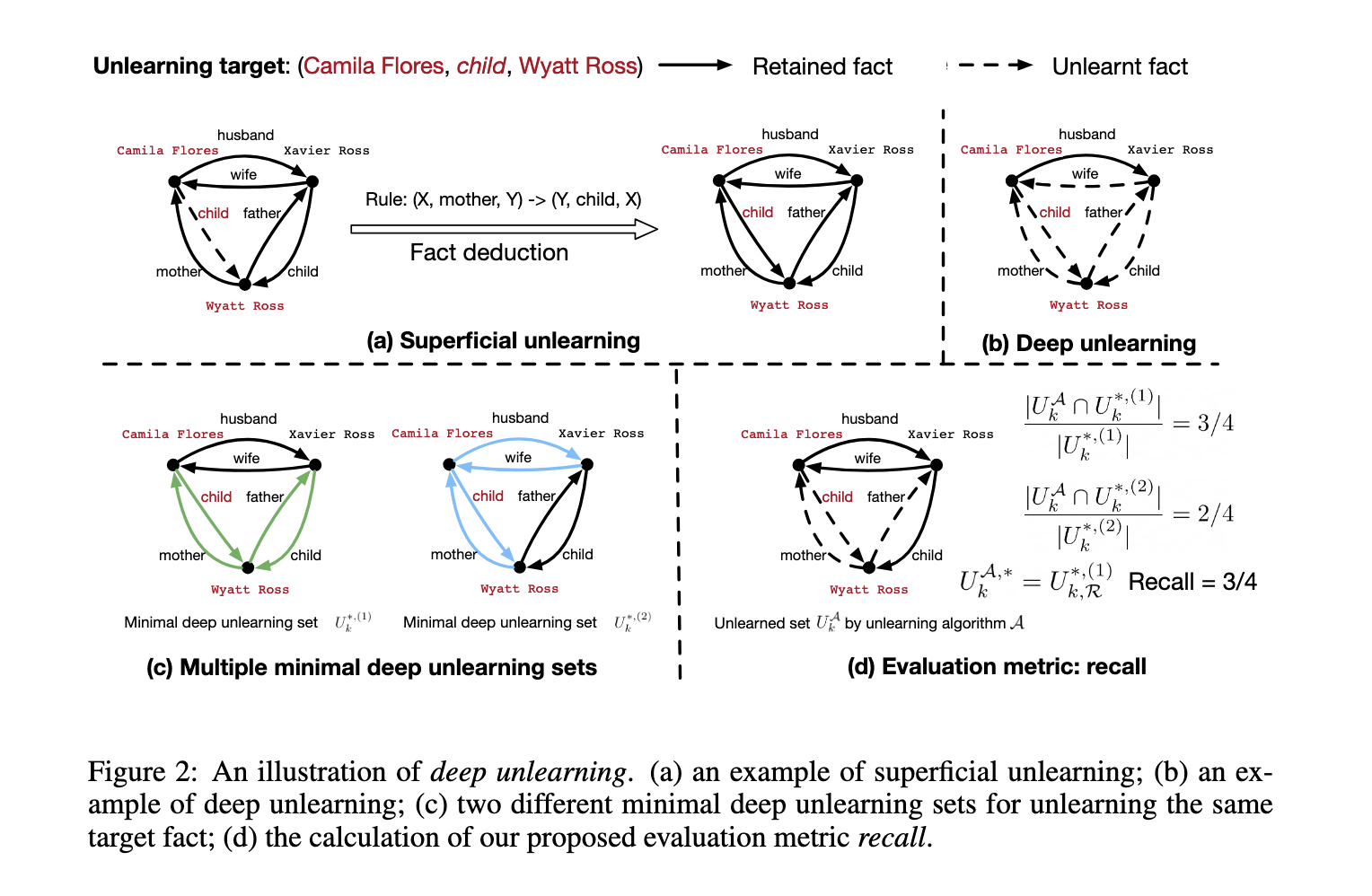
Researchers from the College of California, San Diego, & Carnegie Mellon College launched the idea of “deep unlearning” to handle these challenges. The analysis leverages an artificial dataset, EDU-RELAT, consisting of 400 household relationships, 300 biographical info, and 48 logical guidelines. These function a benchmark for evaluating unlearning strategies. Key metrics equivalent to recall, which measures the extent of unlearning, and accuracy, which assesses the preservation of unrelated info, had been used to judge efficiency.
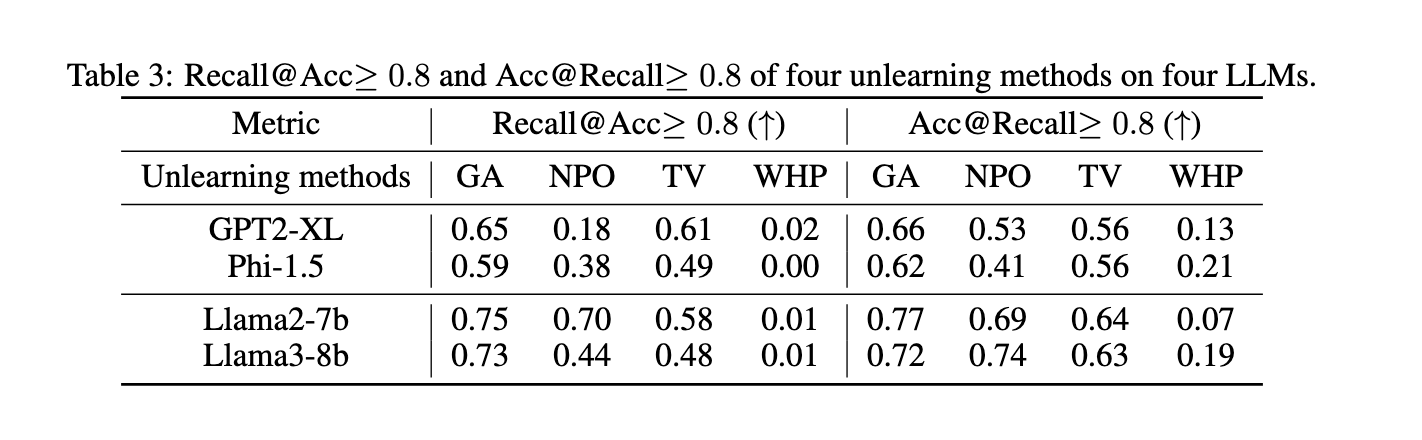
Within the research, the researchers examined 4 unlearning methods—Gradient Ascent (GA), Destructive Choice Optimization (NPO), Job Vector (TV), and Who’s Harry Potter (WHP)—on 4 distinguished LLMs: GPT2-XL, Phi-1.5, Llama2-7b, and Llama3-8b. The analysis targeted on deeply unlearning 55 particular info associated to household relationships. The research measured each Acc@Recall ≥ 0.8 (accuracy when a recall is above 80%) and Recall@Acc ≥ 0.8 (recall when accuracy is above 80%) to steadiness comprehensiveness and utility.
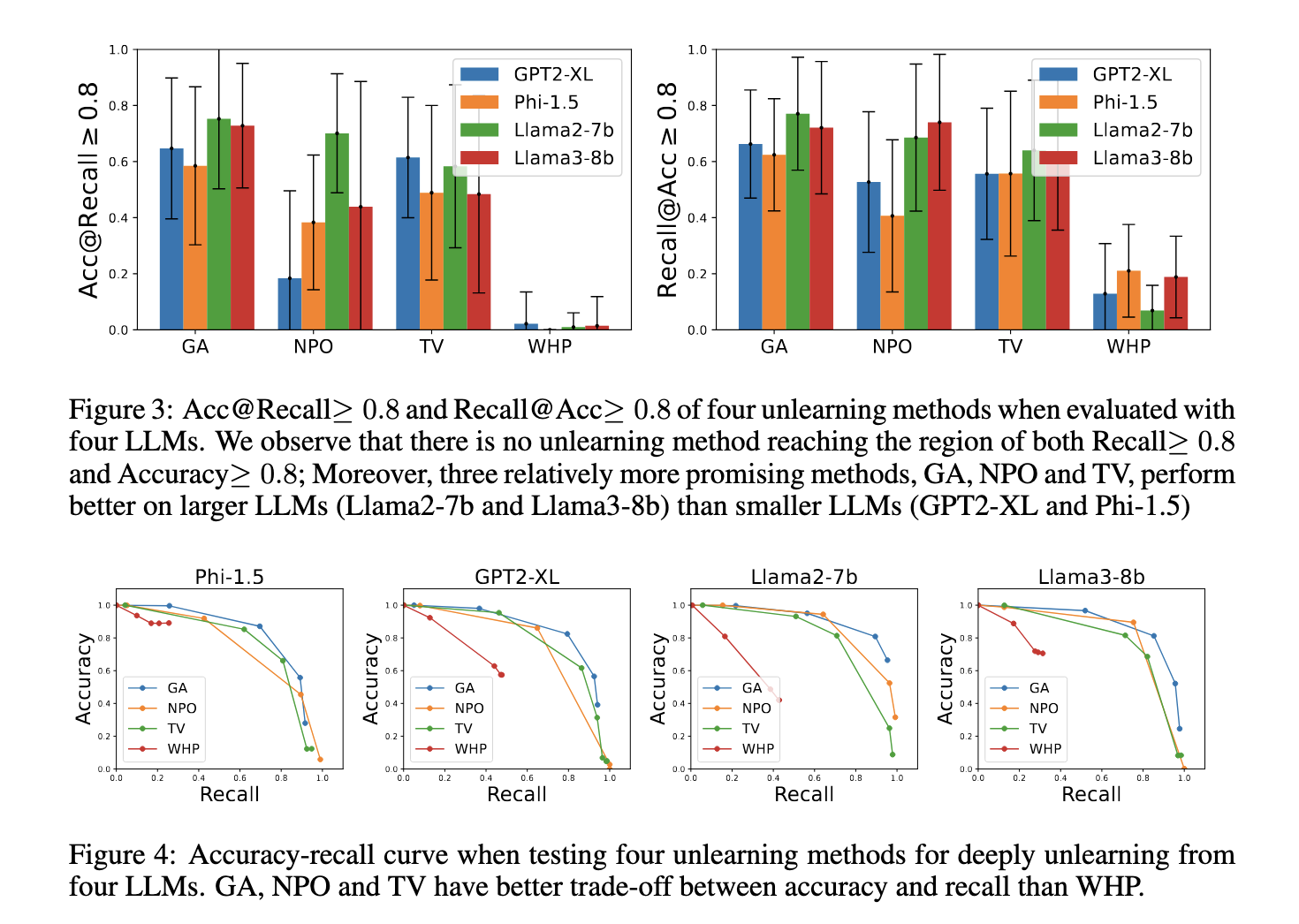
The outcomes highlighted vital areas for enchancment in current unlearning strategies—not one of the strategies achieved excessive recall and accuracy. For instance, Gradient Ascent achieved a recall of 75% on Llama2-7b however typically induced collateral harm by unlearning unrelated info. NPO and Job Vector achieved recall charges between 70%-73% on bigger fashions, equivalent to Llama3-8b. In distinction, WHP carried out poorly, with recall charges under 50% throughout all fashions. Bigger fashions like Llama2-7b and Llama3-8b outperformed smaller ones like GPT2-XL and Phi-1.5 because of their extra superior reasoning capabilities, which aided in higher dealing with logical dependencies.
Extra evaluation revealed that the accuracy of biographical info was typically increased than that of household relationships. As an example, GA achieved an Acc@Recall ≥ 0.8 for biographical info on Llama2-7b and Llama3-8b however solely 0.6 for household relationships. This discrepancy highlights the issue in unlearning carefully associated info with out unintended losses. Unlearning a single reality typically required eradicating ten or extra associated info, demonstrating the complexity of deep unlearning.
The analysis underscores the constraints of present approaches in reaching efficient deep unlearning. Whereas strategies like Gradient Ascent confirmed potential for superficial unlearning, they wanted to be extra for deeply interconnected datasets. The research concludes with a name for comprehensively creating new methodologies that handle these challenges. By establishing deep unlearning as a benchmark, this analysis lays the groundwork for developments in privacy-preserving AI and highlights the significance of balancing unlearning efficacy with mannequin utility.
Try the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our newsletter.. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.