Synthetic intelligence has grown considerably with the mixing of imaginative and prescient and language, permitting techniques to interpret and generate data throughout a number of knowledge modalities. This functionality enhances purposes similar to pure language processing, laptop imaginative and prescient, and human-computer interplay by seamlessly permitting AI fashions to course of textual, visible, and video inputs. Nevertheless, challenges stay in guaranteeing that such techniques present correct, significant, and human-aligned outputs, notably as multi-modal fashions turn out to be extra advanced.
The first problem in establishing giant vision-language fashions is attaining the outputs produced by them aligning with the human preferences. Most current techniques fail as a result of manufacturing of hallucinated responses and inconsistency within the interplay course of inside a number of modes, in addition to due to their dependency on the appliance area. Moreover, such high-quality datasets are scant and vary throughout numerous sorts and duties like mathematical reasoning, video evaluation, or following directions. LVLMs can not ship the subtlety wanted in real-world purposes with out correct alignment mechanisms.
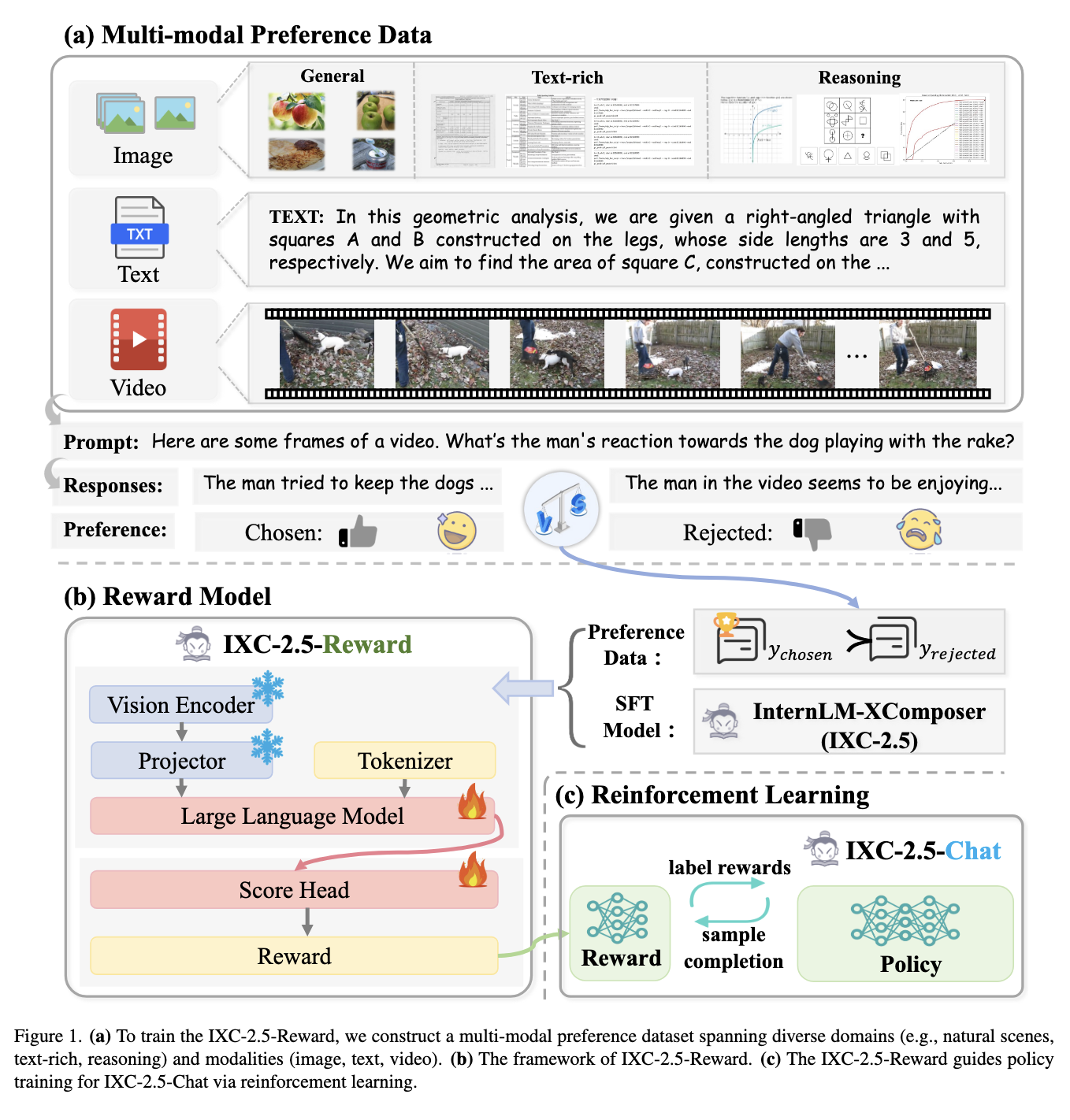
Present options to those challenges are principally restricted to text-only rewards or narrowly scoped generative fashions. Such fashions sometimes depend on hand annotations or proprietary techniques, which aren’t scalable and never clear. Moreover, the present strategies have a limitation regarding static datasets and pre-defined prompts that can’t seize all of the variability in real-world inputs. This ends in a big hole between the power to develop complete reward fashions that might information LVLMs successfully.
Researchers from the Shanghai Synthetic Intelligence Laboratory, The Chinese language College of Hong Kong, Shanghai Jiao Tong College, Nanjing College, Fudan College, and Nanyang Technological College launched InternLM-XComposer2.5-Reward (IXC-2.5-Reward). The mannequin is a big step in growing multi-modal reward fashions, offering a strong framework to align LVLM outputs with human preferences. Not like different options, the IXC-2.5-Reward can course of totally different varieties, together with textual content, photographs, and movies, and has the potential to carry out nicely in diversified purposes. Therefore, this method is a big enchancment over current instruments, making an allowance for an absence of area protection and scalabilities.
In accordance with the researcher, IXC-2.5-Reward was designed via a complete choice dataset and contains various domains similar to texts, common reasonings, and video understanding. The mannequin has a scoring head that predicts reward scores for given prompts and responses. The crew used reinforcement studying algorithms like Proximal Coverage Optimization (PPO) to coach a chat mannequin, IXC-2.5-Chat, to supply high-quality, human-aligned responses. The coaching was accompanied by open-source and newly collected knowledge, guaranteeing broad applicability. Additional, the mannequin doesn’t endure from the frequent pitfalls of size biases because it makes use of constraints on response lengths to make sure high quality and conciseness in generated outputs.
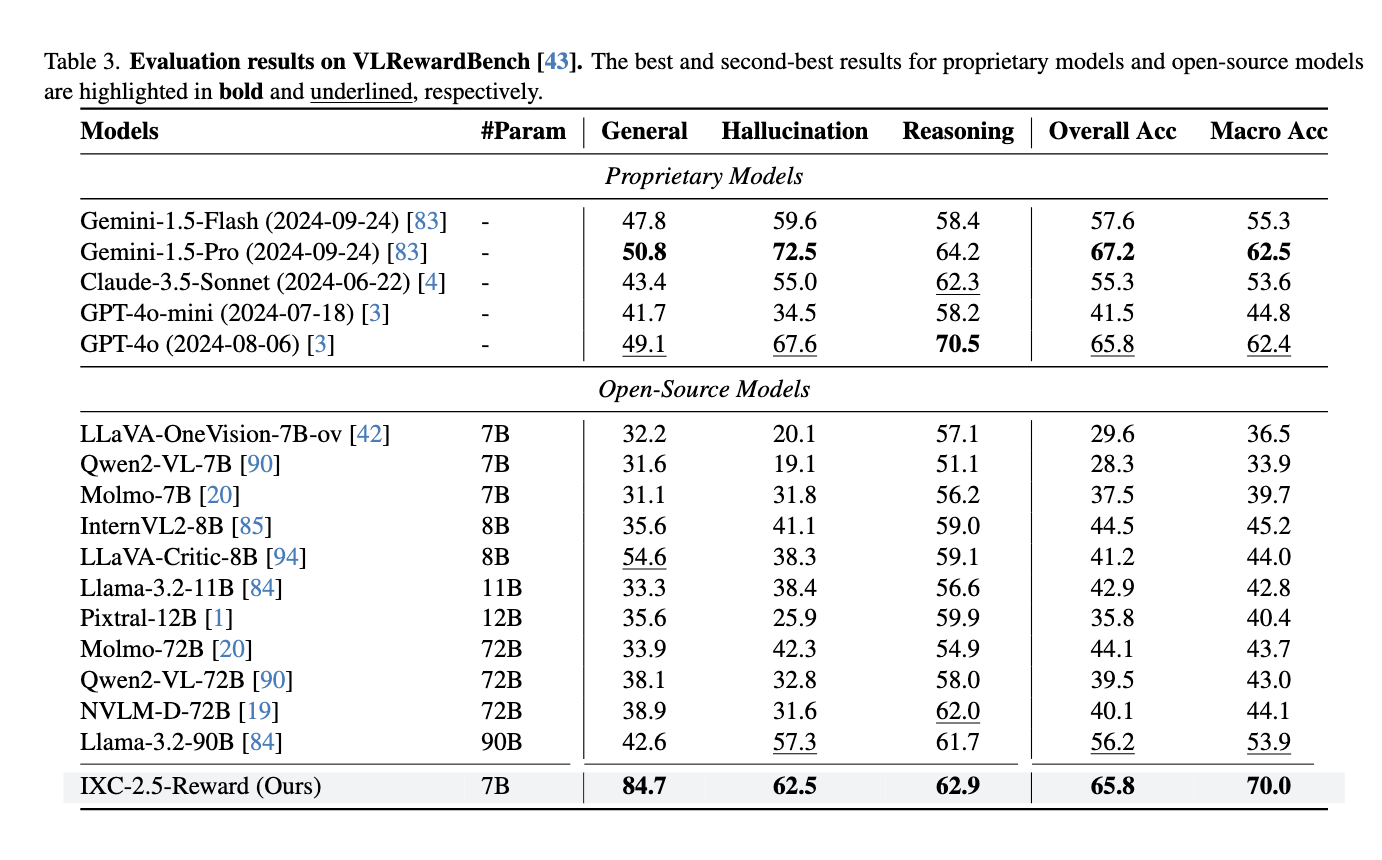
The efficiency of IXC-2.5-Reward units a brand new benchmark in multi-modal AI. On VL-RewardBench, the mannequin achieved an general accuracy of 70.0%, outperforming outstanding generative fashions like Gemini-1.5-Professional (62.5%) and GPT-4o (62.4%). The system additionally produced aggressive outcomes on text-only benchmarks, scoring 88.6% on Reward-Bench and 68.8% on RM-Bench. These outcomes confirmed that the mannequin might preserve sturdy language processing capabilities even whereas performing extraordinarily nicely in multi-modal duties, and as well as, incorporating IXC-2.5-Reward into the chat mannequin IXC-2.5-Chat produced giant beneficial properties in instruction-following and multi-modal dialogue settings, validating the applicability of the reward mannequin in real-world situations.
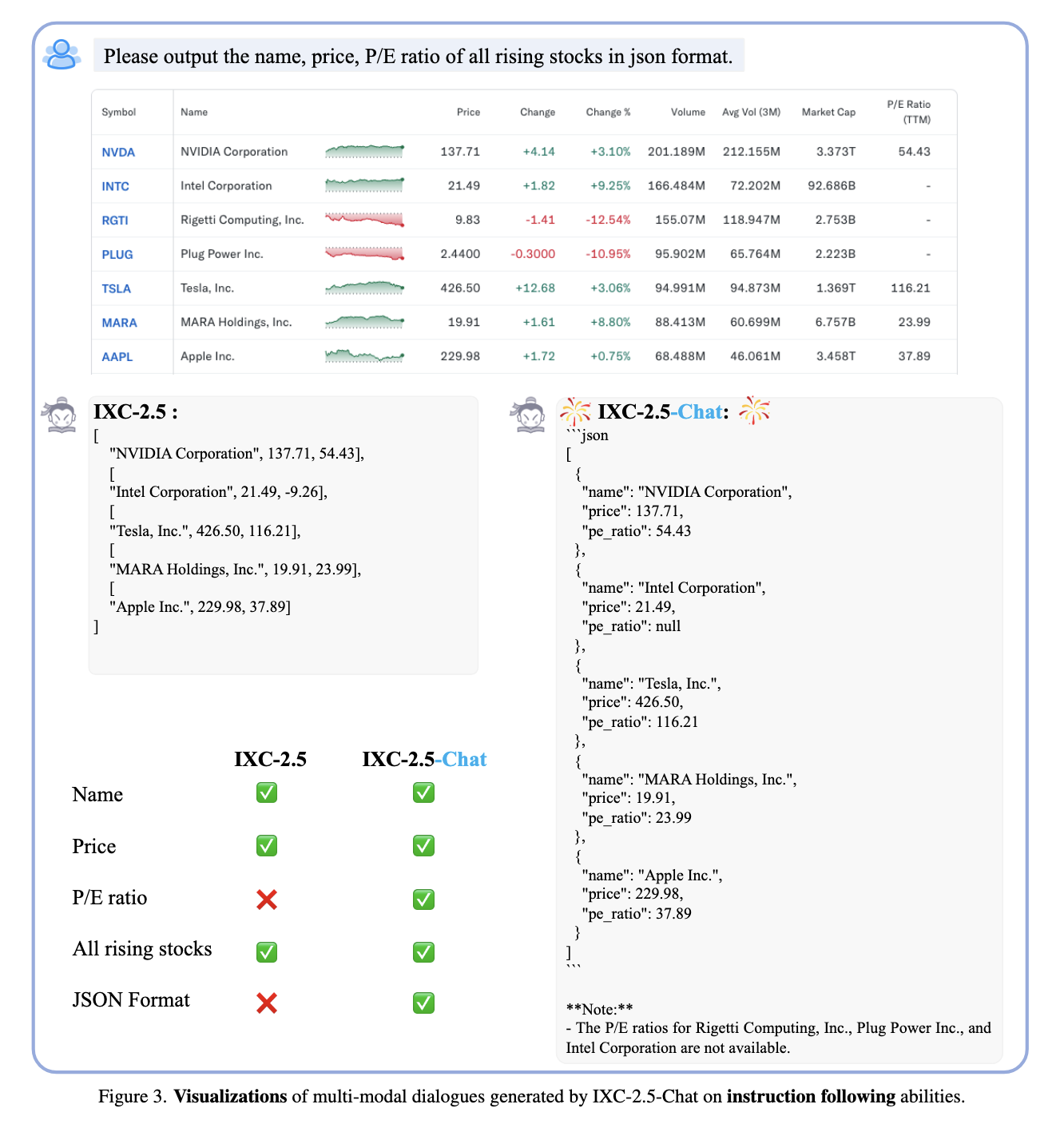
The researchers additionally showcased three purposes of IXC-2.5-Reward that underline its versatility. First, it serves as a supervisory sign for reinforcement studying, enabling on-policy optimization methods like PPO to coach fashions successfully. Second, the mannequin’s test-time scaling capabilities permit optimum responses from a number of candidates to be chosen, additional enhancing efficiency. Lastly, IXC-2.5-Reward was important in cleansing the info and discovering noisy or problematic samples within the datasets, which have been filtered out from coaching knowledge and, subsequently, enhanced the standard of coaching knowledge for LVLMs.
This work is an enormous leap ahead in multi-modal reward fashions and bridges important gaps concerning scalability, versatility, and alignment with human preferences. The authors have established the idea for additional breakthroughs on this area via various datasets and the appliance of state-of-the-art reinforcement studying methods. IXC-2.5-Reward is about to revolutionize multi-modal AI techniques and produce extra robustness and effectiveness to real-world purposes.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.