Massive language fashions (LLMs) fashions primarily depend upon their inside data, which could be insufficient when dealing with real-time or knowledge-intensive questions. This limitation typically results in inaccurate responses or hallucinations, making it important to boost LLMs with exterior search capabilities. By leveraging reinforcement studying, researchers are actively engaged on strategies to enhance these fashions’ means to retrieve and combine related data past their static data base.
Present LLMs’ restricted entry to up-to-date and domain-specific data is a serious concern. Since these fashions are skilled on huge datasets that won’t embody latest developments, they battle with answering dynamic questions requiring real-time data. Whereas retrieval-augmented technology (RAG) strategies have been launched to mitigate this concern, current options rely closely on structured prompting and supervised fine-tuning (SFT). These approaches typically result in overfitting, limiting the mannequin’s generalization means throughout totally different datasets. There’s a want for an alternate that permits LLMs to autonomously work together with exterior search methods, enhancing their adaptability and accuracy.
Earlier strategies have tried to include exterior search performance into LLMs utilizing iterative prompting, supervised fine-tuning, and tree-based search methods like Monte Carlo Tree Search (MCTS). Whereas these strategies present some enhancements, they depend on costly computational sources and proprietary fashions. Supervised fine-tuning, as an illustration, forces fashions to memorize reasoning paths, which negatively impacts their means to generalize to new situations. Some retrieval-based methods introduce multi-step question refinement methods however typically require human intervention or predefined immediate templates. These limitations necessitate the event of a extra autonomous and environment friendly search mechanism for LLMs.
A analysis group from the Renmin College of China and DataCanvas Alaya NeW launched R1-Searcher, a novel reinforcement studying framework designed to enhance LLMs’ means to retrieve exterior data successfully. This framework employs a two-stage reinforcement studying method to allow LLMs to invoke an exterior search system with out requiring human-crafted prompts or prior supervised fine-tuning. By focusing solely on reinforcement studying, R1-Searcher permits fashions to discover and study optimum retrieval methods autonomously, enhancing accuracy and effectivity in reasoning duties.
The R1-Searcher framework is structured in two phases. The primary part encourages the mannequin to provoke exterior search actions, offering retrieval-based rewards with out contemplating the ultimate reply’s correctness. This part ensures that the mannequin learns to invoke search queries accurately. The second part refines this functionality by introducing an answer-based reward system, which evaluates whether or not the retrieved data contributes to fixing the given downside. The reinforcement studying course of depends on a tailor-made loss operate that penalizes incorrect or pointless searches whereas rewarding the efficient use of exterior data. Not like earlier retrieval-based methods, this method permits LLMs to combine reasoning and retrieval dynamically, enhancing their adaptability throughout various duties.
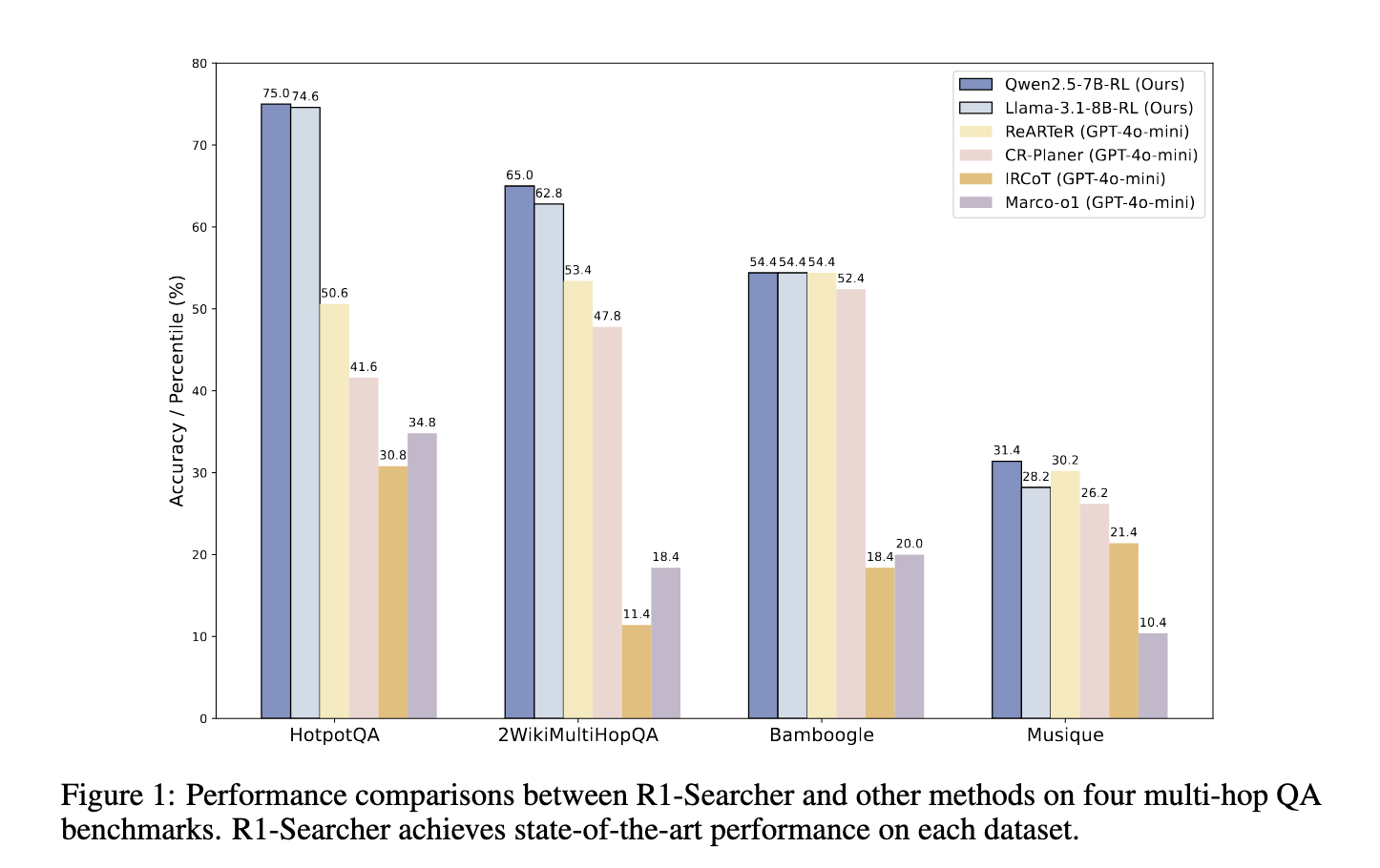
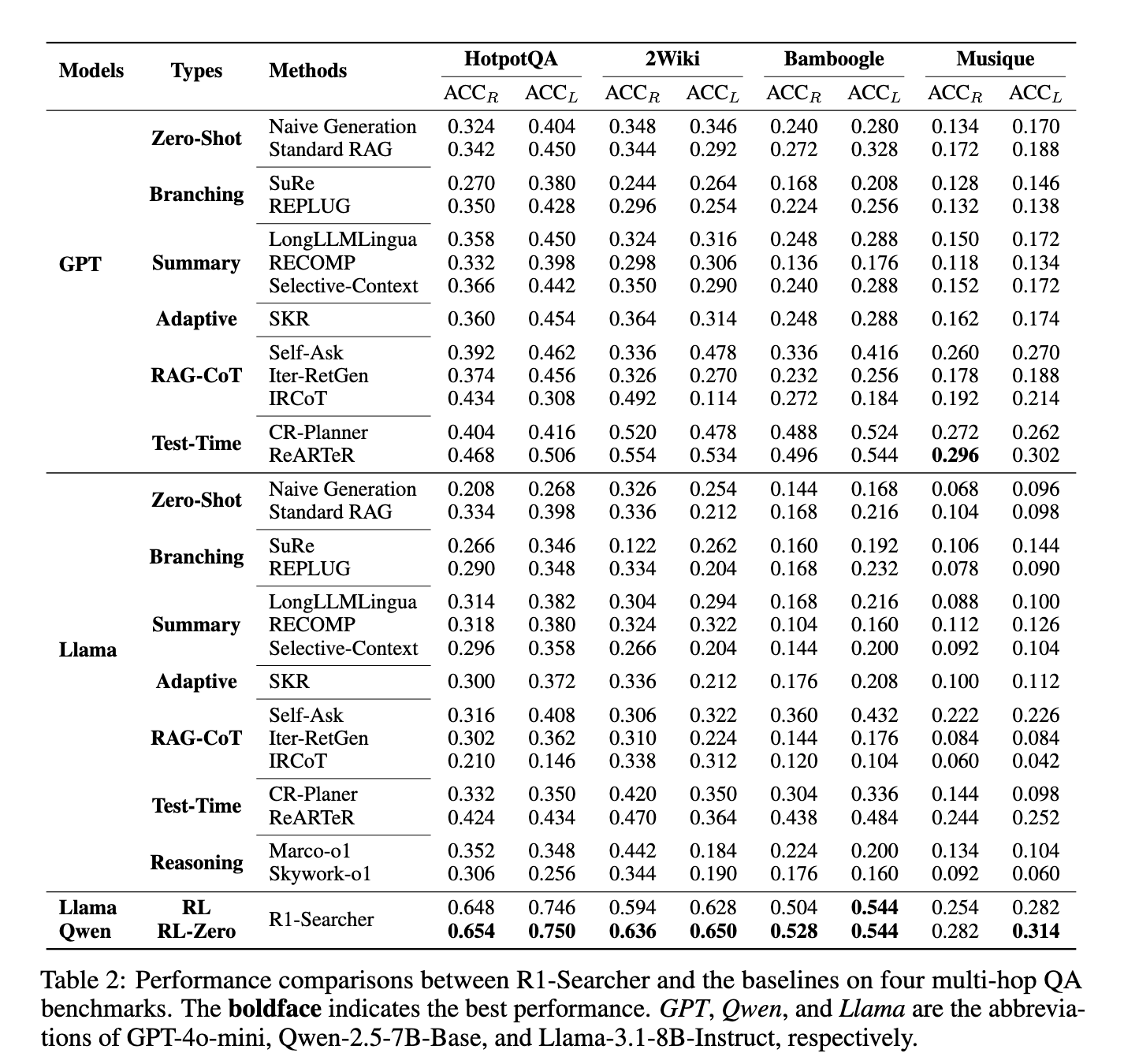
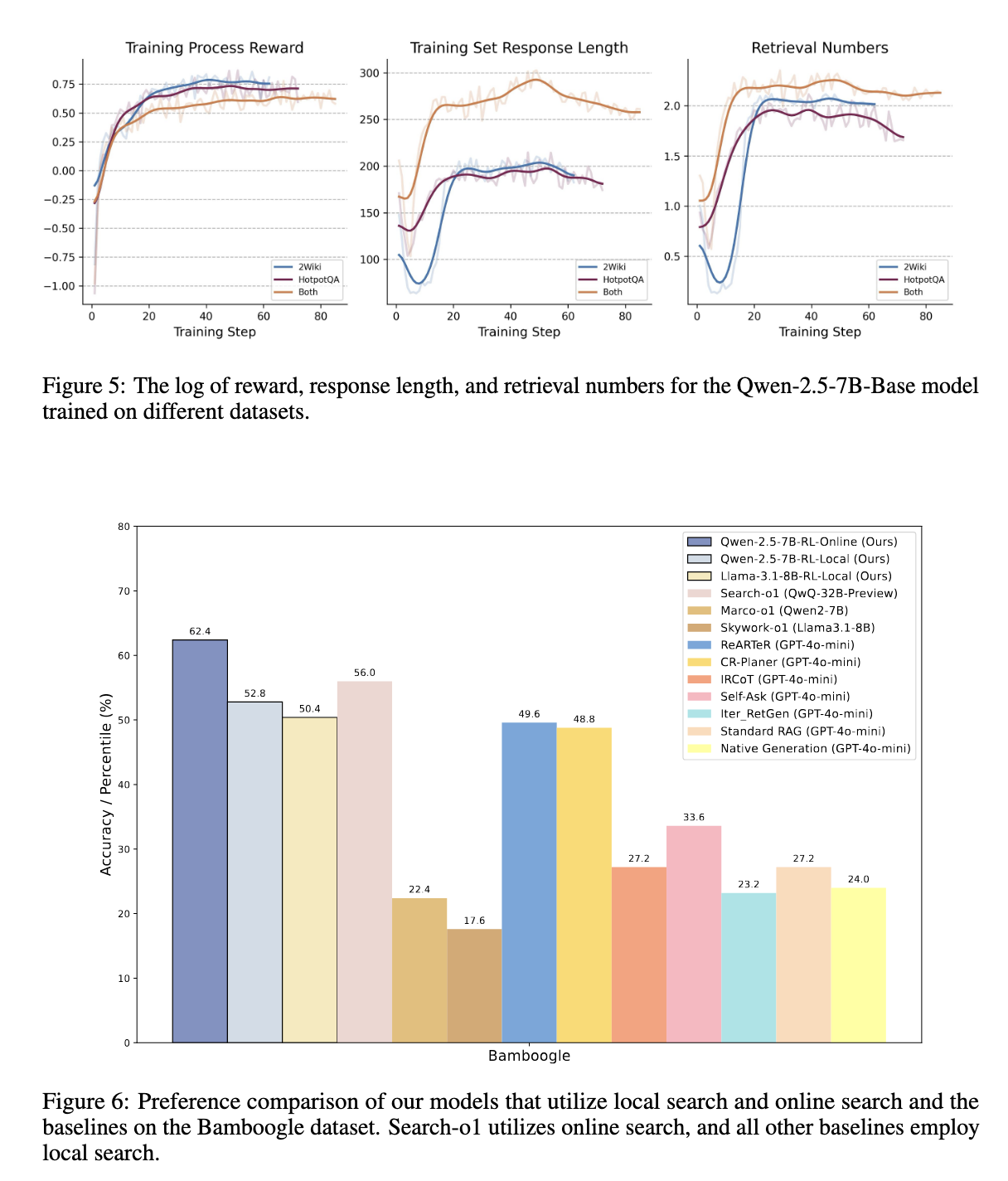
Experimental evaluations demonstrated that R1-Searcher outperformed current retrieval-augmented strategies, together with GPT-4o-mini-based fashions. On the HotpotQA dataset, accuracy improved by 48.22%, whereas on the 2WikiMultiHopQA dataset, it achieved a 21.72% improve. Additional, it confirmed robust generalization capabilities by outperforming different fashions on the Bamboogle dataset, reaching an 11.4% enchancment over comparable retrieval-based approaches. Not like earlier methods, which relied on closed-source fashions and in depth computational sources, R1-Searcher supplied superior efficiency whereas sustaining effectivity in search and reasoning duties. The research additionally demonstrated that this method efficiently mitigated frequent points associated to hallucinations and misinformation in LLM-generated responses.
The findings point out that enhancing LLMs with autonomous search capabilities can considerably enhance their accuracy and generalization. Utilizing reinforcement studying as a substitute of supervised fine-tuning, R1-Searcher permits fashions to study optimum retrieval methods dynamically, eliminating reliance on memorized responses. This method represents a serious development in synthetic intelligence, addressing the restrictions of current fashions whereas making certain they continue to be adaptable to evolving data necessities. The research’s outcomes spotlight the potential for reinforcement studying to revolutionize data integration in LLMs, making them extra dependable for various reasoning duties.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this mission. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 80k+ ML SubReddit.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.