Massive reasoning fashions (LRMs) make use of a deliberate, step-by-step thought course of earlier than arriving at an answer, making them appropriate for advanced duties requiring logical accuracy. Not like earlier strategies that relied on transient chain-of-thought reasoning, LRMs combine intermediate verification steps, guaranteeing every stage contributes meaningfully towards the ultimate reply. This structured reasoning strategy is more and more important as AI methods clear up intricate issues throughout numerous domains.
A elementary problem in creating such fashions lies in coaching massive language fashions (LLMs) to execute logical reasoning with out incurring important computational overhead. Reinforcement studying (RL) has emerged as a viable resolution, permitting fashions to refine their reasoning skills by way of iterative coaching. Nonetheless, conventional RL approaches rely upon human-annotated knowledge to outline reward alerts, limiting their scalability. The reliance on guide annotation creates bottlenecks, proscribing RL’s applicability throughout massive datasets. Researchers have explored different reward methods that circumvent this dependence, leveraging self-supervised strategies to judge mannequin responses towards predefined drawback units.
Present studying frameworks for coaching LLMs primarily give attention to reinforcement studying from human suggestions (RLHF), whereby fashions study by way of human-generated reward alerts. Regardless of its effectiveness, RLHF presents challenges associated to annotation prices and dataset limitations. Researchers have integrated verifiable datasets, reminiscent of mathematical issues and coding challenges, to handle these considerations. These drawback units enable fashions to obtain direct suggestions based mostly on the correctness of their options, eliminating the necessity for human intervention. This automated analysis mechanism has enabled extra environment friendly RL coaching, increasing its feasibility for large-scale AI growth.
A analysis group from the Renmin College of China, in collaboration with the Beijing Academy of Synthetic Intelligence (BAAI) and DataCanvas Alaya NeW, launched an RL-based coaching framework to enhance the structured reasoning skills of LLMs. Their research systematically examined the results of RL on reasoning efficiency, specializing in strategies that improve mannequin comprehension and accuracy. The researchers optimized mannequin reasoning with out counting on in depth human supervision by implementing structured reward mechanisms based mostly on problem-solving verification. Their strategy refined mannequin outputs, guaranteeing logical coherence in generated responses.
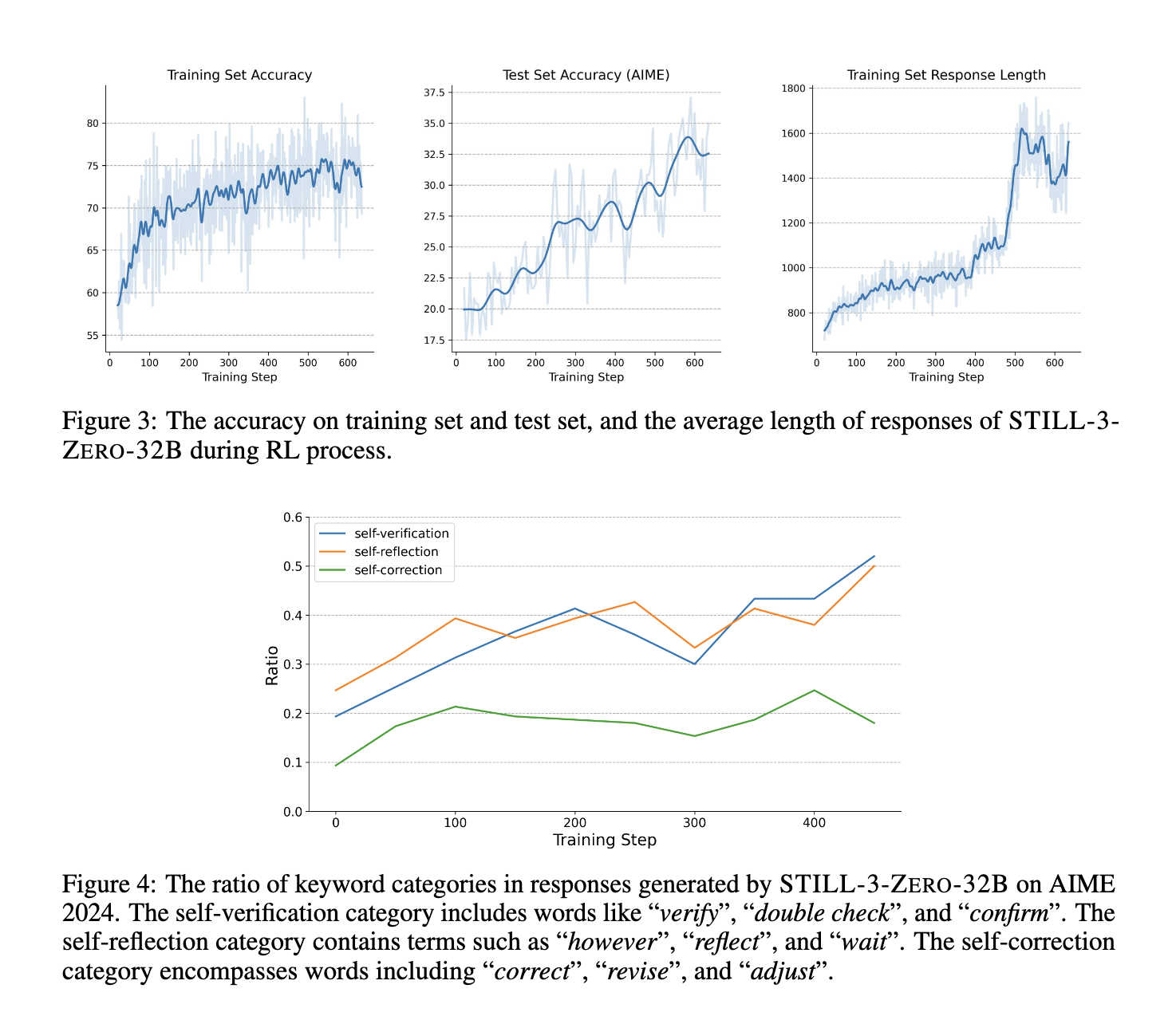
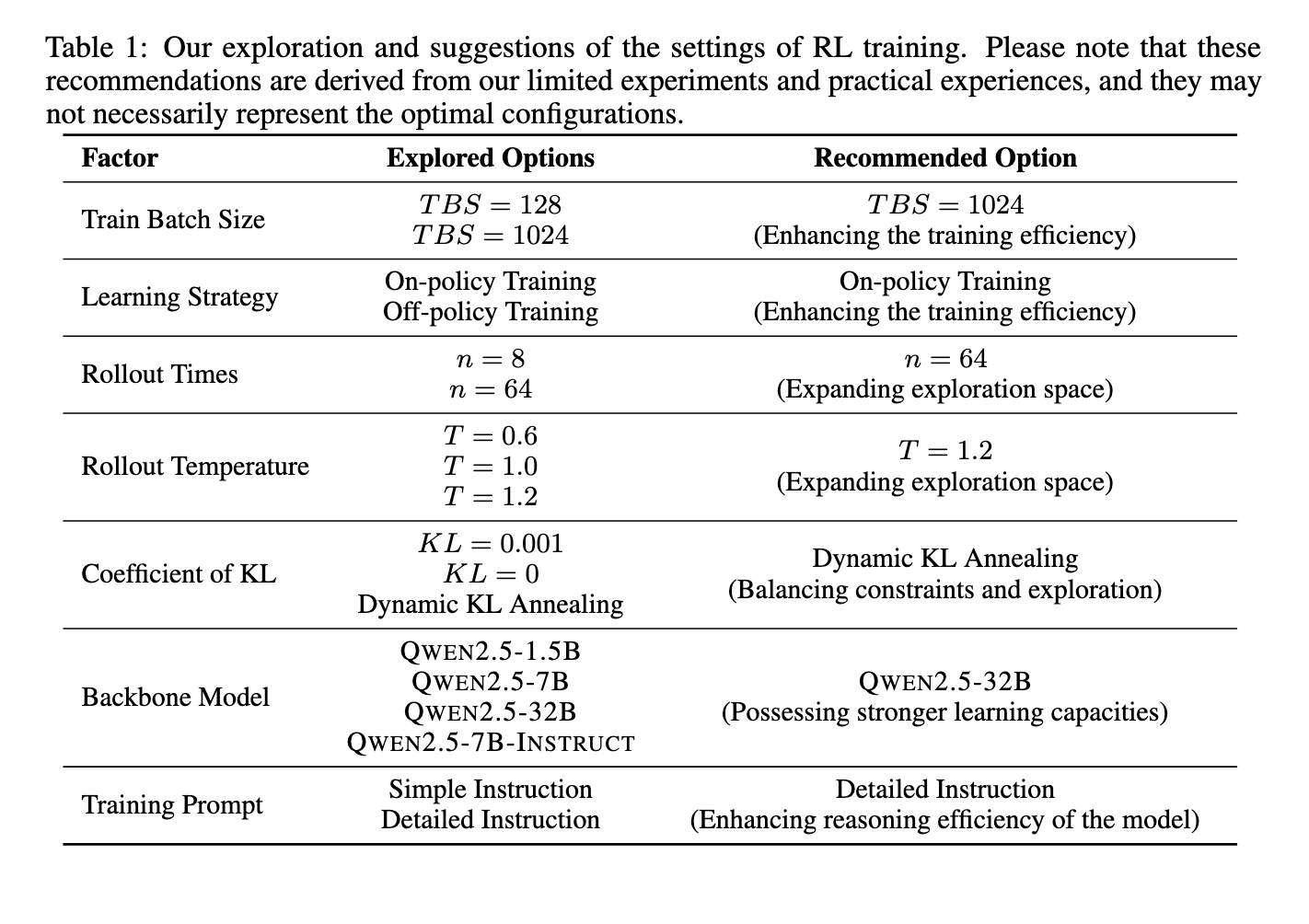
The methodology concerned reinforcement studying strategies utilized to each base and fine-tuned fashions. The researchers educated fashions utilizing coverage optimization strategies and structured reward features. Refining response era by way of RL enabled fashions to develop advanced reasoning skills, together with verification and self-reflection. The researchers built-in software manipulation strategies to boost efficiency additional, permitting fashions to work together dynamically with exterior methods for problem-solving. Their experiments demonstrated that RL successfully guided fashions towards extra structured responses, bettering general accuracy and decision-making effectivity. The coaching course of leveraged the QWEN 2.5-32B mannequin, fine-tuned utilizing a mix of reward alerts to optimize reasoning depth and response high quality. The researchers additionally explored numerous RL hyperparameter configurations, testing the affect of batch sizes, rollout occasions, and coverage studying methods on mannequin efficiency. Adjusting these parameters ensured optimum coaching effectivity whereas stopping reward exploitation, a typical problem in RL-based mannequin growth.
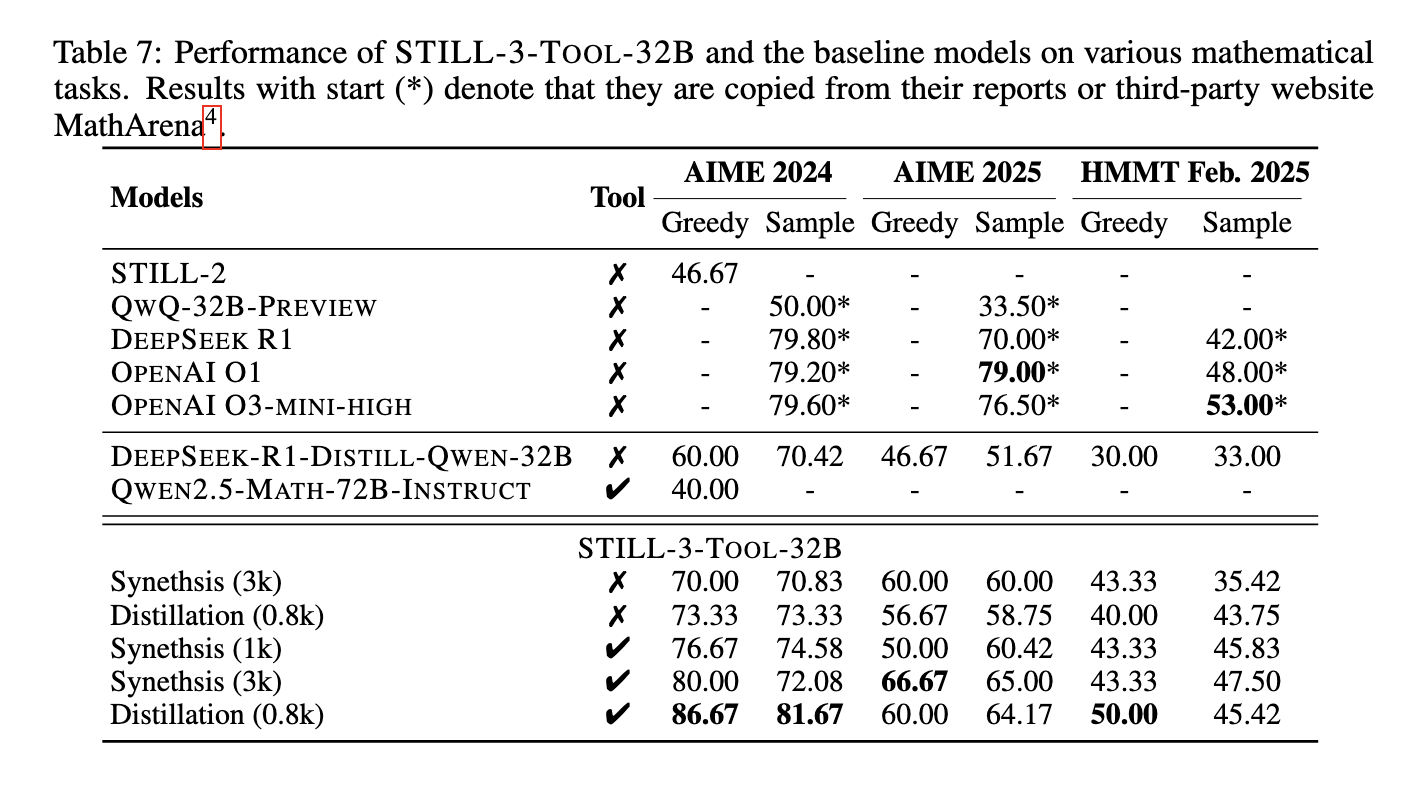
Efficiency evaluations highlighted important enhancements achieved by way of RL-based coaching. After present process reinforcement studying, the QWEN 2.5-32B mannequin demonstrated enhanced reasoning skills with elevated response lengths and better check accuracy. Particularly, the mannequin achieved an accuracy charge of 39.33% on the AIME 2024 dataset, considerably bettering its baseline efficiency. In additional experiments, software manipulation strategies had been integrated, resulting in an excellent larger accuracy of 86.67% when using a grasping search technique. These outcomes underscore RL’s effectiveness in refining LLM reasoning capabilities, highlighting its potential for utility in advanced problem-solving duties. The mannequin’s capability to course of in depth reasoning steps earlier than arriving at a remaining reply proved instrumental in attaining these efficiency features. Furthermore, researchers noticed that growing response size alone didn’t essentially translate to raised reasoning efficiency. As a substitute, structuring intermediate reasoning steps inside RL coaching led to significant enhancements in logical accuracy.

This analysis demonstrates the numerous function of reinforcement studying in advancing structured reasoning fashions. Researchers efficiently enhanced LLMs’ capability to have interaction in deep, logical reasoning by integrating RL coaching strategies. The research addresses key challenges in computational effectivity and coaching scalability, laying the groundwork for additional developments in AI-driven problem-solving. Refining RL methodologies and exploring further reward mechanisms can be crucial for additional optimizing the reasoning capabilities of LLMs.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.