Giant language fashions (LLMs) use in depth computational assets to course of and generate human-like textual content. One rising method to boost reasoning capabilities in LLMs is test-time scaling, which dynamically allocates computational assets throughout inference. This method goals to enhance the accuracy of responses by refining the mannequin’s reasoning course of. As fashions like OpenAI’s o1 sequence launched test-time scaling, researchers sought to know whether or not longer reasoning chains led to improved efficiency or if different methods might yield higher outcomes.
Scaling reasoning in AI fashions poses a big problem, particularly in instances the place prolonged chains of thought don’t essentially translate to higher outcomes. The belief that growing the size of responses enhances accuracy is being questioned by researchers, who’ve discovered that longer explanations can introduce inconsistencies. Errors accumulate over prolonged reasoning chains, and fashions usually make pointless self-revisions, resulting in efficiency degradation fairly than enchancment. If test-time scaling is to be an efficient resolution, it should steadiness reasoning depth with accuracy, guaranteeing that computational assets are used effectively with out diminishing the mannequin’s effectiveness.
Present approaches to test-time scaling primarily fall into sequential and parallel classes. Sequential scaling extends the chain-of-thought (CoT) throughout inference, anticipating that extra prolonged reasoning will result in improved accuracy. Nevertheless, research on fashions like QwQ, Deepseek-R1 (R1), and LIMO point out that extending CoTs doesn’t persistently yield higher outcomes. These fashions often use self-revision, introducing redundant computations that degrade efficiency. In distinction, parallel scaling generates a number of options concurrently and selects the most effective one based mostly on a predetermined criterion. Comparative analyses recommend that parallel scaling is more practical in sustaining accuracy and effectivity.
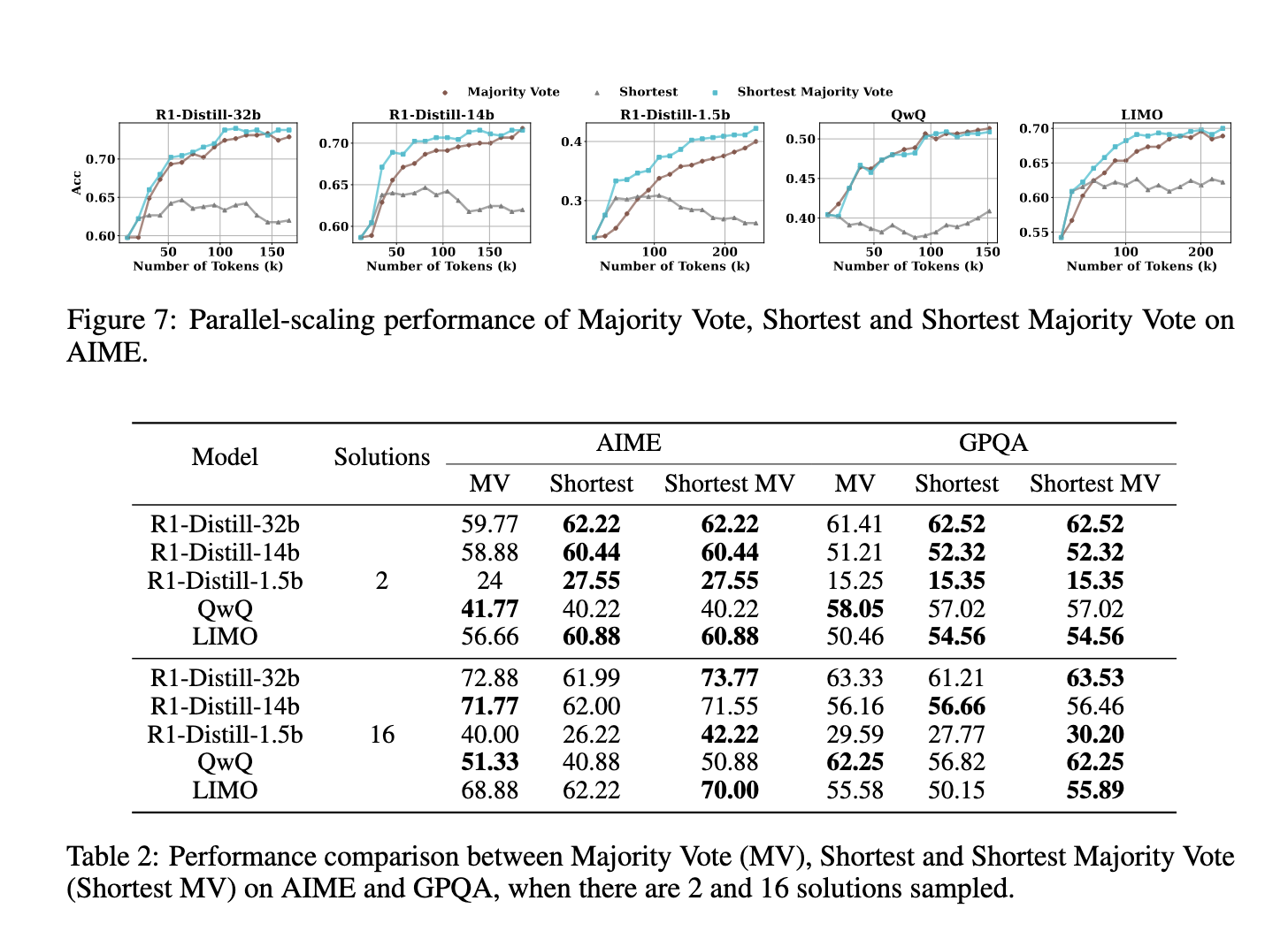
Researchers from Fudan College and the Shanghai AI Laboratory launched an revolutionary methodology referred to as “Shortest Majority Vote” to handle the restrictions of sequential scaling. This methodology optimizes test-time scaling by leveraging parallel computation whereas factoring in resolution size. The first perception behind this method is that shorter options are typically extra correct than longer ones, as they include fewer pointless self-revisions. By incorporating resolution size into the bulk voting course of, this methodology enhances fashions’ efficiency by prioritizing frequent and concise solutions.
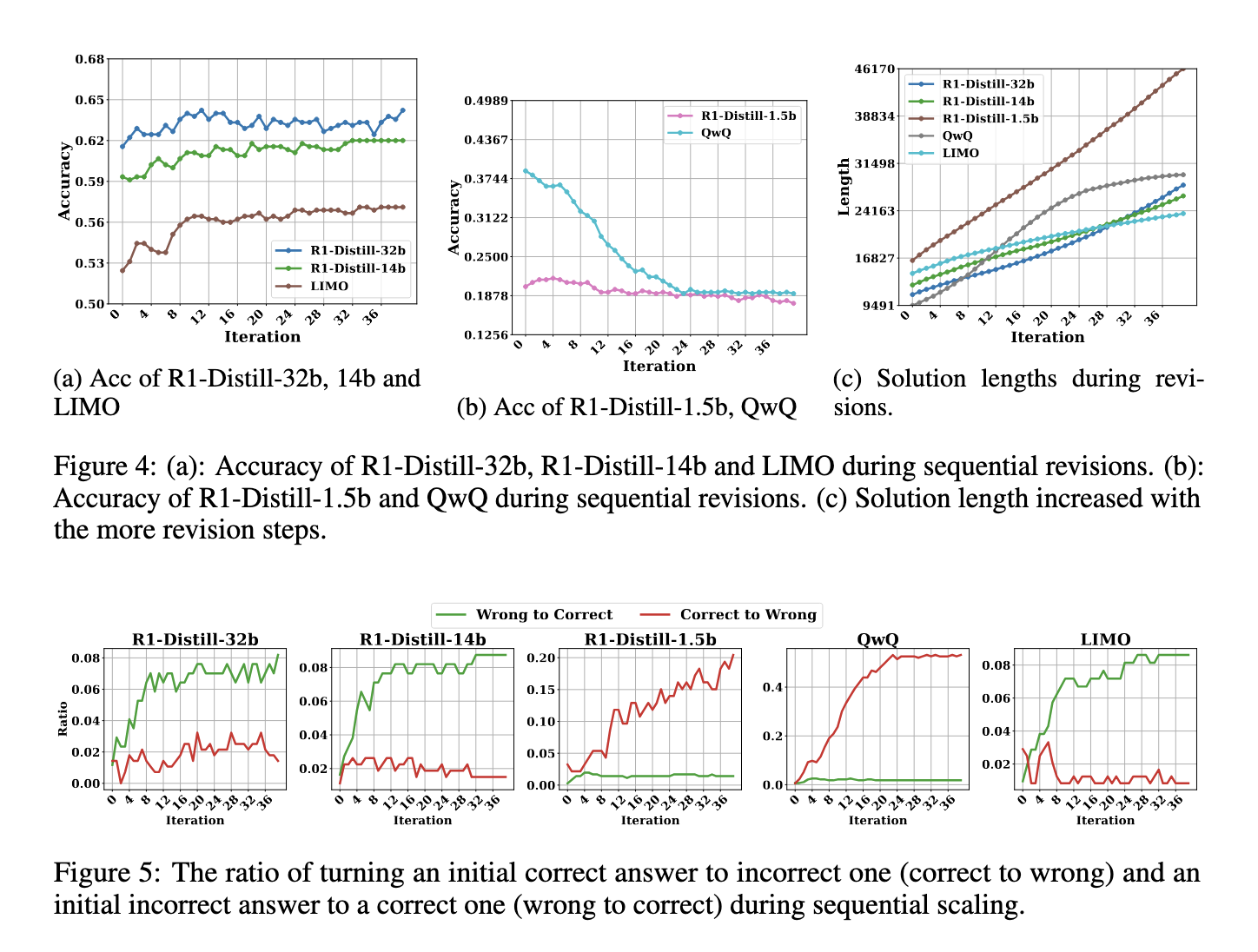
The proposed methodology modifies conventional majority voting by contemplating the quantity and size of options. Typical majority voting selects essentially the most often occurring reply amongst generated options, whereas Shortest Majority Vote assigns greater precedence to solutions that seem usually however are additionally shorter. The reasoning behind this method is that longer options are likely to introduce extra errors attributable to extreme self-revisions. Researchers discovered that QwQ, R1, and LIMO generate more and more longer responses when prompted to refine their options, usually resulting in decrease accuracy. The proposed methodology goals to filter out pointless extensions and prioritize extra exact solutions by integrating size as a criterion.
Experimental evaluations demonstrated that Shortest Majority Vote methodology considerably outperformed conventional majority voting throughout a number of benchmarks. On the AIME dataset, fashions incorporating this system confirmed a rise in accuracy in comparison with present test-time scaling approaches. As an example, accuracy enhancements have been noticed in R1-Distill-32b, which reached 72.88% in comparison with typical strategies. Equally, QwQ and LIMO additionally exhibited enhanced efficiency, significantly in instances the place prolonged reasoning chains beforehand led to inconsistencies. These findings recommend that the idea that longer options at all times yield higher outcomes is flawed. As a substitute, a structured and environment friendly method that prioritizes conciseness can result in superior efficiency.
The outcomes additionally revealed that sequential scaling suffers from diminishing returns. Whereas preliminary revisions could contribute to improved responses, extreme revisions usually introduce errors fairly than correcting them. Particularly, fashions like QwQ and R1-Distill-1.5b tended to vary right solutions into incorrect ones fairly than enhancing accuracy. This phenomenon additional highlights the restrictions of sequential scaling, reinforcing the argument {that a} extra structured method, reminiscent of Shortest Majority Vote, is important for optimizing test-time scaling.
The analysis underscores the necessity to rethink how test-time scaling is utilized in massive language fashions. Somewhat than assuming that extending reasoning chains results in higher accuracy, the findings display that prioritizing concise, high-quality options by parallel scaling is a more practical technique. The introduction of Shortest Majority Vote offers a sensible and empirically validated enchancment over present strategies, providing a refined method to optimizing computational effectivity in LLMs. By specializing in structured reasoning fairly than extreme self-revision, this methodology paves the best way for extra dependable and correct AI-driven decision-making.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 75k+ ML SubReddit.
🚨 Beneficial Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Handle Authorized Issues in AI Datasets
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
