By processing advanced knowledge codecs, deep studying has remodeled numerous domains, together with finance, healthcare, and e-commerce. Nevertheless, making use of deep studying fashions to tabular knowledge, characterised by rows and columns, poses distinctive challenges. Whereas deep studying has excelled in picture and textual content evaluation, traditional machine studying methods comparable to gradient-boosted resolution timber nonetheless dominate tabular knowledge as a result of their reliability and interpretability. Researchers are exploring new architectures that may successfully adapt deep studying methods for tabular knowledge with out sacrificing accuracy or effectivity.
One vital problem in making use of deep studying to tabular knowledge is balancing mannequin complexity and computational effectivity. Conventional machine studying strategies, notably gradient-boosted resolution timber, ship constant efficiency throughout various datasets. In distinction, deep studying fashions endure from overfitting and require in depth computational sources, making them much less sensible for a lot of real-world datasets. Moreover, tabular knowledge reveals assorted constructions and distributions, making it difficult for deep studying fashions to generalize nicely. Thus, the necessity arises for a mannequin that achieves excessive accuracy and stays environment friendly throughout various datasets.
Present strategies for tabular knowledge in deep studying embrace multilayer perceptrons (MLPs), transformers, and retrieval-based fashions. Whereas MLPs are easy and computationally mild, they typically fail to seize advanced interactions inside tabular knowledge. Extra superior architectures like transformers and retrieval-based strategies introduce mechanisms comparable to consideration layers to boost function interplay. Nevertheless, these approaches typically require vital computational sources, making them impractical for giant datasets and limiting their widespread software. This hole in deep studying for tabular knowledge led to exploring different, extra environment friendly architectures.
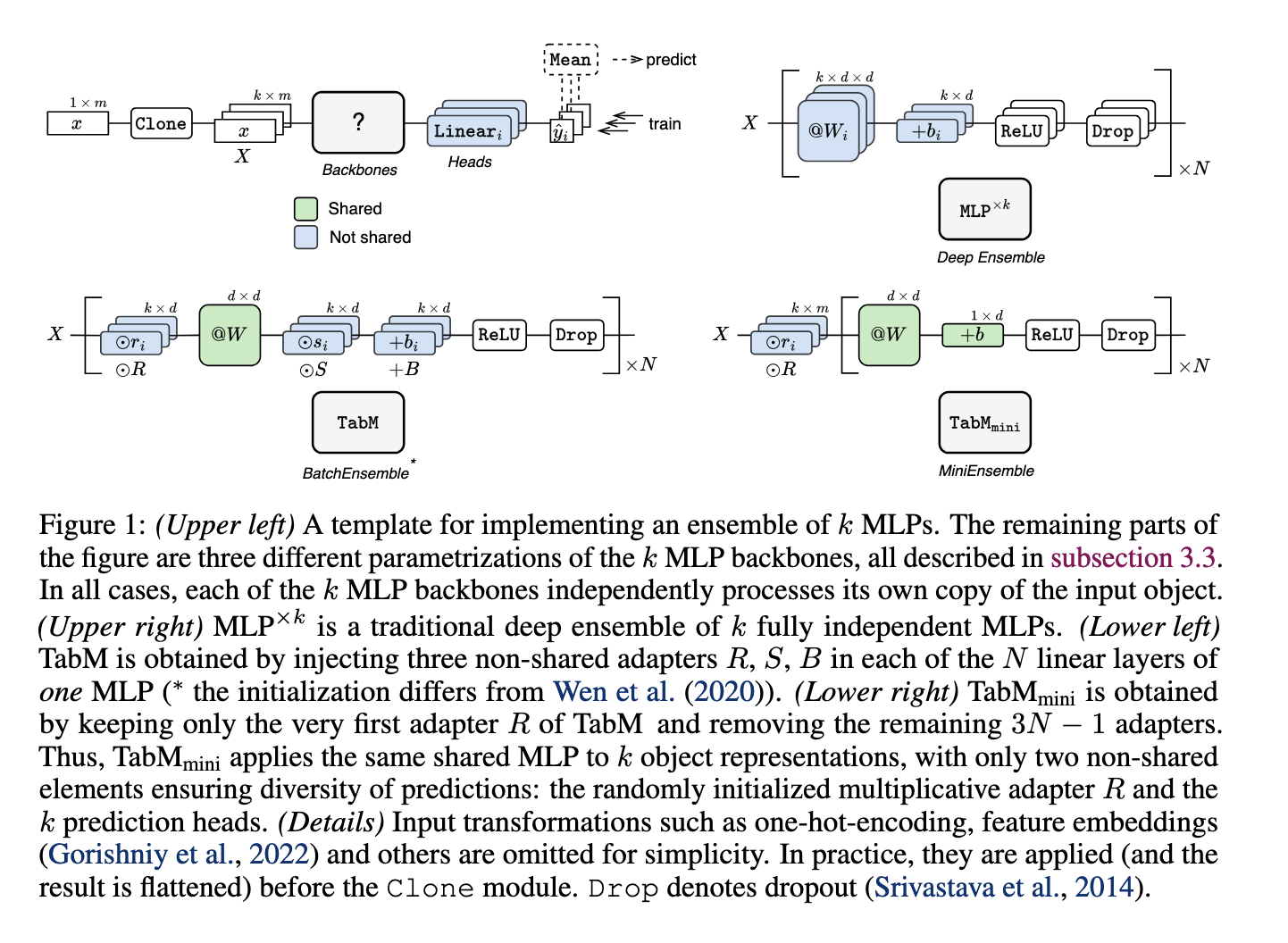
Researchers from Yandex and HSE College launched a mannequin named TabM, constructed upon an MLP basis however enhanced with BatchEnsemble for parameter-efficient ensembling. This mannequin generates a number of predictions inside a single construction by sharing most of its weights amongst ensemble members, permitting it to supply various, weakly correlated predictions. By combining simplicity with efficient ensembling, TabM balances effectivity and efficiency, aiming to outperform conventional MLP fashions with out the complexity of transformer architectures. TabM affords a sensible resolution, offering benefits for deep studying with out the extreme useful resource calls for sometimes related to superior fashions.
The methodology behind TabM leverages BatchEnsemble to maximise prediction variety and accuracy whereas sustaining computational effectivity. Every ensemble member makes use of distinctive weights, often known as adapters, to create a spread of predictions. TabM generates sturdy outputs by averaging these predictions, mitigating overfitting, and bettering generalization throughout various datasets. The researchers’ method combines MLP simplicity with environment friendly ensembling, making a balanced mannequin structure that enhances predictive accuracy and is much less susceptible to widespread tabular knowledge pitfalls. TabM’s environment friendly design permits it to realize excessive accuracy on advanced datasets with out the heavy computational calls for of transformer-based strategies.
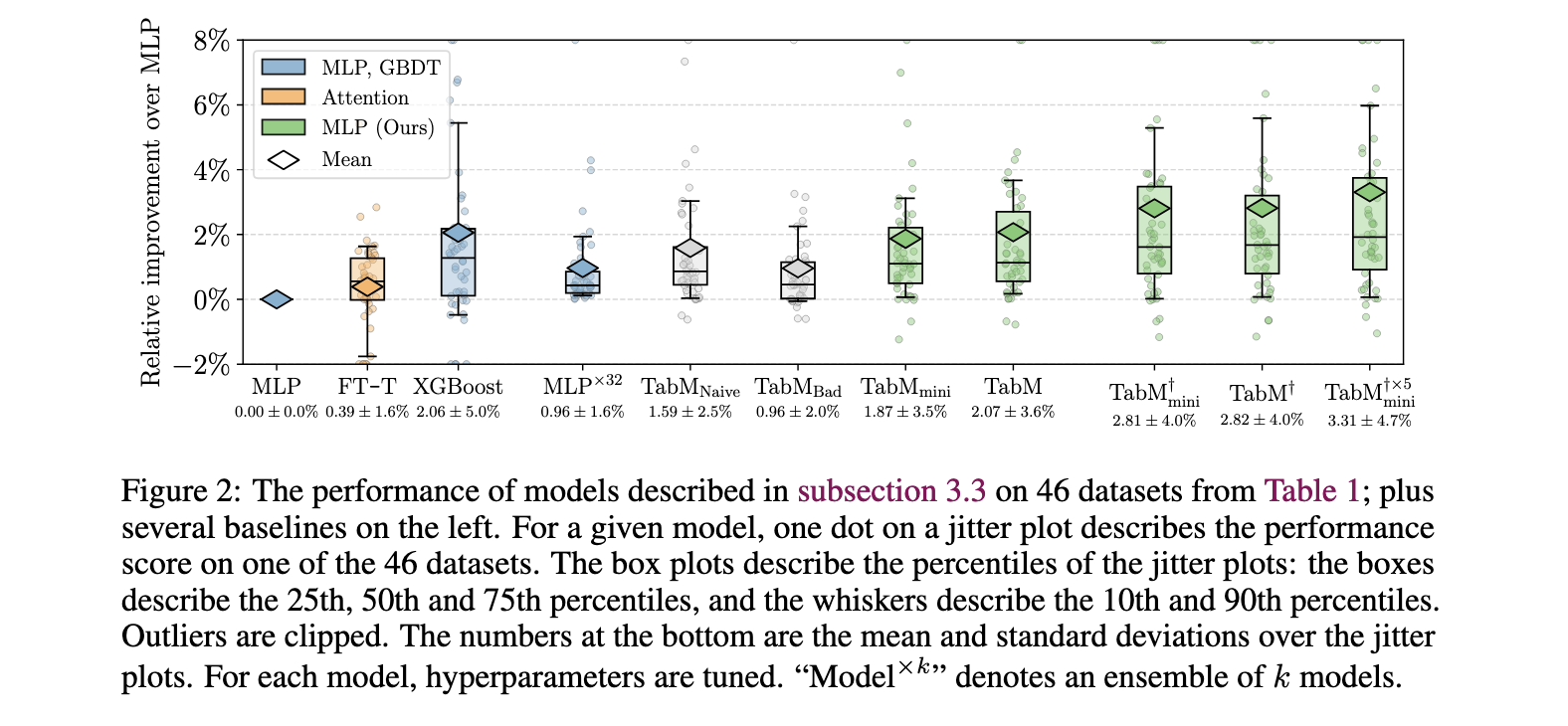
Empirical evaluations reveal TabM’s sturdy efficiency throughout 46 public datasets, displaying a mean enchancment of roughly 2.07% over commonplace MLP fashions. Particularly, on domain-aware splits—representing extra advanced, real-world situations—TabM outperformed many different deep studying fashions, proving its robustness. TabM showcased environment friendly processing capabilities on giant datasets, managing datasets with as much as 6.5 million objects on the Maps Routing dataset inside quarter-hour. For classification duties, TabM utilized the ROC-AUC metric, reaching constant accuracy. On the similar time, Root Imply Squared Error (RMSE) was employed for regression duties, demonstrating the mannequin’s capability to generalize successfully throughout numerous process sorts.
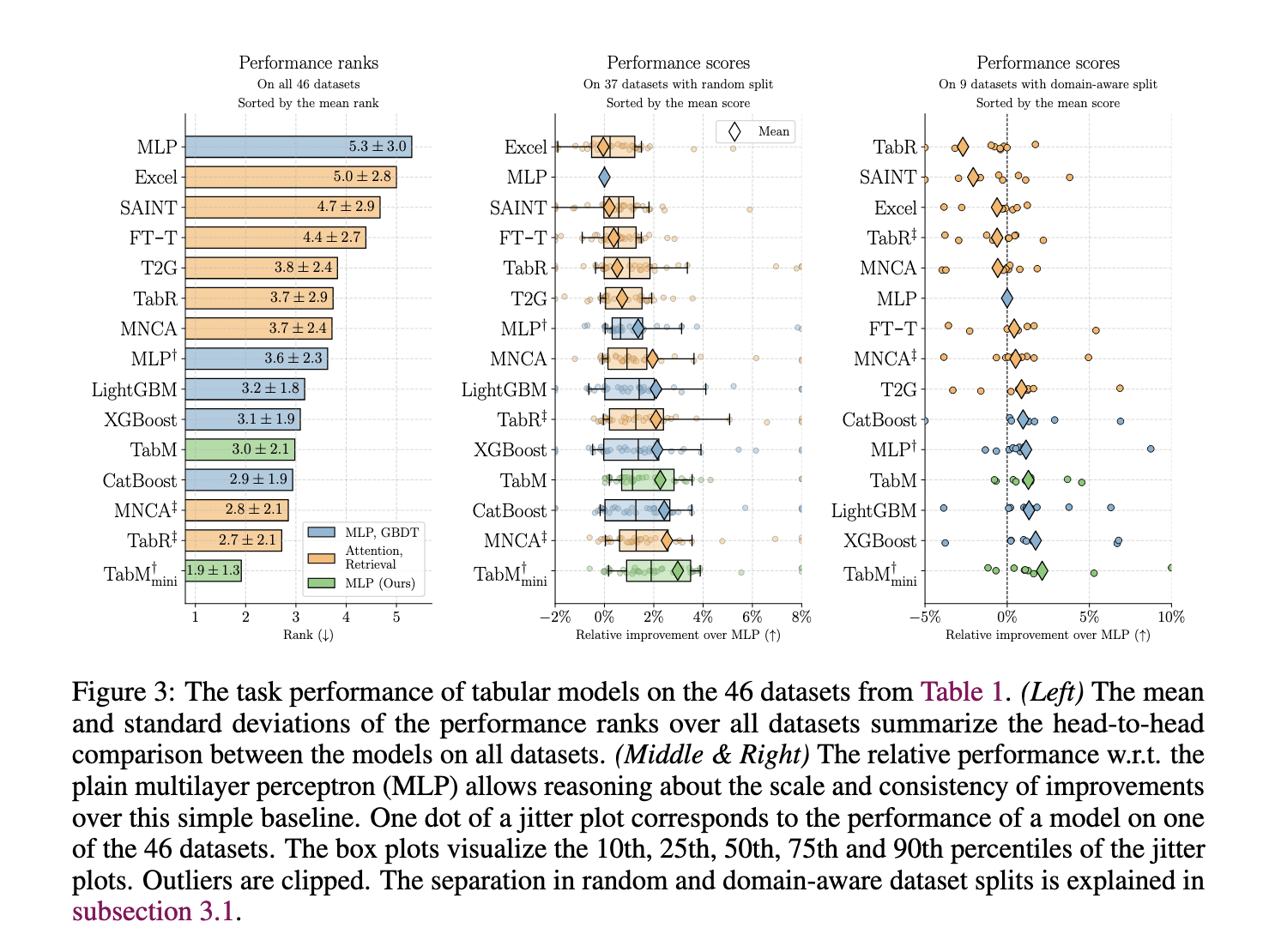
The research presents a major development in making use of deep studying to tabular knowledge, merging MLP effectivity with an modern ensembling technique that optimizes computational calls for and accuracy. By addressing the restrictions of earlier fashions, TabM supplies an accessible and dependable resolution that meets the wants of practitioners dealing with various tabular knowledge sorts. As an alternative choice to conventional gradient-boosted resolution timber and sophisticated neural architectures, TabM represents a useful growth, providing a streamlined, high-performing mannequin able to effectively processing real-world tabular datasets.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.