Giant Language Fashions (LLMs) have gained important significance as productiveness instruments, with open-source fashions more and more matching the efficiency of their closed-source counterparts. These fashions function by way of Subsequent Token Prediction, the place tokens are predicted in sequence when computing consideration is between every token and its predecessors. Key-value (KV) pairs are cached to stop redundant calculations and optimize this course of. Nevertheless, the growing reminiscence necessities for caching pose substantial limitations, notably evident in fashions like LLaMA-65B, which requires over 86GB of GPU reminiscence to retailer 512K tokens with 8-bit key-value quantization, exceeding even high-capacity GPUs just like the H100-80GB.
Current approaches have emerged to deal with the reminiscence footprint challenges of KV cache in LLMs, every having its personal benefits and downsides. Linear consideration strategies like Linear Transformer, RWKV, and Mamba present linear scaling with sequence size. Dynamic token pruning approaches similar to LazyLLM, A2SF, and SnapKV take away much less vital tokens, whereas head dimension discount methods like SliceGPT and Sheared give attention to lowering consideration heads. Strategies for sharing KV representations throughout layers, together with YONO and MiniCache, and quantization methods like GPTQ and KVQuant, try to optimize reminiscence utilization. Nevertheless, these approaches constantly face trade-offs between computational effectivity and mannequin efficiency, typically sacrificing important info or consideration patterns.
Researchers from Peking College, and Xiaomi Corp., Beijing have proposed TransMLA, a post-training technique that converts broadly used GQA-based pre-trained fashions into MLA-based fashions. Their analysis offers theoretical proof that Multi-Layer Consideration (MLA) delivers superior expressive energy in comparison with Grouped-Question Consideration (GQA) whereas sustaining the identical KV Cache overhead. The staff has efficiently transformed a number of outstanding GQA-based fashions, together with LLaMA-3, Qwen-2.5, Mistral, Mixtral, Gemma-2, and Phi-4, into equal MLA fashions. This transformation goals to revolutionize mainstream LLM consideration design by providing a resource-efficient migration technique that improves mannequin efficiency whereas lowering computational prices and environmental affect.
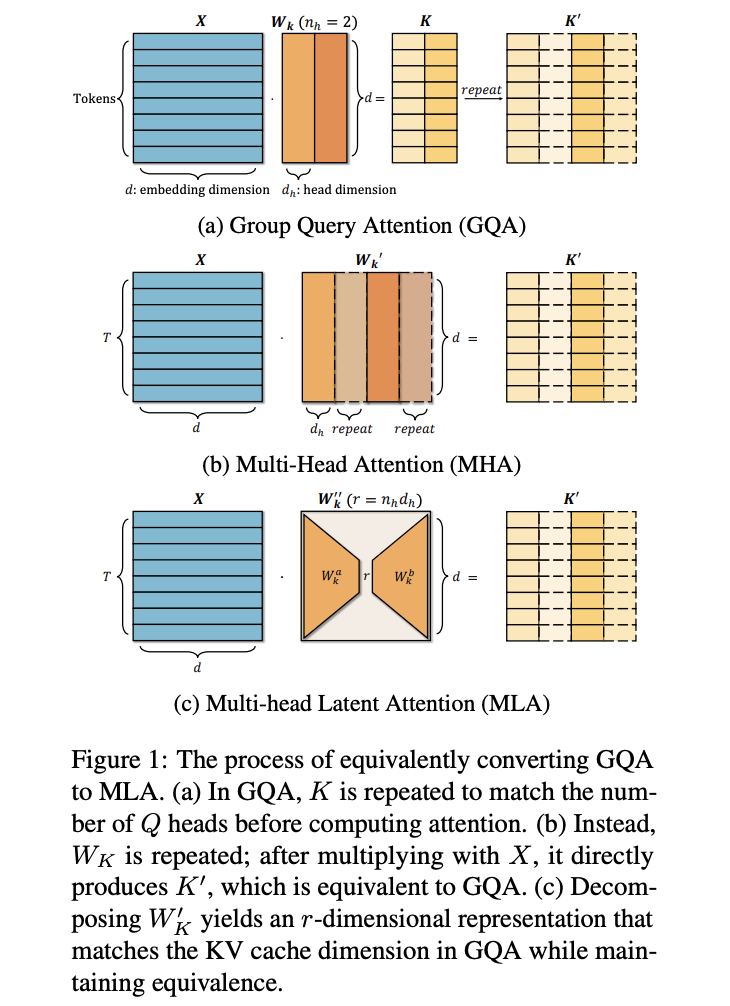
The transformation from GQA to MLA fashions is proven utilizing the Qwen2.5 framework. Within the unique Qwen2.5-7B mannequin, every layer accommodates 28 question heads and 4 key/worth heads, with particular person head dimensions of 128 and a KV cache dimension of 1024. The conversion to MLA entails adjusting the output dimensions of two weight matrices to 512 whereas sustaining the KV cache dimension at 1024. The important thing innovation lies within the TransMLA method, which tasks the load matrix dimensions from 512 to 3584, enabling all 28 question heads to work together with distinct queries. This transformation considerably enhances the mannequin’s expressive energy whereas protecting the KV cache dimension fixed and including solely a modest 12.5% improve in parameters for each QK and V-O pairs.
The efficiency analysis of the TransMLA mannequin reveals important enhancements over the unique GQA-based structure. Utilizing the SmolTalk instruction fine-tuning dataset, the TransMLA mannequin achieves decrease coaching loss, indicating enhanced knowledge becoming capabilities. Efficiency enhancements are seen largely in math and code duties throughout each 7B and 14B mannequin configurations. The analysis investigated the supply of those enhancements by way of managed experiments. When testing with easy dimensionality enlargement utilizing identification map initialization with out orthogonal decomposition on the GSM8K dataset, the advance is minimal (0.15%), confirming that the substantial efficiency beneficial properties come from the mixture of enlarged KV dimensions and orthogonal decomposition.
In conclusion, researchers current a major development in LLM structure by introducing TransMLA, an method to transform used GQA-based pre-trained fashions into MLA-based fashions. The theoretical proofs and empirical validation set up the profitable transformation with enhanced efficiency traits. This work bridges a essential hole between GQA and MLA architectures in current analysis by way of complete theoretical and experimental comparisons. Furthermore, Future developments can give attention to extending this transformation method to main large-scale fashions like LLaMA, Qwen, and Mistral, with extra optimization by way of DeepSeek R1 distillation methods to enhance mannequin efficiency.
Try the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 75k+ ML SubReddit.

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a give attention to understanding the affect of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.