Massive language fashions have pushed progress in machine translation, leveraging large coaching corpora to translate dozens of languages and dialects whereas capturing refined linguistic nuances. But, fine-tuning these fashions for translation accuracy typically impairs their instruction-following and conversational expertise, and broad-purpose variations wrestle to satisfy skilled constancy requirements. Balancing exact, culturally conscious translations with the power to deal with code era, problem-solving, and user-specific formatting stays difficult. Fashions should additionally protect terminological consistency and cling to formatting tips throughout diverse audiences. Stakeholders require methods that may dynamically adapt to area necessities and person preferences with out sacrificing fluency. Benchmark scores reminiscent of WMT24++, overlaying 55 language variants, and IFEval’s 541 instruction-focused prompts spotlight the hole between specialised translation high quality and general-purpose versatility, posing a important bottleneck for enterprise deployment.
Present Approaches to Tailoring Language Fashions for Translation Accuracy
A number of approaches have been explored to tailor language fashions for translation. Tremendous-tuning pre-trained massive language fashions on parallel corpora has been used to enhance the adequacy and fluency of translated textual content. In the meantime, continued pretraining on a mix of monolingual and parallel knowledge enhances multilingual fluency. Some analysis groups have supplemented coaching with reinforcement studying from human suggestions to align outputs with high quality preferences. Proprietary methods reminiscent of GPT-4o and Claude 3.7 have demonstrated main translation high quality, and open-weight diversifications together with TOWER V2 and GEMMA 2 fashions have reached parity or surpassed closed-source fashions below sure language eventualities. These methods mirror steady efforts to handle the twin calls for of translation accuracy and broad language capabilities.
Introducing TOWER+: Unified Coaching for Translation and Common Language Duties
Researchers from Unbabel, Instituto de Telecomunicações, Instituto Superior Técnico, Universidade de Lisboa (Lisbon ELLIS Unit), and MICS, CentraleSupélec, Université Paris-Saclay, launched TOWER+, a set of fashions. The analysis workforce designed variants at a number of parameter scales, 2 billion, 9 billion, and 72 billion, to discover the trade-off between translation specialization and general-purpose utility. By implementing a unified coaching pipeline, the researchers aimed to place TOWER+ fashions on the Pareto frontier, reaching each excessive translation efficiency and strong normal capabilities with out sacrificing one for the opposite. The strategy leverages architectures to steadiness the precise calls for of machine translation with the flexibleness required by conversational and educational duties, supporting a variety of utility eventualities.
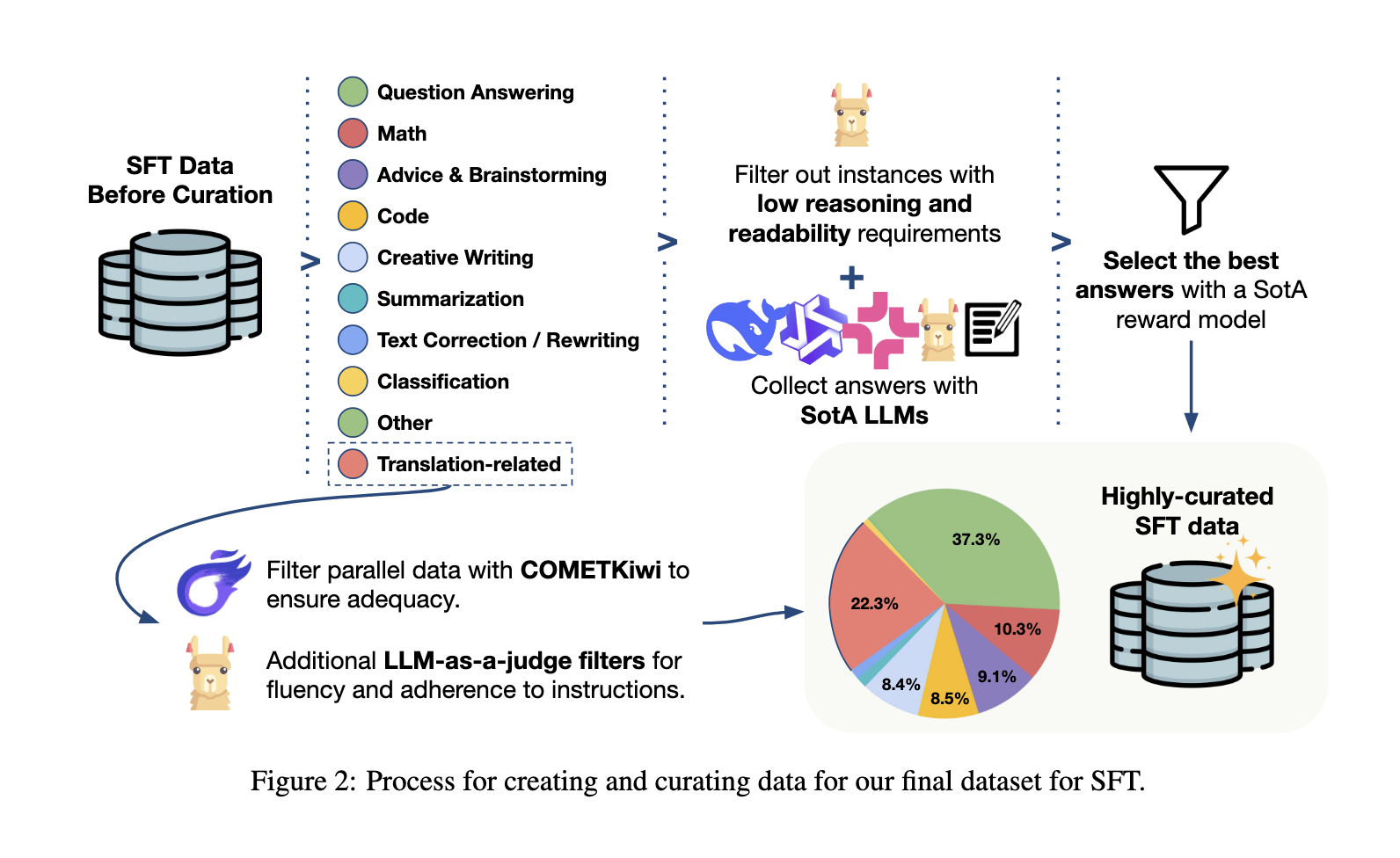
TOWER+ Coaching Pipeline: Pretraining, Supervised Tuning, Preferences, and RL
The coaching pipeline begins with continued pretraining on rigorously curated knowledge that features monolingual content material, filtered parallel sentences formatted as translation directions, and a small fraction of instruction-like examples. Subsequent, supervised fine-tuning refines the mannequin utilizing a mix of translation duties and numerous instruction-following eventualities, together with code era, mathematical problem-solving, and question-answering. A choice optimization stage follows, using weighted choice optimization and group-relative coverage updates skilled on off-policy indicators and human-edited translation variants. Lastly, reinforcement studying with verifiable rewards reinforces exact compliance with transformation tips, utilizing regex-based checks and choice annotations to refine the mannequin’s skill to comply with specific directions throughout translation. This mixture of pretraining, supervised alignment, and reward-driven updates yields a strong steadiness between specialised translation accuracy and versatile language proficiency.
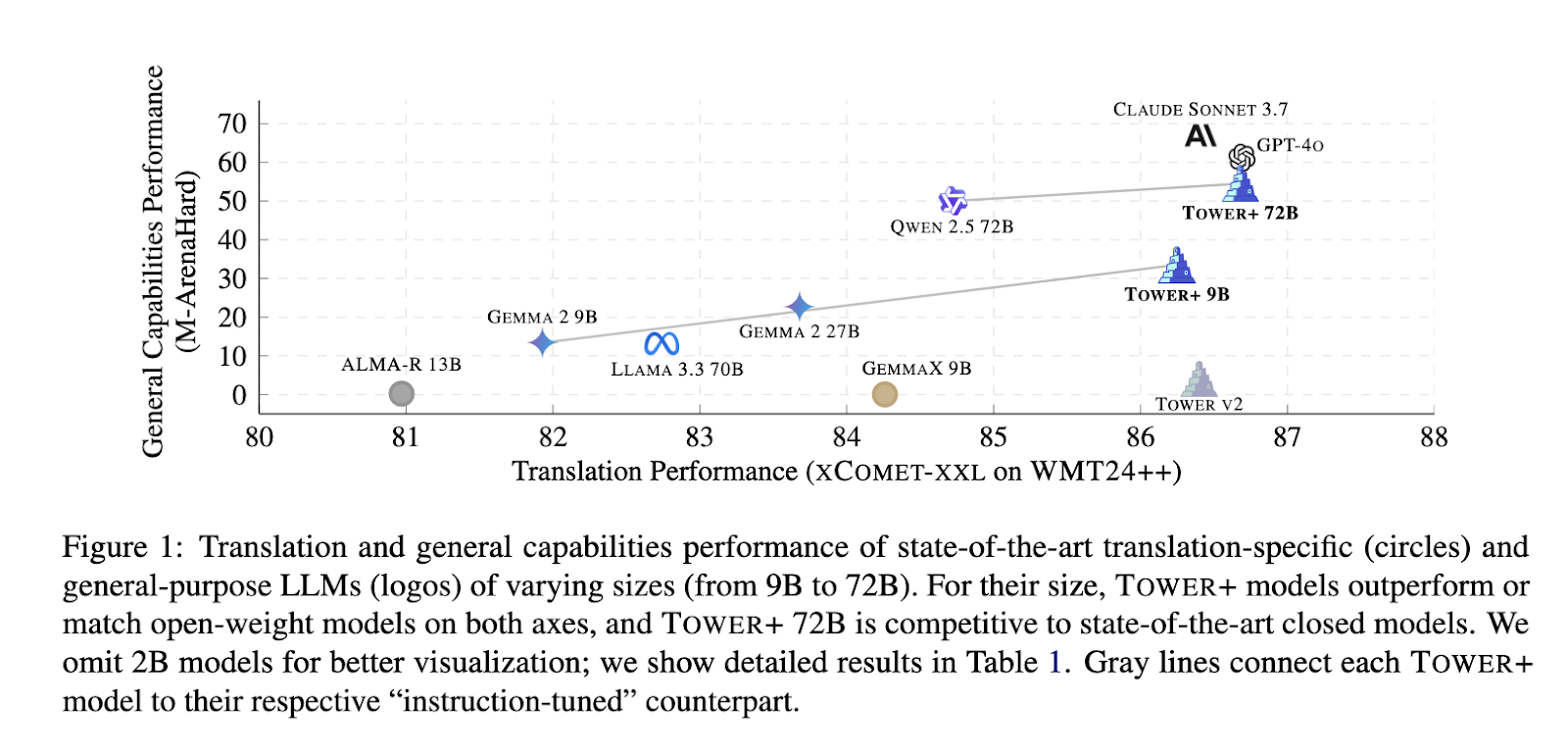
Benchmark Outcomes: TOWER+ Achieves State-of-the-Artwork Translation and Instruction Following
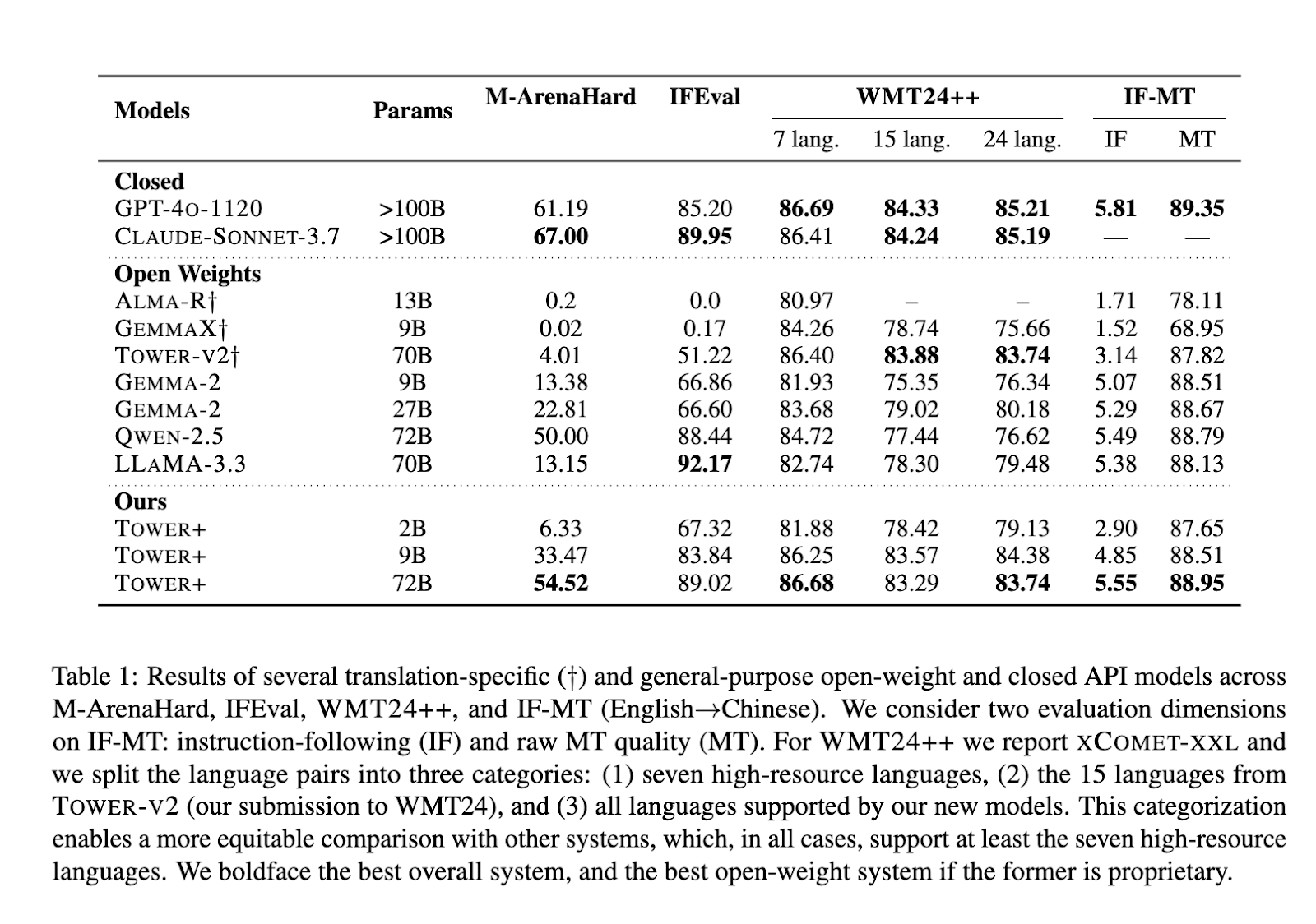
The TOWER+ 9B mannequin achieved a win charge of 33.47% on multilingual normal chat prompts, whereas incomes an XCOMET-XXL rating of 84.38 throughout 24 language pairs, outperforming equally sized open-weight counterparts. The flagship 72 billion-parameter variant secured a 54.52 % win charge on M-ArenaHard, recorded an IFEval instruction-following rating of 89.02, and reached an XCOMET-XXL stage of 83.29 on the complete WMT24++ benchmark. On the mixed translation and instruction-following benchmark, IF-MT scored 5.55 for instruction adherence and 88.95 for translation constancy, establishing state-of-the-art outcomes amongst open-weight fashions. These outcomes affirm that the researchers’ integrative pipeline successfully bridges the hole between specialised translation efficiency and broad language capabilities, demonstrating its viability for each enterprise and analysis purposes.
Key Technical Highlights of the TOWER+ Fashions
- TOWER+ fashions, developed by Unbabel and tutorial companions, span 2 B, 9 B, and 72 B parameters to discover the efficiency frontier between translation specialization and general-purpose utility.
- The post-training pipeline integrates 4 levels: continued pretraining (66% monolingual, 33% parallel, and 1% instruction), supervised fine-tuning (22.3% translation), Weighted Choice Optimization, and verifiable reinforcement studying, to protect chat expertise whereas enhancing translation accuracy.
- Continued pretraining covers 27 languages and dialects, in addition to 47 language pairs, over 32 billion tokens, merging specialised and normal checkpoints to take care of steadiness.
- The 9 B variant achieved a 33.47% win charge on M-ArenaHard, 83.84% on IFEval, and an 84.38% XCOMET-XXL throughout 24 pairs, with IF-MT scores of 4.85 (instruction) and 88.51 (translation).
- The 72 B mannequin recorded 54.52% M-ArenaHard, 89.02% IFEval, 83.29% XCOMET-XXL, and 5.55/88.95% IF-MT, setting a brand new open-weight customary.
- Even the 2B mannequin matched bigger baselines, with 6.33% on M-ArenaHard and 87.65% IF-MT translation high quality.
- Benchmarked in opposition to GPT-4O-1120, Claude-Sonnet-3.7, ALMA-R, GEMMA-2, and LLAMA-3.3, the TOWER+ suite persistently matches or outperforms on each specialised and normal duties.
- The analysis gives a reproducible recipe for constructing LLMs that serve translation and conversational wants concurrently, lowering mannequin proliferation and operational overhead.
Conclusion: A Pareto-Optimum Framework for Future Translation-Centered LLMs
In conclusion, by unifying large-scale pretraining with specialised alignment levels, TOWER+ demonstrates that translation excellence and conversational versatility can coexist inside a single open-weight suite. The fashions obtain a Pareto-optimal steadiness throughout translation constancy, instruction-following, and normal chat capabilities, providing a scalable blueprint for future domain-specific LLM growth.
Try the Paper and Models. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.
