Deep neural networks’ seemingly anomalous generalization behaviors, benign overfitting, double descent, and profitable overparametrization are neither distinctive to neural networks nor inherently mysterious. These phenomena will be understood by established frameworks like PAC-Bayes and countable speculation bounds. A researcher from New York College presents “mushy inductive biases” as a key unifying precept in explaining these phenomena: fairly than proscribing speculation house, this method embraces flexibility whereas sustaining a desire for easier options in keeping with knowledge. This precept applies throughout numerous mannequin courses, exhibiting that deep studying isn’t basically completely different from different approaches. Nonetheless, deep studying stays distinctive in particular points.
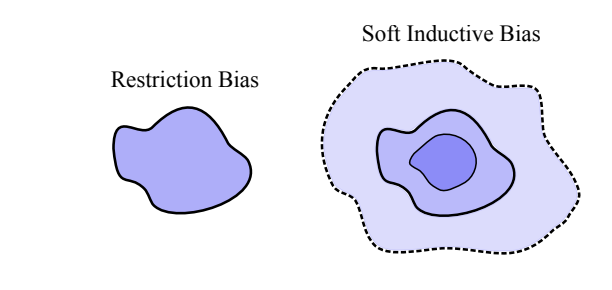
Inductive biases historically operate as restriction biases that constrain speculation house to enhance generalization, permitting knowledge to get rid of inappropriate options. Convolutional neural networks exemplify this method by imposing laborious constraints like locality and translation equivariance on MLPs by parameter elimination and sharing. Delicate inductive biases symbolize a broader precept the place sure options are most popular with out eliminating alternate options that match the info equally effectively. Not like restriction biases with their laborious constraints, mushy biases information fairly than restrict the speculation house. These biases affect the coaching course of by mechanisms like regularization and Bayesian priors over parameters.
Embracing versatile speculation areas has complicated real-world knowledge buildings however requires prior bias towards sure options to make sure good generalization. Regardless of difficult typical knowledge round overfitting and metrics like Rademacher complexity, phenomena like overparametrization align with the intuitive understanding of generalization. These phenomena will be characterised by long-established frameworks, together with PAC-Bayes and countable speculation bounds. The idea of efficient dimensionality supplies extra instinct for understanding behaviors. Frameworks which have formed typical generalization knowledge usually fail to clarify these phenomena, highlighting the worth of established various strategies for understanding trendy machine studying‘s generalization properties.
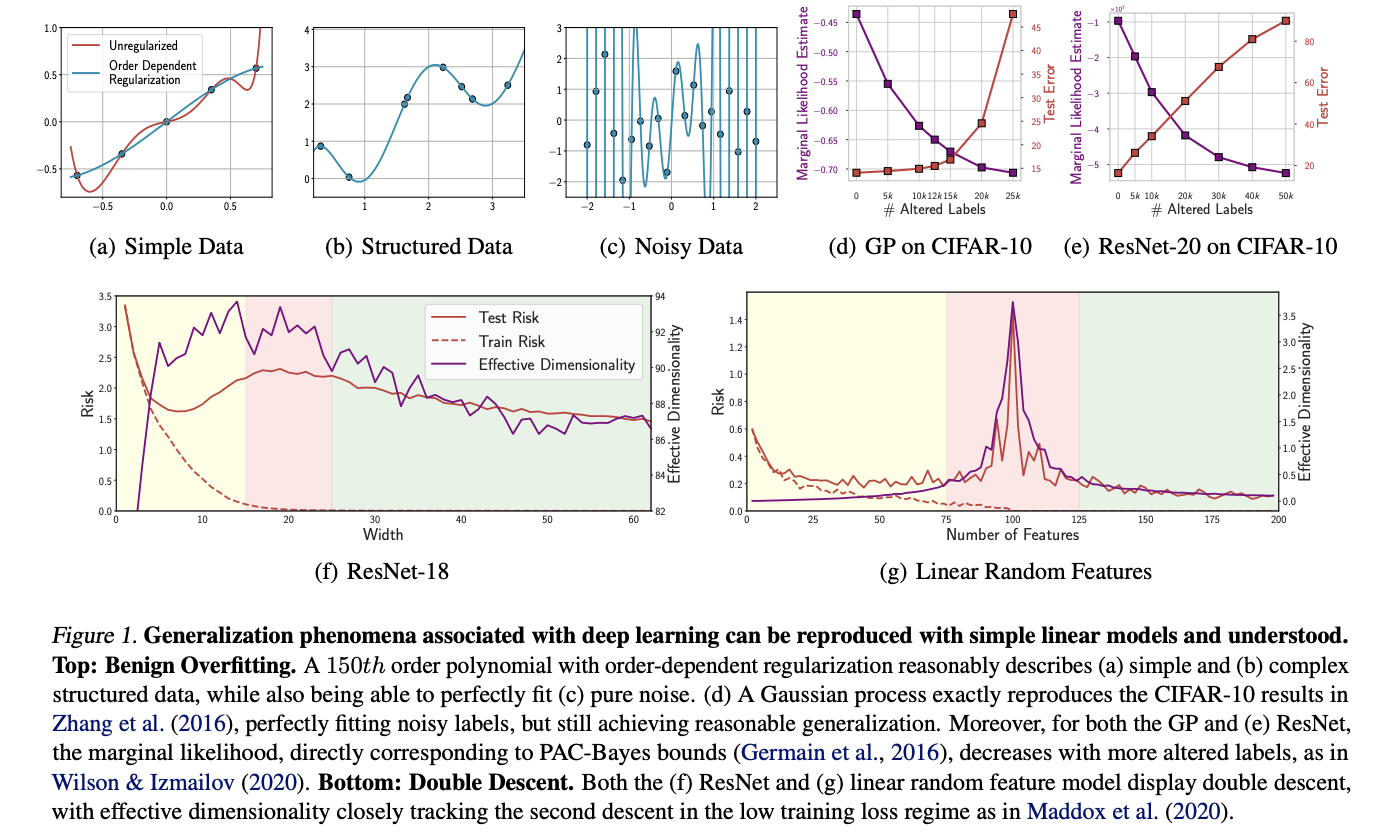
Benign overfitting describes fashions’ skill to completely match noise whereas nonetheless generalizing effectively on structured knowledge, exhibiting that capability for overfitting doesn’t essentially result in poor generalization on significant issues. Convolutional neural networks may match random picture labels whereas sustaining robust efficiency on structured picture recognition duties. This conduct contradicts established generalization frameworks like VC dimension and Rademacher complexity, with the authors claiming no current formal measure may clarify these fashions’ simplicity regardless of their huge measurement. One other definition for benign overfitting is described as “one of many key mysteries uncovered by deep studying.” Nonetheless, this isn’t distinctive to neural networks, as it may be reproduced throughout numerous mannequin courses.
Double descent refers to a generalization error that decreases, will increase, after which decreases once more as mannequin parameters improve. The preliminary sample follows the “classical regime” the place fashions seize helpful construction however ultimately overfit. The second descent happens within the “trendy interpolating regime” after coaching loss approaches zero. Double descent is proven for a ResNet-18 and a linear mannequin. For the ResNet, cross-entropy loss is seen on CIFAR-100 because the width of every layer will increase. As layer width will increase within the ResNet or parameters improve within the linear mannequin, each observe related patterns: Efficient dimensionality rises till it reaches the interpolation threshold, then decreases as generalization improves. This phenomenon will be formally tracked utilizing PAC-Bayes bounds.
In conclusion, Overparametrization, benign overfitting, and double descent symbolize intriguing phenomena deserving continued examine. Nonetheless, opposite to widespread beliefs, these behaviors align with established generalization frameworks, will be reproduced in non-neural fashions, and will be intuitively understood. This understanding ought to bridge various analysis communities, stopping priceless views and frameworks from being ignored. Different phenomena like grokking and scaling legal guidelines aren’t introduced as proof for rethinking generalization frameworks or as neural network-specific. Current analysis confirms that these phenomena apply to linear fashions. Furthermore, PAC-Bayes and countable speculation bounds stay in keeping with massive language fashions.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.