The CLIP framework has turn out to be foundational in multimodal illustration studying, significantly for duties resembling image-text retrieval. Nonetheless, it faces a number of limitations: a strict 77-token cap on textual content enter, a dual-encoder design that separates picture and textual content processing, and a restricted compositional understanding that resembles bag-of-words fashions. These points hinder its effectiveness in capturing nuanced, instruction-sensitive semantics. Though MLLMs like LLaVA, Qwen2-VL, and CogVLM provide important advances in vision-language reasoning, their autoregressive next-token prediction goal restricts their capability to be taught generalized, transferable embeddings. This has sparked rising curiosity in growing different strategies that may mix the strengths of each contrastive studying and LLM-based reasoning.
Current approaches goal to beat these limitations by using novel architectures and coaching methods. For example, E5-V proposes unimodal contrastive coaching for aligning cross-modal options, whereas VLM2Vec introduces the MMEB benchmark to transform superior vision-language fashions into efficient embedding mills. Fashions like LLM2Vec and NV-Embed improve text-based illustration studying by modifying the eye mechanisms in decoder-only LLMs. Regardless of these improvements, challenges resembling dealing with lengthy sequences, enabling higher cross-modal fusion, and successfully distinguishing arduous negatives in contrastive studying stay. As multimodal purposes develop, there’s a urgent want for illustration studying strategies which can be each scalable and able to fine-grained semantic alignment.
Researchers from establishments together with The College of Sydney, DeepGlint, Tongyi Lab at Alibaba, and Imperial Faculty London introduce UniME, a two-stage framework designed to enhance multimodal illustration studying utilizing MLLMs. The primary stage applies textual discriminative data distillation from a powerful LLM trainer to reinforce the language encoder. The second stage employs arduous adverse enhanced instruction tuning, which entails filtering false negatives and sampling a number of difficult negatives per occasion to enhance the mannequin’s discriminative and instruction-following talents. Evaluations on the MMEB benchmark and varied retrieval duties present that UniME delivers constant and important enhancements in each efficiency and compositional understanding.
The UniME framework introduces a two-stage technique for studying common multimodal embeddings utilizing MLLMs. First, it employs textual discriminative data distillation, the place a scholar MLLM is educated utilizing text-only prompts and supervised by a trainer mannequin to reinforce embedding high quality. Then, a second stage—arduous adverse enhanced instruction tuning—improves cross-modal alignment and job efficiency by filtering false negatives and sampling arduous negatives. This stage additionally leverages task-specific prompts to reinforce instruction-following for varied purposes, resembling retrieval and visible query answering. Collectively, these levels considerably increase UniME’s efficiency on each in- and out-of-distribution duties.
The research evaluated UniME on Phi3.5-V and LLaVA-1.6 utilizing PyTorch with DeepSpeed for environment friendly coaching throughout 8 NVIDIA A100 GPUs. Coaching consisted of two levels: a textual data distillation part utilizing the NLI dataset (273,000 pairs) and a tough adverse instruction tuning part on 662,000 multimodal pairs. NV-Embed V2 served because the trainer mannequin. UniME was evaluated on 36 MMEB benchmark datasets, attaining constant enhancements over baselines resembling E5-V and VLM2Vec. Arduous negatives considerably improved the mannequin’s capability to differentiate refined variations, thereby enhancing its efficiency, significantly in long-caption and compositional retrieval duties. Ablation research confirmed the effectiveness of each coaching levels and tuning parameters.
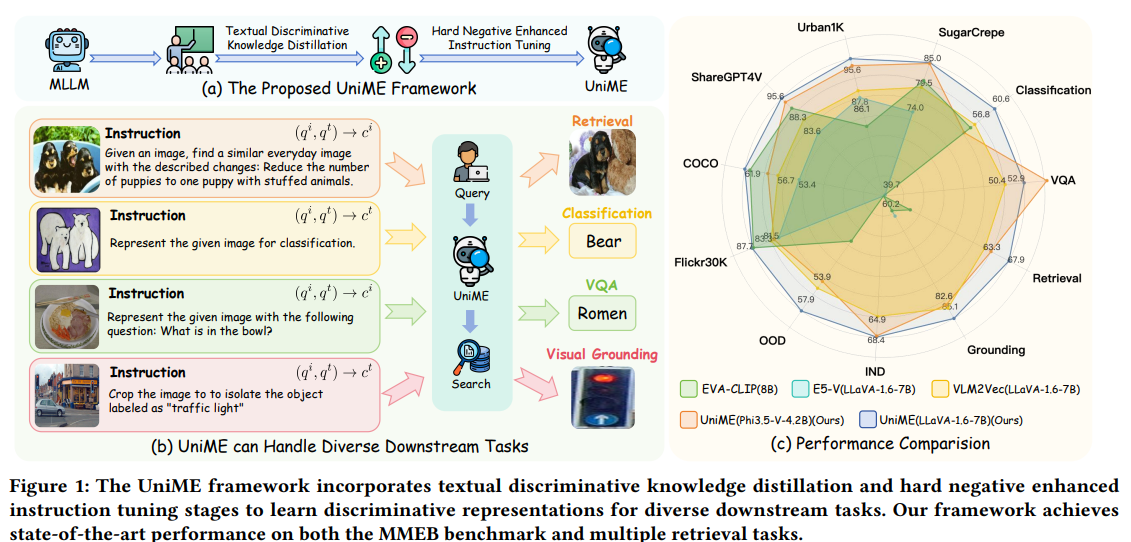
In conclusion, UniME is a two-stage framework designed to enhance multimodal illustration studying utilizing MLLMs. Within the first stage, UniME distills textual discriminative data from a big language mannequin to strengthen the language embeddings of the MLLM. Within the second stage, it enhances studying by way of instruction tuning with a number of arduous negatives per batch, lowering false adverse interference and inspiring the mannequin to differentiate difficult examples. In depth analysis on MMEB and varied retrieval duties demonstrates that UniME persistently boosts efficiency, providing sturdy discriminative and compositional talents throughout duties, thereby surpassing the constraints of prior fashions, resembling CLIP.
Take a look at the Paper and Code. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 90k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
