Massive language fashions (LLMs) have proven outstanding talents in language duties and reasoning, however their capability for autonomous planning—particularly in advanced, multi-step situations—stays restricted. Conventional approaches usually depend on exterior verification instruments or linear prompting strategies, which wrestle with error correction, state monitoring, and computational effectivity. This hole turns into evident in benchmarks like Blocksworld, the place even superior fashions like GPT-4 obtain solely 30% accuracy in comparison with human efficiency of 78%. The core problem lies in enabling LLMs to deal with long-horizon planning with out exterior crutches whereas managing cognitive load and avoiding state hallucinations.
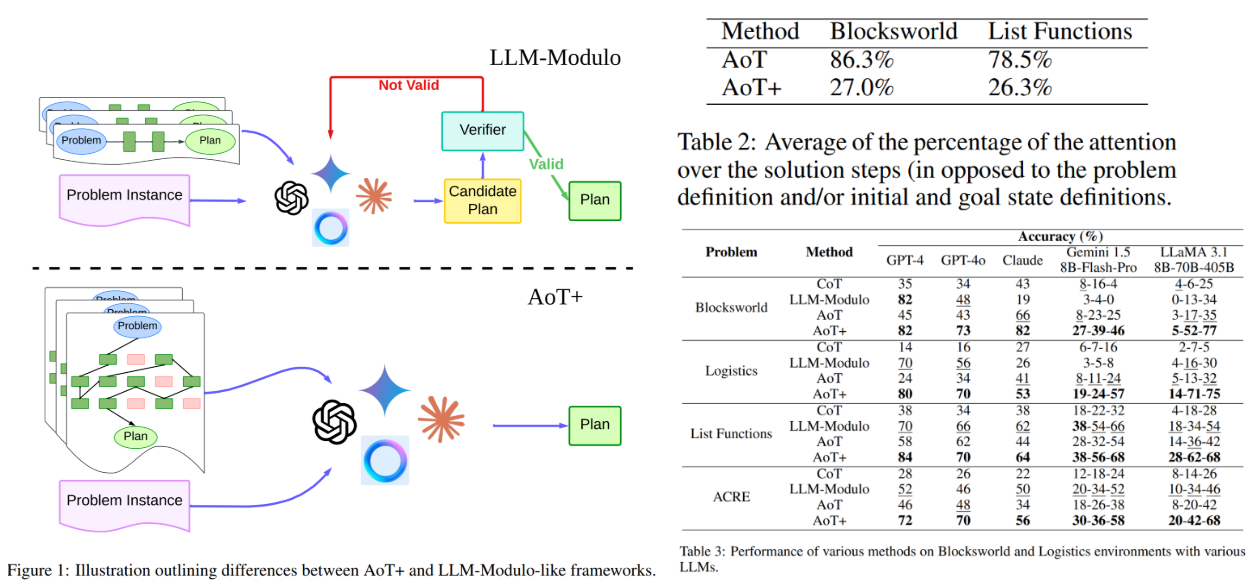
Current strategies like Chain-of-Thought (CoT) prompting encourage step-by-step reasoning however fail in situations requiring backtracking or exploration of other paths. Hybrid frameworks similar to Tree of Ideas (ToT) combine exterior methods to trace states, however they incur excessive computational prices and latency. The Algorithm-of-Ideas (AoT) improved upon CoT by incorporating human-like intuitions and backtracking examples, but it nonetheless suffered from state hallucinations and labor-intensive immediate engineering. These limitations highlighted the necessity for a technique that balances autonomy, effectivity, and accuracy in LLM-based planning.
To deal with these challenges, researchers from Virginia Tech have developed AoT+, an enhanced prompting method that refines the AoT framework. The strategy introduces two key improvements.
- Periodic Structured State Era: It tackles the problem of state hallucinations—the place LLMs lose observe of the issue’s present state throughout multi-step planning. Conventional strategies pressure the mannequin to deduce the state from a prolonged context, which turns into error-prone because the reasoning chain grows. AoT+ addresses this by periodically inserting express state summaries into the reasoning course of. For instance, within the Blocksworld area, the place the purpose is to stack blocks into a selected configuration, the mannequin may begin with the preliminary state: “Block A is on the desk, Block B is on Block C.” After every motion (e.g., “Transfer Block A onto Block B”), AoT+ prompts the LLM to regenerate and restate the up to date state: “Now, Block A is on Block B, Block B stays on Block C, and the desk has Block C.” These summaries act like checkpoints, much like saving progress in a online game. By breaking the issue into smaller, verified states, the mannequin avoids compounding errors and reduces cognitive load. This strategy mimics how people jot down intermediate outcomes throughout advanced calculations to keep away from psychological overload.
- Random Trajectory Augmentation: It addresses the rigidity of human-crafted examples in conventional prompting. As an alternative of relying solely on curated “ultimate” resolution paths, AoT+ injects managed randomness into the search course of. As an example, in a Logistics downside requiring package deal supply throughout cities, a typical immediate may embrace a mixture of profitable and failed trajectories. Right here’s the way it works:
- Instance Development: Begin with one right path (e.g., “Use Truck X to maneuver Package deal P to Airport, then load it onto Aircraft Y to Metropolis Z”) and 4 incorrect ones (e.g., “Truck X takes Package deal P to the mistaken warehouse”).
- Random Interleaving: Mix snippets from each profitable and unsuccessful makes an attempt. For instance:
- Step 1 (right): “Load Package deal P onto Truck X.”
- Step 2 (random incorrect): “Drive Truck X to Warehouse 2 as an alternative of Airport.”
- Step 3 (right): “Unload at Airport and cargo onto Aircraft Y.”
- Guided Finale: Guarantee each instance ends with the proper remaining steps resulting in the purpose.
This forces the LLM to discover various paths whereas retaining give attention to the target. Surprisingly, the randomness doesn’t confuse the mannequin. As an alternative, it acts like a “stress take a look at,” educating the LLM to get well from dead-ends and adapt to surprising situations. The assured right ending acts as a compass, steering the mannequin towards legitimate options even after detours. This technique eliminates the necessity for labor-intensive, human-designed heuristics, making the strategy extra scalable and fewer biased.
By combining state checkpoints with exploratory randomness, AoT+ balances construction and adaptability—like a hiker utilizing a map (periodic states) whereas sometimes taking unmarked trails (random exploration) however at all times understanding the summit’s path (goal-oriented endings). This twin mechanism allows LLMs to plan autonomously with out exterior crutches, addressing each hallucinations and inflexible considering in a single framework.
As for the analysis, AoT+ was rigorously evaluated throughout planning and inductive reasoning benchmarks. In Blocksworld, it achieved 82% accuracy with GPT-4, surpassing each human efficiency (78%) and prior strategies like ToT (69%) and vanilla AoT (45%). For Logistics, a website requiring multi-city package deal transportation planning, AoT+ reached 80% accuracy with GPT-4—a dramatic enchancment over CoT’s 14% and LLM-Modulo’s 70%. The strategy additionally excelled in inductive duties like Listing Capabilities (84% accuracy) and ACRE (72%), demonstrating versatility. Notably, AoT+ maintained effectivity: it used 3x fewer tokens than LLM-Modulo and accomplished duties 6x quicker by avoiding iterative API calls. Smaller fashions like LLaMA-3.1-8B noticed accuracy jumps from 4% to 52% in Blocksworld when utilizing AoT+, proving its scalability. The structured consideration patterns noticed in experiments (Desk 2) confirmed that memoization lowered hallucinations, enabling the mannequin to give attention to decision-making quite than state reconstruction.
In conclusion, AoT+ represents a big leap in autonomous planning for LLMs. By addressing state monitoring by means of memoization and diversifying exploration through random trajectories, it overcomes the linear constraints of CoT and the inefficiencies of hybrid methods. The outcomes problem the notion that LLMs inherently lack planning capabilities, as an alternative exhibiting that tailor-made prompting can unlock latent reasoning expertise. This development not solely elevates efficiency in basic AI benchmarks but in addition opens doorways for real-world functions the place useful resource effectivity and autonomy are crucial. The success of AoT+ underscores the untapped potential of LLMs when guided by cognitively impressed prompting methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Vineet Kumar is a consulting intern at MarktechPost. He’s presently pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s captivated with analysis and the most recent developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.