Multimodal giant language fashions (MLLMs) confirmed spectacular leads to numerous vision-language duties by combining superior auto-regressive language fashions with visible encoders. These fashions generated responses utilizing visible and textual content inputs, with visible options from a picture encoder processed earlier than the textual content embeddings. Nonetheless, there stays an enormous hole in understanding the inside mechanisms behind how such multimodal duties are handled. The lack of know-how of the inside workings of MLLMs limits their interpretability, reduces transparency, and hinders the event of extra environment friendly and dependable fashions.
Earlier research seemed into the interior workings of MLLMs and the way they relate to their exterior behaviors. They targeted on areas like how data is saved within the mannequin, how logit distributions present undesirable content material, how object-related visible data is recognized and adjusted, how security mechanisms are utilized, and the way pointless visible tokens are diminished. Some analysis analyzed how these fashions processed data by analyzing input-output relationships, contributions of various modalities, and tracing predictions to particular inputs, typically treating the fashions as black bins. Different research explored high-level ideas, together with visible semantics and verb understanding. Nonetheless, present fashions wrestle to mix visible and linguistic data to provide correct outcomes successfully.
To unravel this, researchers from the College of Amsterdam, the College of Amsterdam, and the Technical College of Munich proposed a technique that analyzes visible and linguistic data integration inside MLLMs. The researchers primarily targeted on auto-regressive multimodal giant language fashions, which include a picture encoder and a decoder-only language mannequin. Researchers investigated the interplay of visible and linguistic data in multimodal giant language fashions (MLLMs) throughout visible query answering (VQA). The researchers explored how data flowed between the picture and the query by selectively blocking consideration connections between the 2 modalities at numerous mannequin layers. This method, referred to as consideration knockout, was utilized to totally different MLLMs, together with LLaVA-1.5-7b and LLaVA-v1.6-Vicuna-7b, and examined throughout numerous query sorts in VQA.
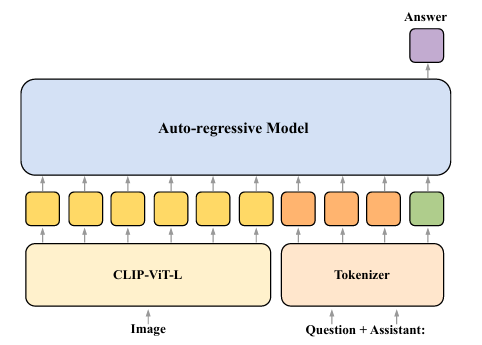
Researchers used knowledge from the GQA dataset to assist visible reasoning and compositional query answering and discover how the mannequin processed and built-in visible and textual data. They targeted on six query classes and used consideration knockout to research how blocking connections between modalities affected the mannequin’s capacity to foretell solutions.
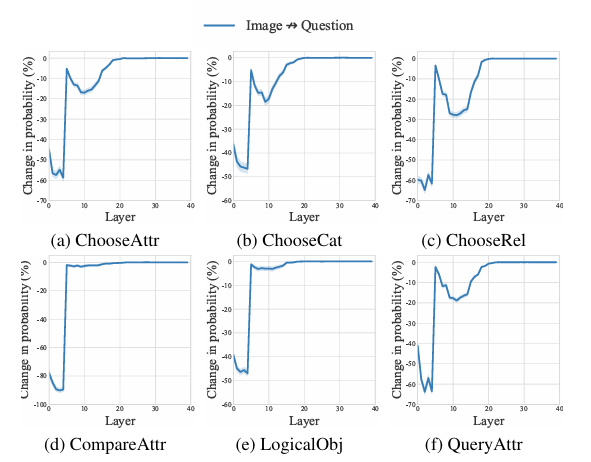
The outcomes present that the query data performed a direct function within the remaining prediction, whereas the picture data had a extra oblique affect. The research additionally confirmed that the mannequin built-in data from the picture in a two-stage course of, with vital modifications noticed within the early and later layers of the mannequin.
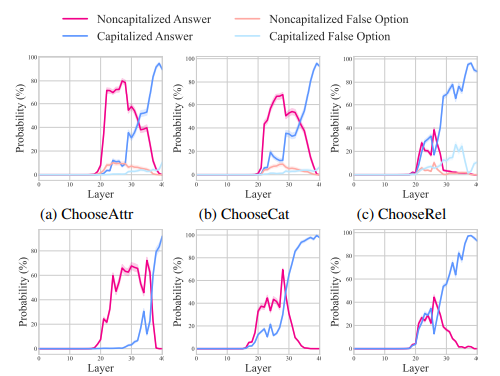
In abstract, the proposed technique reveals that totally different multimodal duties exhibit related processing patterns inside the mannequin. The mannequin combines picture and query data in early layers after which makes use of it for the ultimate prediction in later layers. Solutions are generated in lowercase after which capitalized in larger layers. These findings improve the transparency of such fashions, providing new analysis instructions for higher understanding the interplay of the 2 modalities in MLLMs and may result in improved mannequin designs!
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and remedy challenges.