LLM-Primarily based Code Era Faces a Verification Hole
LLMs have proven robust efficiency in programming and are broadly adopted in instruments like Cursor and GitHub Copilot to spice up developer productiveness. Nevertheless, attributable to their probabilistic nature, LLMs can’t present formal ensures for the code generated. The generated code usually incorporates bugs, and when LLM-based code technology is adopted, these points can turn out to be a productiveness bottleneck. Creating appropriate benchmarks to trace progress in verifiable code technology is essential however difficult, because it entails three interconnected duties: code technology, specification technology, and proof technology. Present benchmarks fall brief, as they lack assist for all three duties, high quality management, strong metrics, and modular design.
Current Benchmarks Lack Complete Help for Verifiability
Benchmarks like HumanEval and MBPP have good progress on LLM-based code technology, however don’t deal with formal specs or proofs. Many verification-focused efforts goal just one or two duties and assume different components to be offered by people. DafnyBench and miniCodeProps are designed for proof technology, whereas AutoSpec and SpecGen infer specs and proofs from human-written code. Interactive theorem-proving methods, corresponding to Lean, present a promising goal for verifiable code technology with LLMs, as they assist the development of proofs with intermediate steps. Nevertheless, current verification benchmarks in Lean, corresponding to miniCodeProps and FVAPPS, have limitations in job protection and high quality management.
Introducing VERINA: A Holistic Benchmark for Code, Spec, and Proof Era
Researchers from the College of California and Meta FAIR have proposed VERINA (Verifiable Code Era Area), a high-quality benchmark to judge verifiable code technology. It consists of 189 programming challenges with detailed drawback descriptions, code, specs, proofs, and take a look at suites, which are formatted in Lean. VERINA is constructed with high quality management, drawing issues from sources corresponding to MBPP, LiveCodeBench, and LeetCode to supply completely different issue ranges. All samples are manually reviewed and refined to make sure clear pure language descriptions, exact formal specs, and correct code implementations. Every pattern incorporates take a look at suites to cowl constructive and unfavorable eventualities, with 100% line protection of the code implementation and passing floor reality specs.
Construction and Composition of the VERINA Dataset
VERINA consists of two subsets with various issue ranges: VERINA-BASIC and VERINA-ADV. VERINA-BASIC incorporates 108 issues translated from human-written Dafny code. This includes 49 issues from MBPP-DFY50 and 59 extra cases from CloverBench, translated utilizing OpenAI o3-mini with few-shot prompting, and adopted by inspection. VERINA-ADV incorporates 81 extra superior coding issues from scholar submissions in a theorem-proving course, the place college students sourced issues from platforms like LeetCode and LiveCodeBench, then formalized options in Lean. Furthermore, VERINA employs rigorous high quality assurance, together with detailed drawback descriptions, full code protection with constructive checks, and full take a look at cross charges on floor reality specs, and so forth.
Efficiency Insights: LLM Analysis on VERINA Highlights Key Challenges
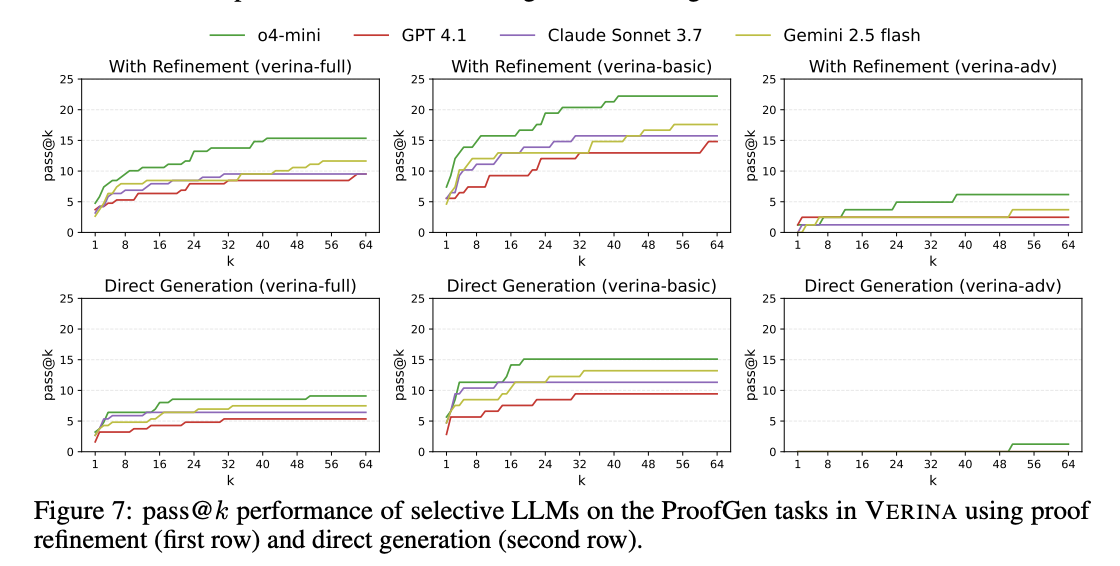
The analysis of 9 state-of-the-art LLMs on VERINA reveals a transparent robust hierarchy. Code technology achieves the best success charges, adopted by specification technology, whereas proof technology stays most difficult, with cross@1 charges beneath 3.6% for all fashions. VERINA-ADV is harder in comparison with VERINA-BASIC in all three duties, highlighting that elevated drawback complexity considerably impacts the efficiency of verifiable code technology. Iterative proof refinement with o4-mini reveals an enchancment from 7.41% to 22.22% for less complicated issues on VERINA-BASIC after 64 iterations, although beneficial properties are restricted on VERINA-ADV. Offering floor reality specs enhances code technology, indicating that formal specs can successfully constrain and direct the synthesis course of.
Conclusion: VERINA Units a New Commonplace in Verifiable Code Analysis
In conclusion, researchers launched VERINA, an development in benchmarking verifiable code technology. It presents 189 rigorously curated examples with detailed job descriptions, high-quality code, specs in Lean, and in depth take a look at suites with full line protection. Nevertheless, the dataset remains to be comparatively small for fine-tuning duties, requiring scaling by way of automated annotation with LLM help. VERINA emphasizes easy, standalone duties appropriate for benchmarking however not totally consultant of complicated real-world verification initiatives. The specification technology metric may very well be improved sooner or later by incorporating extra succesful provers, together with these based mostly on LLMs or SMT solvers to deal with complicated soundness and completeness relationships, successfully.
Try the Paper, Dataset Card, GitHub Page. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter.

Sajjad Ansari is a last yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.
