Growing AI methods that study from their environment throughout execution includes creating fashions that adapt dynamically primarily based on new data. In-Context Reinforcement Studying (ICRL) follows this strategy by permitting AI brokers to study by way of trial and error whereas making choices. Nevertheless, this methodology has important challenges when utilized to advanced environments with numerous duties. It really works successfully in easy circumstances however fails to scale to extra advanced ones since adapting throughout completely different domains relies on how effectively an agent generalizes from previous experiences. These methods fail to work in the actual world with out correct upgrades in present situations and restrict their sensible utility.
At present, pre-training strategies for cross-domain motion fashions comply with two principal approaches. One strategy makes use of all out there knowledge and circumstances insurance policies on return-to-go targets, whereas the opposite depends on professional demonstrations however ignores reward indicators. These strategies wrestle with scaling to numerous duties and complicated environments. The primary strategy relies on predicting future rewards, which turns into unreliable in unpredictable settings. The second strategy focuses on imitating professional actions however lacks adaptability because it doesn’t use real-time suggestions. Each strategies fail to generalize effectively throughout domains, making them much less efficient for real-world functions.
To handle these points, researchers from Dunnolab AI proposed Vintix, a mannequin leveraging Algorithm Distillation for in-context reinforcement studying. In contrast to standard reinforcement studying strategies that depend on pre-trained insurance policies or fine-tuning, Vintix employs a decoder-only transformer for next-action prediction, skilled on studying histories from base RL algorithms. The mannequin incorporates Steady Noise Distillation (ADϵ), the place noise is step by step diminished in motion choice and cross-domain coaching, using knowledge from 87 duties throughout 4 benchmarks: MuJoCo, Meta-World, Bi-DexHands, and Industrial-Benchmark. This allows Vintix to generalize throughout numerous environments whereas refining insurance policies dynamically.
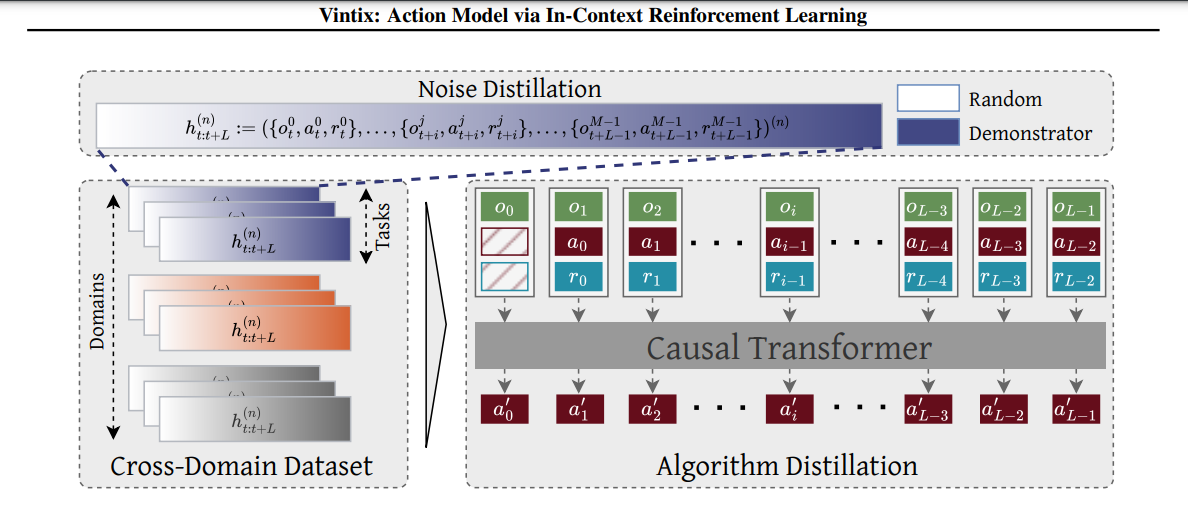
The framework includes a 300M–parameter mannequin with 24 layers and a transformer spine (TinyLLama). It processes enter sequences utilizing an optimized tokenization technique to broaden context size. Coaching is carried out on 8 H100 GPUs, optimizing with MSE loss. At inference, the mannequin begins with out prior context however dynamically self-improves over time. Outcomes demonstrated gradual coverage refinement and powerful cross-domain generalization, highlighting the effectiveness of in-context studying for reinforcement studying duties.
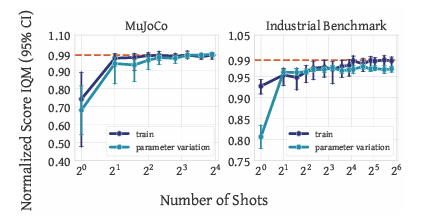
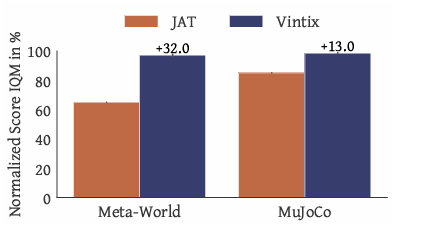
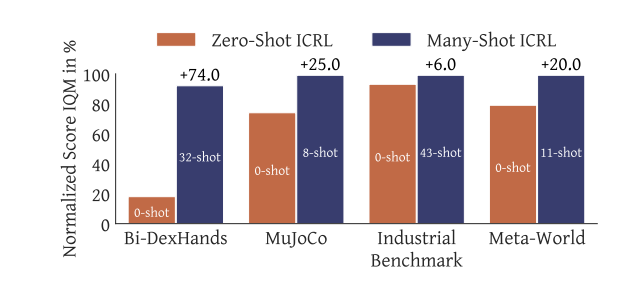
Researchers assessed Vintix’s inference-time self-correction, evaluating it to associated fashions and analyzing generalization. On coaching duties, Vintix improved by way of self-correction, reaching near-demonstrator efficiency. It outperformed JAT by +32.1% in Meta-World and +13.5% in MuJoCo, benefiting from Algorithm Distillation. On unseen parametric variations like viscosity and gravity in MuJoCo and new setpoints in Industrial-Benchmark, near-demonstrator efficiency was maintained however required extra iterations. Nevertheless, in fully new duties, it achieved 47% on Meta-World’s Door-Unlock and 31% on Bi-DexHands’ Door–Open–Inward. Nonetheless, it struggled with Bin-Choosing and Hand-Kettle, highlighting adaptability in acquainted settings however limitations in generalization.
Ultimately, the proposed methodology by researchers utilized In–Context Reinforcement Studying and Algorithm Distillation to boost adaptability throughout domains with out updating gradients at take a look at time. The distillation of steady noise simplified knowledge assortment and allowed for self-correction. Whereas promising, challenges remained in increasing domains and enhancing generalization. This work is usually a baseline for future analysis in scalable, reward-driven reinforcement studying and autonomous decision-making methods.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and resolve challenges.