A brand new paper from Microsoft Analysis and Salesforce finds that even probably the most succesful Massive Language Fashions (LLMs) collapse when directions are given in phases slightly than suddenly. The authors discovered that efficiency drops by a median of 39 % throughout six duties when a immediate is cut up over a number of turns:
A single flip dialog (left) obtains the very best outcomes, however is unnatural for the end-user. A multi-turn dialog (proper) finds even the highest-ranked and most performant LLMs dropping the efficient impetus in a dialog. Supply: https://arxiv.org/pdf/2505.06120
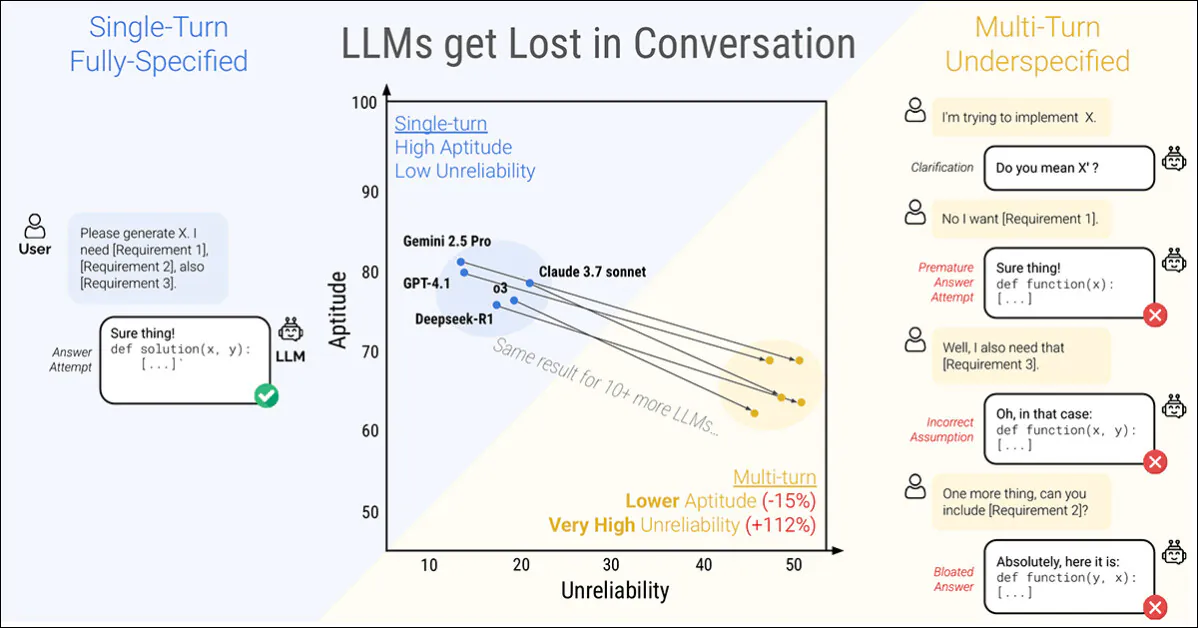
Extra strikingly, the reliability of responses takes a nosedive, with prestigious fashions akin to ChatGPT-4.1 and Gemini 2.5 Professional swinging between near-perfect solutions and manifest failures, relying on how the identical activity is phrased; additional, output consistency can drop by greater than half within the course of.
To discover this habits, the paper introduces a way known as sharding*, which splits fully-specified prompts into smaller fragments and releases them one after the other right into a dialog.
In probably the most primary phrases, that is equal to giving a cohesive and complete single order at a restaurant, leaving the waiter with nothing to do however acknowledge the request; or else deciding to assault the matter collaboratively:

Two excessive variations of a restaurant dialog (not from the brand new paper, for illustrative functions solely).
For emphasis, the instance above maybe places the shopper in a unfavorable mild. However the core concept depicted within the second column is that of a transactional trade that clarifies a problem-set, previous to addressing the issues – apparently a rational and affordable approach of approaching a activity.
This setup is mirrored within the new work’s drip-fed, sharded strategy to LLM interplay. The authors notice that LLMs typically generate overly lengthy responses after which proceed to depend on their very own insights even after these insights have been proven to be incorrect, or irrelevant. This tendency, mixed with different elements, could cause the system to lose monitor of the trade totally.
Actually, the researchers notice what many people have found anecdotally – that one of the best ways to get the dialog again on monitor is to begin a brand new dialog with the LLM.
‘If a dialog with an LLM didn’t result in anticipated outcomes, beginning a brand new dialog that repeats the identical info may yield considerably higher outcomes than persevering with an ongoing dialog.
‘It’s because present LLMs can get misplaced within the dialog, and our experiments present that persisting in a dialog with the mannequin is ineffective. As well as, since LLMs generate textual content with randomness, a brand new dialog might result in improved outcomes.’
The authors acknowledge that agentic programs akin to Autogen or LangChain can doubtlessly enhance the outcomes by performing as interpretative layers between the end-user and the LLM, solely speaking with the LLM once they have gathered sufficient ‘sharded’ responses to coagulate right into a single cohesive question (which the end-user is not going to be uncovered to).
Nonetheless, the authors contend {that a} separate abstraction layer shouldn’t be vital, or else be constructed immediately into the supply LLM:
‘An argument may very well be made that multi-turn capabilities aren’t a vital characteristic of LLMs, as it may be offloaded to the agent framework. In different phrases, do we want native multi-turn help in LLMs when an agent framework can orchestrate interactions with customers and leverage LLMs solely as single-turn operators?…’
However having examined the proposition throughout their array of examples, they conclude:
‘[Relying] on an agent-like framework to course of info is perhaps limiting, and we argue LLMs ought to natively help multi-turn interplay’
This attention-grabbing new paper is titled LLMs Get Misplaced In Multi-Flip Dialog, and comes from 4 researchers throughout MS Analysis and Salesforce,
Fragmented Conversations
The brand new methodology first breaks down typical single-turn directions into smaller shards, designed to be launched at key moments throughout an LLM interplay, a construction that displays the exploratory, back-and-forth fashion of engagement seen in programs akin to ChatGPT or Google Gemini.
Every unique instruction is a single, self-contained immediate that delivers your complete activity in a single go, combining a high-level query, supporting context, and any related circumstances. The sharded model breaks this into a number of smaller components, with every shard including only one piece of data:

Paired directions displaying (a) a whole immediate delivered in a single flip and (b) its sharded model used to simulate an underspecified, multi-turn interplay. Semantically, every model delivers the identical informational payload.
The primary shard all the time introduces the primary purpose of the duty, whereas the remaining present clarifying particulars. Collectively, they ship the identical content material as the unique immediate, however unfold out naturally over a number of turns within the dialog.
Every simulated dialog unfolds between three elements: the assistant, the mannequin below analysis; the person, a simulated agent with entry to the total instruction in sharded kind; and the system, which invigilates and scores the trade.
The dialog begins with the person revealing the primary shard and the assistant replying freely. The system then classifies that response into one in every of a number of classes, akin to a clarification request or a full reply try.
If the mannequin does try a solution, a separate part extracts simply the related span for analysis, ignoring any surrounding textual content. On every new flip, the person reveals one extra shard, prompting one other response. The trade continues till both the mannequin will get the reply proper or there aren’t any shards left to disclose:

Diagram of a sharded dialog simulation, with the evaluated mannequin highlighted in crimson.
Early assessments confirmed that fashions typically requested about info that hadn’t been shared but, so the authors dropped the concept of unveiling shards in a set order. As a substitute, a simulator was used to resolve which shard to disclose subsequent, based mostly on how the dialog was going.
The person simulator, applied utilizing GPT-4o-mini, was due to this fact given full entry to each your complete instruction and the dialog historical past, tasked with deciding, at every flip, which shard to disclose subsequent, based mostly on how the trade was unfolding.
The person simulator additionally rephrased every shard to take care of conversational stream, with out altering the which means. This allowed the simulation to replicate the ‘give-and-take’ of actual dialogue, whereas preserving management over the duty construction.
Earlier than the dialog begins, the assistant is given solely the essential info wanted to finish the duty, akin to a database schema or an API reference. It’s not advised that the directions can be damaged up, and it’s not guided towards any particular approach of dealing with the dialog. That is accomplished on goal: in real-world use, fashions are nearly by no means advised {that a} immediate can be incomplete or up to date over time, and leaving out this context helps the simulation replicate how the mannequin behaves in a extra reasonable context.
GPT-4o-mini was additionally used to resolve how the mannequin’s replies must be labeled, and to drag out any remaining solutions from these replies. This helped the simulation keep versatile, however did introduce occasional errors: nevertheless, after checking a number of hundred conversations by hand, the authors discovered that fewer than 5 % had any issues, and fewer than two % confirmed a change in consequence due to them, and so they thought of this a low sufficient error price inside the parameters of the challenge.
Simulation Eventualities
The authors used 5 forms of simulation to check mannequin habits below completely different circumstances, every a variation on how and when components of the instruction are revealed.
Within the Full setting, the mannequin receives your complete instruction in a single flip. This represents the usual benchmark format and serves because the efficiency baseline.
The Sharded setting breaks the instruction into a number of items and delivers them one after the other, simulating a extra reasonable, underspecified dialog. That is the primary setting used to check how properly fashions deal with multi-turn enter.
Within the Concat setting, the shards are stitched again collectively as a single listing, preserving their wording however eradicating the turn-by-turn construction. This helps isolate the results of conversational fragmentation from rephrasing or content material loss.
The Recap setting runs like Sharded, however provides a remaining flip the place all earlier shards are restated earlier than the mannequin provides a remaining reply. This assessments whether or not a abstract immediate may also help get better misplaced context.
Lastly, Snowball goes additional, by repeating all prior shards on each flip, maintaining the total instruction seen because the dialog unfolds – and providing a extra forgiving take a look at of multi-turn capability.

Simulation sorts based mostly on sharded directions. A totally-specified immediate is cut up into smaller components, which might then be used to simulate both single-turn (Full, Concat) or multi-turn (Sharded, Recap, Snowball) conversations, relying on how shortly the knowledge is revealed.
Duties and Metrics
Six era duties had been chosen to cowl each programming and pure language domains: code era prompts had been taken from HumanEval and LiveCodeBench; Textual content-to-SQL queries had been sourced from Spider; API calls had been constructed utilizing information from the Berkeley Function Calling Leaderboard; elementary math issues had been offered by GSM8K; tabular captioning duties had been based mostly on ToTTo; and Multi-document summaries had been drawn from the Summary of a Haystack dataset.
Mannequin efficiency was measured utilizing three core metrics: common efficiency, aptitude, and unreliability.
Common efficiency captured how properly a mannequin did total throughout a number of makes an attempt; aptitude mirrored the very best outcomes a mannequin might attain, based mostly on its top-scoring outputs; and unreliability measured how a lot these outcomes different, with bigger gaps between finest and worst outcomes indicating much less secure habits.
All scores had been positioned on a 0-100 scale to make sure consistency throughout duties, and metrics computed for every instruction – after which averaged to offer an total image of mannequin efficiency.

Six sharded duties used within the experiments, masking each programming and pure language era. Every activity is proven with a fully-specified instruction and its sharded model. Between 90 and 120 directions had been tailored from established benchmarks for every activity.
Contenders and Checks
Within the preliminary simulations (with an estimated price of $5000), 600 directions spanning six duties had been sharded and used to simulate three dialog sorts: full, concat, and sharded. For every mixture of mannequin, instruction, and simulation kind, ten conversations had been run, producing over 200,000 simulations in whole – a schema that made it potential to seize each total efficiency and deeper measures of aptitude and reliability.
Fifteen fashions had been examined, spanning a variety of suppliers and architectures: the OpenAI fashions GPT-4o (model 2024-11-20), GPT-4o-mini (2024-07-18), GPT-4.1 (2025-04-14), and the considering mannequin o3 (2025-04-16).
Anthropic fashions had been Claude 3 Haiku (2024-03-07) and Claude 3.7 Sonnet (2025-02-19), accessed by way of Amazon Bedrock.
Google contributed Gemini 2.5 Flash (preview-04-17) and Gemini 2.5 Professional (preview-03-25). Meta fashions had been Llama 3.1-8B-Instruct and Llama 3.3-70B-Instruct, in addition to Llama 4 Scout-17B-16E, by way of Collectively AI.
The opposite entries had been OLMo 2 13B, Phi-4, and Command-A, all accessed regionally by way of Ollama or Cohere API; and Deepseek-R1, accessed by means of Amazon Bedrock.
For the 2 ‘considering’ fashions (o3 and R1), token limits had been raised to 10,000 to accommodate longer reasoning chains:

Common efficiency scores for every mannequin throughout six duties: code, database, actions, data-to-text, math, and abstract. Outcomes are proven for 3 simulation sorts: full, concat, and sharded. Fashions are ordered by their common full-setting rating. Shading displays the diploma of efficiency drop from the total setting, with the ultimate two columns reporting common declines for concat and sharded relative to full.
Concerning these outcomes, the authors state†:
‘At a excessive stage, each mannequin sees its efficiency degrade on each activity when evaluating FULL and SHARDED efficiency, with a median degradation of -39%. We identify this phenomenon Misplaced in Dialog: fashions that obtain stellar (90%+) efficiency within the lab-like setting of fully-specified, single-turn dialog wrestle on the very same duties in a extra reasonable setting when the dialog is underspecified and multi-turn.’
Concat scores averaged 95 % of full, indicating that the efficiency drop within the sharded setting can’t be defined by info loss. Smaller fashions akin to Llama3.1-8B-Instruct, OLMo-2-13B, and Claude 3 Haiku confirmed extra pronounced degradation below concat, suggesting that smaller fashions are usually much less strong to rephrasing than bigger ones.
The authors observe†:
‘Surprisingly, extra performant fashions (Claude 3.7 Sonnet, Gemini 2.5, GPT-4.1) get equally misplaced in dialog in comparison with smaller fashions (Llama3.1-8B-Instruct, Phi-4), with common degradations of 30-40%. That is partly on account of metric definitions. Since smaller fashions obtain decrease absolute scores in FULL, they’ve much less scope for degradation than the higher fashions.
‘Briefly, irrespective of how sturdy an LLM’s single-turn efficiency is, we observe massive efficiency degradations within the multi-turn setting.’
The preliminary take a look at signifies that some fashions held up higher in particular duties: Command-A on Actions, Claude 3.7 Sonnet, and GPT-4.1 on code; and Gemini 2.5 Professional on Knowledge-to-Textual content, indicating that multi-turn capability varies by area. Reasoning fashions akin to o3 and Deepseek-R1 fared no higher total, maybe as a result of their longer replies launched extra assumptions, which tended to confuse the dialog.
Reliability
The connection between aptitude and reliability, clear in single-turn simulations, appeared to collapse below multi-turn circumstances. Whereas aptitude declined solely modestly, unreliability doubled on common. Fashions that had been secure in full-format prompts, akin to GPT-4.1 and Gemini 2.5 Professional, turned simply as erratic as weaker fashions like Llama3.1-8B-Instruct or OLMo-2-13B as soon as the instruction was fragmented.

Overview of aptitude and unreliability as proven in a field plot (a), adopted by reliability outcomes from experiments with fifteen fashions (b), and outcomes from the gradual sharding take a look at the place directions had been cut up into one to eight shards (c).
Mannequin responses typically different by as a lot as 50 factors on the identical activity, even when nothing new was added, suggesting that the drop in efficiency was not on account of an absence of talent, however to the mannequin changing into more and more unstable throughout turns.
The paper states†:
‘[Though] higher fashions are likely to have barely increased multi-turn aptitude, all fashions are likely to have comparable ranges of unreliability. In different phrases, in multi-turn, underspecified settings, all fashions we take a look at exhibit very excessive unreliability, with efficiency degrading 50 % factors on common between the very best and worst simulated run for a set instruction.’
To check whether or not efficiency degradation was tied to the variety of turns, the authors ran a gradual sharding experiment, splitting every instruction into one to eight shards (see right-most column in picture above).
Because the variety of shards elevated, unreliability rose steadily, confirming that even minor will increase in flip rely made fashions extra unstable. Aptitude remained principally unchanged, reinforcing that the problem lies in consistency, not functionality.
Temperature Management
A separate set of experiments examined whether or not unreliability was merely a byproduct of randomness. To do that, the authors different the temperature setting of each the assistant and the person simulator throughout three values: 1.0, 0.5, and 0.0.
In single-turn codecs like full and concat, decreasing the assistant’s temperature considerably improved reliability, chopping variation by as a lot as 80 %; however within the sharded setting, the identical intervention had little impact:

Unreliability scores for various mixtures of assistant and person temperature throughout full, concat, and sharded settings, with decrease values indicating larger response consistency.
Even when each the assistant and the person had been set to zero temperature, unreliability remained excessive, with GPT-4o displaying variation round 30 %, suggesting that the instability seen in multi-turn conversations isn’t just stochastic noise, however a structural weak spot in how fashions deal with fragmented enter.
Implications
The authors write of the implications of their findings at uncommon size on the paper’s conclusion, arguing that sturdy single-turn efficiency doesn’t assure multi-turn reliability, and cautioning in opposition to over-relying on fully-specified benchmarks when evaluating real-world readiness (since such benchmarks masks instability in additional pure, fragmented interactions).
In addition they counsel that unreliability isn’t just a sampling artifact, however a elementary limitation in how present fashions course of evolving enter, and so they counsel that this raises considerations for agent frameworks, which rely on sustained reasoning throughout turns.
Lastly, they argue that multi-turn capability must be handled as a core functionality of LLMs, not one thing offloaded to exterior programs.
The authors notice that their outcomes seemingly underestimate the true scale of the issue, and draw consideration to the perfect circumstances of the take a look at: the person simulator of their setup had full entry to the instruction and will reveal shards in an optimum order, which gave the assistant an unrealistically favorable context (in real-world use, customers typically provide fragmented or ambiguous prompts with out realizing what the mannequin wants to listen to subsequent).
Moreover, the assistant was evaluated instantly after every flip, earlier than the total dialog unfolded, stopping later confusion or self-contradiction from being penalized, which might in any other case worsen efficiency. These selections, whereas vital for experimental management, imply that the reliability gaps noticed in follow are prone to be even larger than these reported.
They conclude:
‘[We] imagine performed simulations signify a benign testing floor for LLM multi-turn capabilities. Due to the overly simplified circumstances of simulation, we imagine the degradation noticed in experiments is almost certainly an underestimate of LLM unreliability, and the way ceaselessly LLMs get misplaced in dialog in real-world settings.‘
Conclusion
Anybody who has spent a major period of time with an LLM will seemingly acknowledge the problems formulated right here, from sensible expertise; and most of us, I think about, have intuitively deserted ‘misplaced’ LLM conversations for contemporary ones, within the hope that the LLM might ‘begin over’ and stop to obsess about materials that got here up in a protracted, winding and more and more infuriating trade.
It is attention-grabbing to notice that throwing extra context on the drawback might not essentially clear up it; and certainly, to look at that the paper raises extra questions than it offers solutions (besides by way of methods to skip round the issue).
* Confusingly, that is unrelated to the conventional meaning of ‘sharding’ in AI.
† Authors’ personal daring emphases.
First printed Monday, Could 12, 2025