The fast development of enormous language fashions (LLMs) has uncovered vital infrastructure challenges in mannequin deployment and communication. As fashions scale in measurement and complexity, they encounter important storage, reminiscence, and community bandwidth bottlenecks. The exponential development of mannequin sizes creates computational and infrastructural strains, significantly in knowledge switch and storage mechanisms. Present fashions like Mistral display the magnitude of those challenges, producing over 40 PBs of transferred info month-to-month and requiring in depth community sources. The storage necessities for mannequin checkpoints and distributed updates can accumulate tons of or hundreds of occasions the unique mannequin measurement.
Present analysis in mannequin compression has developed a number of approaches to scale back mannequin sizes whereas making an attempt to take care of efficiency. 4 major model-compression strategies have emerged: pruning, community structure modification, information distillation, and quantization. Amongst these methods, quantization stays the preferred, intentionally buying and selling accuracy for storage effectivity and computational velocity. These strategies share the purpose of decreasing mannequin complexity, however every method introduces inherent limitations. Pruning can doubtlessly take away vital mannequin info, distillation might not completely seize authentic mannequin nuances, and quantization introduces entropy variations. Researchers have additionally begun exploring hybrid approaches that mix a number of compression methods.
Researchers from IBM Analysis, Tel Aviv College, Boston College, MIT, and Dartmouth School have proposed ZipNN, a lossless compression method particularly designed for neural networks. This technique reveals nice potential in mannequin measurement discount, reaching important house financial savings throughout in style machine studying fashions. ZipNN can compress neural community fashions by as much as 33%, with some cases displaying reductions exceeding 50% of the unique mannequin measurement. When utilized to fashions like Llama 3, ZipNN outperforms vanilla compression methods by over 17%, enhancing compression and decompression speeds by 62%. The strategy has the potential to avoid wasting an ExaByte of community visitors month-to-month from massive mannequin distribution platforms like Hugging Face.
ZipNN’s structure is designed to allow environment friendly, parallel neural community mannequin compression. The implementation is primarily written in C (2000 strains) with Python wrappers (4000 strains), using the Zstd v1.5.6 library and its Huffman implementation. The core methodology revolves round a chunking method that enables unbiased processing of mannequin segments, making it significantly appropriate for GPU architectures with a number of concurrent processing cores. The compression technique operates at two granularity ranges: chunk degree and byte-group degree. To boost consumer expertise, the researchers carried out seamless Hugging Face Transformers library integration, enabling computerized mannequin decompression, metadata updates, and native cache administration with non-compulsory guide compression controls.
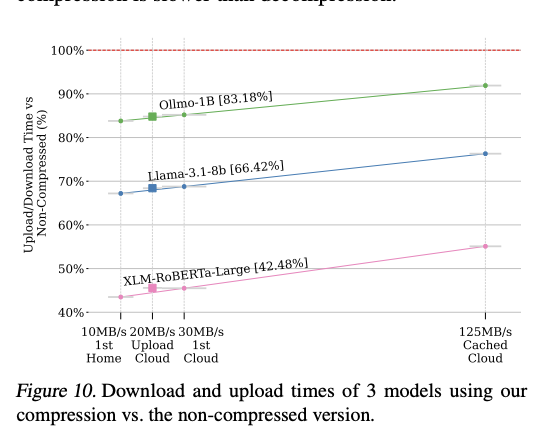
Experimental evaluations of ZipNN have been carried out on an Apple M1 Max machine with 10 cores and 64GB RAM, operating macOS Sonoma 14.3. Mannequin compressibility considerably influenced efficiency variations, with the FP32 common mannequin having roughly 3/4 non-compressible content material, in comparison with 1/2 within the BF16 mannequin and even much less within the clear mannequin. Comparative assessments with LZ4 and Snappy revealed that whereas these alternate options have been quicker, they offered zero compression financial savings. Obtain velocity measurements confirmed fascinating patterns: preliminary downloads ranged from 10-40 MBps, whereas cached downloads exhibited considerably greater speeds of 40-130 MBps, relying on the machine and community infrastructure.
The analysis on ZipNN highlights a vital perception into the modern panorama of machine studying fashions: regardless of exponential development and overparametrization, important inefficiencies persist in mannequin storage and communication. The research reveals substantial redundancies in mannequin architectures that may be systematically addressed by means of focused compression methods. Whereas present developments favor massive fashions, the findings recommend that appreciable house and bandwidth might be saved with out compromising mannequin integrity. By tailoring compression to neural community architectures, enhancements might be achieved with minimal computational overhead, providing an answer to the rising challenges of mannequin scalability and infrastructure effectivity.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our newsletter.. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.